上传文件至 'NEW'
This commit is contained in:
parent
d80e1e55d0
commit
5497ad5308
452
NEW/Kubernetes使用StorageClass动态供应PV.md
Normal file
452
NEW/Kubernetes使用StorageClass动态供应PV.md
Normal file
@ -0,0 +1,452 @@
|
||||
<h1><center>Kubernetes使用StorageClass动态供应PV</center></h1>
|
||||
|
||||
作者:行癫(盗版必究)
|
||||
|
||||
------
|
||||
|
||||
|
||||
|
||||
## 一:安装 NFS 插件
|
||||
|
||||
- GitHub地址:https://github.com/kubernetes-incubator/external-storage/tree/master/nfs/deploy/kubernetes
|
||||
|
||||
|
||||
|
||||
#### 1、配置名称空间
|
||||
|
||||
```shell
|
||||
[root@k8s-master StatefulSet]# ls
|
||||
01-namespace.yaml 03-nfs-provisioner.yaml 05-test-claim.yaml 07-nginx-statefulset.yaml
|
||||
02-rbac.yaml 04-nfs-StorageClass.yaml 06-test-pod.yaml
|
||||
```
|
||||
|
||||
|
||||
|
||||
```shell
|
||||
[root@k8s-master StatefulSet]# cat<<EOF>>01-namespace.yaml
|
||||
apiVersion: v1
|
||||
kind: Namespace
|
||||
metadata:
|
||||
name: dev
|
||||
EOF
|
||||
```
|
||||
|
||||
- 确认信息
|
||||
|
||||
```shell
|
||||
[root@k8s-master StatefulSet]# kubectl get ns
|
||||
NAME STATUS AGE
|
||||
default Active 12d
|
||||
dev Active 60m
|
||||
kube-node-lease Active 12d
|
||||
kube-public Active 12d
|
||||
kube-system Active 12d
|
||||
kubernetes-dashboard Active 12d
|
||||
```
|
||||
|
||||
#### 2、配置授权
|
||||
|
||||
```shell
|
||||
[root@k8s-master StatefulSet]# cat<<EOF>>02-rbac.yaml
|
||||
apiVersion: v1
|
||||
kind: ServiceAccount
|
||||
metadata:
|
||||
name: nfs-client-provisioner
|
||||
# replace with namespace where provisioner is deployed
|
||||
namespace: dev
|
||||
---
|
||||
kind: ClusterRole
|
||||
apiVersion: rbac.authorization.k8s.io/v1
|
||||
metadata:
|
||||
name: nfs-client-provisioner-runner
|
||||
rules:
|
||||
- apiGroups: [""]
|
||||
resources: ["persistentvolumes"]
|
||||
verbs: ["get", "list", "watch", "create", "delete"]
|
||||
- apiGroups: [""]
|
||||
resources: ["persistentvolumeclaims"]
|
||||
verbs: ["get", "list", "watch", "update"]
|
||||
- apiGroups: ["storage.k8s.io"]
|
||||
resources: ["storageclasses"]
|
||||
verbs: ["get", "list", "watch"]
|
||||
- apiGroups: [""]
|
||||
resources: ["events"]
|
||||
verbs: ["create", "update", "patch"]
|
||||
---
|
||||
kind: ClusterRoleBinding
|
||||
apiVersion: rbac.authorization.k8s.io/v1
|
||||
metadata:
|
||||
name: managed-run-nfs-client-provisioner
|
||||
subjects:
|
||||
- kind: ServiceAccount
|
||||
name: nfs-client-provisioner
|
||||
# replace with namespace where provisioner is deployed
|
||||
namespace: dev
|
||||
roleRef:
|
||||
kind: ClusterRole
|
||||
name: nfs-client-provisioner-runner
|
||||
apiGroup: rbac.authorization.k8s.io
|
||||
---
|
||||
kind: Role
|
||||
apiVersion: rbac.authorization.k8s.io/v1
|
||||
metadata:
|
||||
name: leader-locking-nfs-client-provisioner
|
||||
# replace with namespace where provisioner is deployed
|
||||
namespace: dev
|
||||
rules:
|
||||
- apiGroups: [""]
|
||||
resources: ["endpoints"]
|
||||
verbs: ["get", "list", "watch", "create", "update", "patch"]
|
||||
---
|
||||
kind: RoleBinding
|
||||
apiVersion: rbac.authorization.k8s.io/v1
|
||||
metadata:
|
||||
name: leader-locking-nfs-client-provisioner
|
||||
namespace: dev
|
||||
subjects:
|
||||
- kind: ServiceAccount
|
||||
name: nfs-client-provisioner
|
||||
# replace with namespace where provisioner is deployed
|
||||
namespace: dev
|
||||
roleRef:
|
||||
kind: Role
|
||||
name: leader-locking-nfs-client-provisioner
|
||||
apiGroup: rbac.authorization.k8s.io
|
||||
EOF
|
||||
```
|
||||
|
||||
- 部署 rbac.yaml
|
||||
|
||||
```shell
|
||||
[root@k8s-master StatefulSet]# kubectl create -f rbac.yaml
|
||||
```
|
||||
|
||||
- 确认配置
|
||||
|
||||
```shell
|
||||
[root@k8s-master StatefulSet]# kubectl get -n dev clusterrole |grep nfs
|
||||
nfs-client-provisioner-runner 2023-12-13T06:11:25Z
|
||||
[root@k8s-master StatefulSet]# kubectl get -n dev clusterrolebindings.rbac.authorization.k8s.io |grep nfs
|
||||
managed-run-nfs-client-provisioner ClusterRole/nfs-client-provisioner-runner 57m
|
||||
[root@k8s-master StatefulSet]# kubectl get -n dev role
|
||||
NAME CREATED AT
|
||||
leader-locking-nfs-client-provisioner 2023-12-13T06:06:20Z
|
||||
[root@k8s-master StatefulSet]# kubectl get -n dev rolebindings.rbac.authorization.k8s.io
|
||||
NAME ROLE AGE
|
||||
leader-locking-nfs-client-provisioner Role/leader-locking-nfs-client-provisioner 58m
|
||||
```
|
||||
|
||||
#### 3、创建nfs provisioner
|
||||
|
||||
```shell
|
||||
[root@k8s-master StatefulSet]# cat<<EOF>>03-nfs-provisioner.yaml
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
name: nfs-client-provisioner
|
||||
labels:
|
||||
app: nfs-client-provisioner
|
||||
# replace with namespace where provisioner is deployed
|
||||
namespace: dev #与RBAC文件中的namespace保持一致
|
||||
spec:
|
||||
replicas: 1
|
||||
selector:
|
||||
matchLabels:
|
||||
app: nfs-client-provisioner
|
||||
strategy:
|
||||
type: Recreate
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: nfs-client-provisioner
|
||||
spec:
|
||||
serviceAccountName: nfs-client-provisioner
|
||||
containers:
|
||||
- name: nfs-client-provisioner
|
||||
#image: quay.io/external_storage/nfs-client-provisioner:latest
|
||||
image: easzlab/nfs-subdir-external-provisioner:v4.0.1
|
||||
volumeMounts:
|
||||
- name: nfs-client-root
|
||||
mountPath: /persistentvolumes
|
||||
env:
|
||||
- name: PROVISIONER_NAME
|
||||
value: provisioner-nfs-storage #provisioner名称,请确保该名称与 nfs-StorageClass.yaml文件中的provisioner名称保持一致
|
||||
- name: NFS_SERVER
|
||||
value: master01 #NFS Server IP地址
|
||||
- name: NFS_PATH
|
||||
value: /data/volumes/v1 #NFS挂载卷
|
||||
volumes:
|
||||
- name: nfs-client-root
|
||||
nfs:
|
||||
server: master01 #NFS Server IP地址
|
||||
path: /data/volumes/v1 #NFS 挂载卷
|
||||
EOF
|
||||
```
|
||||
|
||||
- 部署deployment-nfs.yaml
|
||||
|
||||
```shell
|
||||
[root@k8s-master StatefulSet]# kubectl apply -f deployment-nfs.yaml
|
||||
```
|
||||
|
||||
- 查看创建的POD
|
||||
|
||||
```shell
|
||||
[root@k8s-master StatefulSet]# kubectl get pods -n dev
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
nfs-client-provisioner-6df46fcf96-qnh64 1/1 Running 0 53m
|
||||
```
|
||||
|
||||
#### 4、创建-StorageClass
|
||||
|
||||
```shell
|
||||
[root@k8s-master StatefulSet]# cat <<EOF>>04-nfs-StorageClass.yaml
|
||||
apiVersion: storage.k8s.io/v1
|
||||
kind: StorageClass
|
||||
metadata:
|
||||
name: managed-nfs-storage
|
||||
namespace: dev
|
||||
provisioner: provisioner-nfs-storage #这里的名称要和provisioner配置文件中的环境变量PROVISIONER_NAME保持一致
|
||||
parameters:
|
||||
archiveOnDelete: "false"
|
||||
EOF
|
||||
```
|
||||
|
||||
- 部署storageclass-nfs.yaml
|
||||
|
||||
```shell
|
||||
[root@k8s-master StatefulSet]# kubectl apply -f storageclass-nfs.yaml
|
||||
```
|
||||
|
||||
- 查看创建的StorageClass
|
||||
|
||||
```shell
|
||||
[root@k8s-master StatefulSet]# kubectl get storageclasses.storage.k8s.io -n dev
|
||||
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
|
||||
managed-nfs-storage provisioner-nfs-storage Delete Immediate false 3h1m
|
||||
```
|
||||
|
||||
#### 5、创建测试pvc
|
||||
|
||||
```shell
|
||||
[root@k8s-master StatefulSet]# cat <<EOF>>05-test-claim.yaml
|
||||
kind: PersistentVolumeClaim
|
||||
apiVersion: v1
|
||||
metadata:
|
||||
name: test-claim
|
||||
namespace: dev
|
||||
## annotations:
|
||||
## volume.beta.kubernetes.io/storage-class: "managed-nfs-storage" # 后期k8s不再支持这个注解,通过声明storageClassName的方式代替
|
||||
spec:
|
||||
accessModes:
|
||||
- ReadWriteMany
|
||||
storageClassName: managed-nfs-storage #与nfs-StorageClass.yaml metadata.name保持一致
|
||||
resources:
|
||||
requests:
|
||||
storage: 5Mi
|
||||
EOF
|
||||
```
|
||||
|
||||
- 创建测试 PVC
|
||||
|
||||
```bash
|
||||
[root@k8s-master StatefulSet]# kubectl create -f test-claim.yaml
|
||||
```
|
||||
|
||||
- 查看创建的PVC状态为Bound
|
||||
|
||||
```shell
|
||||
[root@k8s-master StatefulSet]# kubectl get -n dev pvc
|
||||
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
|
||||
test-claim Bound pvc-a17d9fd5-237a-11e9-a2b5-000c291c25f3 1Mi RWX managed-nfs-storage 34m
|
||||
```
|
||||
|
||||
- 查看自动创建的PV
|
||||
|
||||
```shell
|
||||
[root@k8s-master StatefulSet]# kubectl get -n dev pv
|
||||
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
|
||||
pvc-a17d9fd5-237a-11e9-a2b5-000c291c25f3 1Mi RWX Delete Bound default/test-claim managed-nfs-storage 34m
|
||||
```
|
||||
|
||||
- 进入到NFS的export目录查看对应volume name的目录已经创建出来。
|
||||
|
||||
- 其中volume的名字是namespace,PVC name以及uuid的组合:
|
||||
|
||||
```shell
|
||||
[root@k8s-master StatefulSet]# ls /data/volumes/v1
|
||||
total 0
|
||||
drwxrwxrwx 2 root root 21 Jan 29 12:03 default-test-claim-pvc-a17d9fd5-237a-11e9-a2b5-000c291c25f3
|
||||
```
|
||||
|
||||
#### 6、创建测试pod
|
||||
|
||||
- 指定pod使用刚创建的PVC:test-claim,
|
||||
|
||||
- 完成之后,如果attach到pod中执行一些文件的读写操作,就可以确定pod的/mnt已经使用了NFS的存储服务了。
|
||||
|
||||
```shell
|
||||
[root@k8s-master StatefulSet]# cat<<EOF>>06-test-pod.yaml
|
||||
kind: Pod
|
||||
apiVersion: v1
|
||||
metadata:
|
||||
name: test-pod
|
||||
namespace: dev
|
||||
spec:
|
||||
containers:
|
||||
- name: test-pod
|
||||
image: busybox:1.24
|
||||
command:
|
||||
- "/bin/sh"
|
||||
args:
|
||||
- "-c"
|
||||
- "touch /mnt/SUCCESS && exit 0 || exit 1" #创建一个SUCCESS文件后退出
|
||||
volumeMounts:
|
||||
- name: nfs-pvc
|
||||
mountPath: "/mnt"
|
||||
restartPolicy: "Never"
|
||||
volumes:
|
||||
- name: nfs-pvc
|
||||
persistentVolumeClaim:
|
||||
claimName: test-claim #与PVC名称保持一致
|
||||
EOF
|
||||
```
|
||||
|
||||
- 执行yaml文件
|
||||
|
||||
```bash
|
||||
[root@k8s-master StatefulSet]# kubectl apply -f test-pod.yaml
|
||||
```
|
||||
|
||||
- 查看创建的测试POD
|
||||
|
||||
```swift
|
||||
[root@k8s-master StatefulSet]# kubectl get -n dev pod -o wide
|
||||
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
|
||||
nfs-client-provisioner-75bf876d88-578lg 1/1 Running 0 51m 10.244.2.131 k8s-node2 <none> <none>
|
||||
test-pod 0/1 Completed 0 41m 10.244.1.
|
||||
```
|
||||
|
||||
- 在NFS服务器上的共享目录下的卷子目录中检查创建的NFS PV卷下是否有"SUCCESS" 文件。
|
||||
|
||||
```shell
|
||||
[root@k8s-master StatefulSet]# cd /data/volumes/v1
|
||||
[root@k8s-master v1]# ll
|
||||
total 0
|
||||
drwxrwxrwx 2 root root 21 Jan 29 12:03 default-test-claim-pvc-a17d9fd5-237a-11e9-a2b5-000c291c25f3
|
||||
|
||||
[root@k8s-master v1]# cd default-test-claim-pvc-a17d9fd5-237a-11e9-a2b5-000c291c25f3/
|
||||
[root@k8s-master default-test-claim-pvc-a17d9fd5-237a-11e9-a2b5-000c291c25f3]# ll
|
||||
total 0
|
||||
-rw-r--r-- 1 root root 0 Jan 29 12:03 SUCCESS
|
||||
```
|
||||
|
||||
#### 7、清理测试环境
|
||||
|
||||
- 删除测试POD
|
||||
|
||||
```bash
|
||||
[root@k8s-master StatefulSet]# kubectl delete -f test-pod.yaml
|
||||
```
|
||||
|
||||
- 删除测试PVC
|
||||
|
||||
```bash
|
||||
[root@k8s-master StatefulSet]# kubectl delete -f test-claim.yaml
|
||||
```
|
||||
|
||||
- 在NFS服务器上的共享目录下查看NFS的PV卷已经被删除。
|
||||
|
||||
#### 8、创建一个nginx动态获取PV
|
||||
|
||||
|
||||
```yaml
|
||||
[root@k8s-master StatefulSet]# cat <<EOF>>nginx-statefulset.yaml
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
name: nginx-headless
|
||||
namespace: dev
|
||||
labels:
|
||||
app: nginx
|
||||
spec:
|
||||
ports:
|
||||
- port: 80
|
||||
name: web
|
||||
clusterIP: None #注意此处的值,None表示无头服务
|
||||
selector:
|
||||
app: nginx
|
||||
---
|
||||
apiVersion: apps/v1
|
||||
kind: StatefulSet
|
||||
metadata:
|
||||
name: web
|
||||
namespace: dev
|
||||
spec:
|
||||
selector:
|
||||
matchLabels:
|
||||
app: nginx
|
||||
serviceName: "nginx-headless"
|
||||
replicas: 3 #两个副本
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: nginx
|
||||
spec:
|
||||
containers:
|
||||
- name: nginx
|
||||
image: nginx
|
||||
ports:
|
||||
- containerPort: 80
|
||||
name: web
|
||||
volumeMounts:
|
||||
- name: www
|
||||
mountPath: /usr/share/nginx/html
|
||||
volumeClaimTemplates: # 创建 pvc 模板
|
||||
- metadata:
|
||||
name: www
|
||||
spec:
|
||||
accessModes: [ "ReadWriteOnce" ]
|
||||
storageClassName: "managed-nfs-storage"
|
||||
resources:
|
||||
requests:
|
||||
storage: 1Gi
|
||||
EOF
|
||||
```
|
||||
|
||||
- 启动后看到以下信息:
|
||||
|
||||
```shell
|
||||
[root@k8s-master StatefulSet]# kubectl get -n dev pods,pv,pvc
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
pod/nfs-client-provisioner-5778d56949-ltjbt 1/1 Running 0 42m
|
||||
pod/test-pod 0/1 Completed 0 36m
|
||||
pod/web-0 1/1 Running 0 2m23s
|
||||
pod/web-1 1/1 Running 0 2m6s
|
||||
pod/web-2 1/1 Running 0 104s
|
||||
|
||||
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
|
||||
persistentvolume/pvc-1d54bb5b-9c12-41d5-9295-3d827a20bfa2 1Gi RWO Delete Bound default/www-web-2 managed-nfs-storage 104s
|
||||
persistentvolume/pvc-8cc0ed15-1458-4384-8792-5d4fd65dca66 1Gi RWO Delete Bound default/www-web-0 managed-nfs-storage 39m
|
||||
persistentvolume/pvc-c924a2aa-f844-4d52-96c9-32769eb3f96f 1Mi RWX Delete Bound default/test-claim managed-nfs-storage 38m
|
||||
persistentvolume/pvc-e30333d7-4aed-4700-b381-91a5555ed59f 1Gi RWO Delete Bound default/www-web-1 managed-nfs-storage 2m6s
|
||||
|
||||
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
|
||||
persistentvolumeclaim/test-claim Bound pvc-c924a2aa-f844-4d52-96c9-32769eb3f96f 1Mi RWX managed-nfs-storage 38m
|
||||
persistentvolumeclaim/www-web-0 Bound pvc-8cc0ed15-1458-4384-8792-5d4fd65dca66 1Gi RWO managed-nfs-storage 109m
|
||||
persistentvolumeclaim/www-web-1 Bound pvc-e30333d7-4aed-4700-b381-91a5555ed59f 1Gi RWO managed-nfs-storage 2m6s
|
||||
persistentvolumeclaim/www-web-2 Bound pvc-1d54bb5b-9c12-41d5-9295-3d827a20bfa2 1Gi RWO managed-nfs-storage 104s
|
||||
```
|
||||
|
||||
- nfs服务器上也会看到自动生成3个挂载目录,当pod删除了数据还会存在。
|
||||
|
||||
```shell
|
||||
[root@k8s-master StatefulSet]# ll /data/volumes/v1/
|
||||
total 4
|
||||
drwxrwxrwx 2 root root 6 Aug 16 18:21 default-nginx-web-0-pvc-ea22de1c-fa33-4f82-802c-f04fe3630007
|
||||
drwxrwxrwx 2 root root 21 Aug 16 18:25 default-test-claim-pvc-c924a2aa-f844-4d52-96c9-32769eb3f96f
|
||||
drwxrwxrwx 2 root root 6 Aug 16 18:21 default-www-web-0-pvc-8cc0ed15-1458-4384-8792-5d4fd65dca66
|
||||
drwxrwxrwx 2 root root 6 Aug 16 18:59 default-www-web-1-pvc-e30333d7-4aed-4700-b381-91a5555ed59f
|
||||
drwxrwxrwx 2 root root 6 Aug 16 18:59 default-www-web-2-pvc-1d54bb5b-9c12-41d5-9295-3d827a20bfa2
|
||||
```
|
||||
|
||||
49
NEW/Kubernetes集群中Kubeadm证书到期问题.md
Normal file
49
NEW/Kubernetes集群中Kubeadm证书到期问题.md
Normal file
@ -0,0 +1,49 @@
|
||||
<h1><center>Kubernetes集群中Kubeadm证书到期问题</center></h1>
|
||||
|
||||
作者:行癫(盗版必究)
|
||||
|
||||
------
|
||||
|
||||
## 一:报错案例
|
||||
|
||||
#### 1.报错原因
|
||||
|
||||
```shell
|
||||
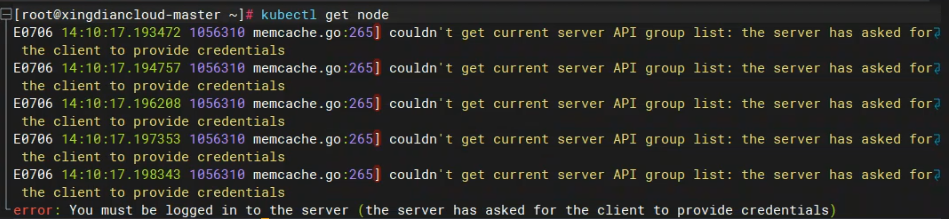
[root@xingdiancloud-master ~]# kubectl get node
|
||||
E0706 14:10:17.193472 1056310 memcache.go:265] couldn't get current server API group list: the server has asked for the client to provide credentials
|
||||
E0706 14:10:17.194757 1056310 memcache.go:265] couldn't get current server API group list: the server has asked for the client to provide credentials
|
||||
E0706 14:10:17.196208 1056310 memcache.go:265] couldn't get current server API group list: the server has asked for the client to provide credentials
|
||||
E0706 14:10:17.197353 1056310 memcache.go:265] couldn't get current server API group list: the server has asked for the client to provide credentials
|
||||
E0706 14:10:17.198343 1056310 memcache.go:265] couldn't get current server API group list: the server has asked for the client to provide credentials
|
||||
error: You must be logged in to the server (the server has asked for the client to provide credentials)
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 2.解决方案
|
||||
|
||||
检查当前证书的到期时间
|
||||
|
||||
```shell
|
||||
kubeadm certs check-expiration
|
||||
```
|
||||
|
||||
更新证书
|
||||
|
||||
```shell
|
||||
kubeadm certs renew all
|
||||
```
|
||||
|
||||
更新 kubeconfig 文件
|
||||
|
||||
```shell
|
||||
sudo cp /etc/kubernetes/admin.conf $HOME/.kube/config
|
||||
sudo chown $(id -u):$(id -g) $HOME/.kube/config
|
||||
```
|
||||
|
||||
更新证书后,需要重启控制平面组件以使新的证书生效
|
||||
|
||||
```shell
|
||||
systemctl restart kubelet
|
||||
```
|
||||
|
||||
204
NEW/kubernetes健康检查机制.md
Normal file
204
NEW/kubernetes健康检查机制.md
Normal file
@ -0,0 +1,204 @@
|
||||
<h1><center>Kubernetes健康检查机制</center></h1>
|
||||
|
||||
著作:行癫 <盗版必究>
|
||||
|
||||
------
|
||||
|
||||
## 一:检查恢复机制
|
||||
|
||||
#### 1.容器健康检查和恢复机制
|
||||
|
||||
在 k8s 中,可以为 Pod 里的容器定义一个健康检查"探针"。kubelet 就会根据这个 Probe 的返回值决定这个容器的状态,而不是直接以容器是否运行作为依据。这种机制,是生产环境中保证应用健康存活的重要手段。
|
||||
|
||||
#### 2.命令模式探针
|
||||
|
||||
```shell
|
||||
apiVersion: v1
|
||||
kind: Pod
|
||||
metadata:
|
||||
labels:
|
||||
test: liveness
|
||||
name: test-liveness-exec
|
||||
spec:
|
||||
containers:
|
||||
- name: liveness
|
||||
image: daocloud.io/library/nginx
|
||||
args:
|
||||
- /bin/sh
|
||||
- -c
|
||||
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
|
||||
livenessProbe:
|
||||
exec:
|
||||
command:
|
||||
- cat
|
||||
- /tmp/healthy
|
||||
initialDelaySeconds: 5
|
||||
periodSeconds: 5
|
||||
```
|
||||
|
||||
它在启动之后做的第一件事是在 /tmp 目录下创建了一个 healthy 文件,以此作为自己已经正常运行的标志。而 30 s 过后,它会把这个文件删除掉
|
||||
|
||||
与此同时,定义了一个这样的 livenessProbe(健康检查)。它的类型是 exec,它会在容器启动后,在容器里面执行一句我们指定的命令,比如:"cat /tmp/healthy"。这时,如果这个文件存在,这条命令的返回值就是 0,Pod 就会认为这个容器不仅已经启动,而且是健康的。这个健康检查,在容器启动 5 s 后开始执行(initialDelaySeconds: 5),每 5 s 执行一次(periodSeconds: 5)
|
||||
|
||||
创建Pod:
|
||||
|
||||
```shell
|
||||
[root@master diandian]# kubectl create -f test-liveness-exec.yaml
|
||||
```
|
||||
|
||||
查看 Pod 的状态:
|
||||
|
||||
```shell
|
||||
[root@master diandian]# kubectl get pod
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
test-liveness-exec 1/1 Running 0 10s
|
||||
```
|
||||
|
||||
由于已经通过了健康检查,这个 Pod 就进入了 Running 状态
|
||||
|
||||
30 s 之后,再查看一下 Pod 的 Events:
|
||||
|
||||
```shell
|
||||
[root@master diandian]# kubectl describe pod test-liveness-exec
|
||||
```
|
||||
|
||||
发现,这个 Pod 在 Events 报告了一个异常:
|
||||
|
||||
```shell
|
||||
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
|
||||
--------- -------- ----- ---- ------------- -------- ------ -------
|
||||
2s 2s 1 {kubelet worker0} spec.containers{liveness} Warning Unhealthy Liveness probe failed: cat: can't open '/tmp/healthy': No such file or directory
|
||||
```
|
||||
|
||||
显然,这个健康检查探查到 /tmp/healthy 已经不存在了,所以它报告容器是不健康的。那么接下来会发生什么呢?
|
||||
|
||||
再次查看一下这个 Pod 的状态:
|
||||
|
||||
```shell
|
||||
[root@master diandian]# kubectl get pod test-liveness-exec
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
liveness-exec 1/1 Running 1 1m
|
||||
```
|
||||
|
||||
这时发现,Pod 并没有进入 Failed 状态,而是保持了 Running 状态。这是为什么呢?
|
||||
|
||||
RESTARTS 字段从 0 到 1 的变化,就明白原因了:这个异常的容器已经被 Kubernetes 重启了。在这个过程中,Pod 保持 Running 状态不变
|
||||
|
||||
注意:
|
||||
|
||||
Kubernetes 中并没有 Docker 的 Stop 语义。所以虽然是 Restart(重启),但实际却是重新创建了容器
|
||||
|
||||
这个功能就是 Kubernetes 里的Pod 恢复机制,也叫 restartPolicy。它是 Pod 的 Spec 部分的一个标准字段(pod.spec.restartPolicy),默认值是 Always,即:任何时候这个容器发生了异常,它一定会被重新创建
|
||||
|
||||
小提示:
|
||||
|
||||
Pod 的恢复过程,永远都是发生在当前节点上,而不会跑到别的节点上去。事实上,一旦一个 Pod 与一个节点(Node)绑定,除非这个绑定发生了变化(pod.spec.node 字段被修改),否则它永远都不会离开这个节点。这也就意味着,如果这个宿主机宕机了,这个 Pod 也不会主动迁移到其他节点上去。
|
||||
|
||||
而如果你想让 Pod 出现在其他的可用节点上,就必须使用 Deployment 这样的"控制器"来管理 Pod,哪怕你只需要一个 Pod 副本。这就是一个单 Pod 的 Deployment 与一个 Pod 最主要的区别。
|
||||
|
||||
#### 3.http get方式探针
|
||||
|
||||
```shell
|
||||
[root@master diandian]# vim liveness-httpget.yaml
|
||||
apiVersion: v1
|
||||
kind: Pod
|
||||
metadata:
|
||||
name: liveness-httpget-pod
|
||||
namespace: default
|
||||
spec:
|
||||
containers:
|
||||
- name: liveness-exec-container
|
||||
image: daocloud.io/library/nginx
|
||||
imagePullPolicy: IfNotPresent
|
||||
ports:
|
||||
- name: http
|
||||
containerPort: 80
|
||||
livenessProbe:
|
||||
httpGet:
|
||||
port: http
|
||||
path: /index.html
|
||||
initialDelaySeconds: 1
|
||||
periodSeconds: 3
|
||||
```
|
||||
|
||||
创建该pod:
|
||||
|
||||
```shell
|
||||
[root@master diandian]# kubectl create -f liveness-httpget.yaml
|
||||
pod/liveness-httpget-pod created
|
||||
```
|
||||
|
||||
查看当前pod的状态:
|
||||
|
||||
```shell
|
||||
[root@master diandian]# kubectl describe pod liveness-httpget-pod
|
||||
...
|
||||
Liveness: http-get http://:http/index.html delay=1s timeout=1s period=3s #success=1 #failure=3
|
||||
...
|
||||
```
|
||||
|
||||
测试将容器内的index.html删除掉:
|
||||
|
||||
```shell
|
||||
[root@master diandian]# kubectl exec liveness-httpget-pod -c liveness-exec-container -it -- /bin/sh
|
||||
/ # ls
|
||||
bin dev etc home lib media mnt proc root run sbin srv sys tmp usr var
|
||||
/ # mv /usr/share/nginx/html/index.html index.html
|
||||
/ # command terminated with exit code 137
|
||||
```
|
||||
|
||||
可以看到,当把index.html移走后,这个容器立马就退出了
|
||||
|
||||
查看pod的信息:
|
||||
|
||||
```shell
|
||||
[root@master diandian]# kubectl describe pod liveness-httpget-pod
|
||||
...
|
||||
Normal Killing 1m kubelet, node02 Killing container with id docker://liveness-exec-container:Container failed liveness probe.. Container will be killed and recreated.
|
||||
...
|
||||
```
|
||||
|
||||
看输出,容器由于健康检查未通过,pod会被杀掉,并重新创建:
|
||||
|
||||
```shell
|
||||
[root@master diandian]# kubectl get pods
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
liveness-httpget-pod 1/1 Running 1 33m
|
||||
restarts 为 1
|
||||
```
|
||||
|
||||
重新登陆容器查看:
|
||||
|
||||
```shell
|
||||
[root@master diandian]# kubectl exec liveness-httpget-pod -c liveness-exec-container -it -- /bin/sh
|
||||
/ # cat /usr/share/nginx/html/index.html
|
||||
```
|
||||
|
||||
新登陆容器,发现index.html又出现了,证明容器是被重拉了
|
||||
|
||||
#### 4.Pod 的恢复策略
|
||||
|
||||
可以通过设置 restartPolicy,改变 Pod 的恢复策略。一共有3种:
|
||||
|
||||
Always:在任何情况下,只要容器不在运行状态,就自动重启容器
|
||||
|
||||
OnFailure:只在容器异常时才自动重启容器
|
||||
|
||||
Never: 从来不重启容器
|
||||
|
||||
注意:
|
||||
|
||||
官方文档把 restartPolicy 和 Pod 里容器的状态,以及 Pod 状态的对应关系,总结了非常复杂的一大堆情况。实际上,你根本不需要死记硬背这些对应关系,只要记住如下两个基本的设计原理即可:
|
||||
|
||||
只要 Pod 的 restartPolicy 指定的策略允许重启异常的容器(比如:Always),那么这个 Pod 就会保持 Running 状态,并进行容器重启。否则,Pod 就会进入 Failed 状态
|
||||
|
||||
对于包含多个容器的 Pod,只有它里面所有的容器都进入异常状态后,Pod 才会进入 Failed 状态。在此之前,Pod 都是 Running 状态。此时,Pod 的 READY 字段会显示正常容器的个数
|
||||
|
||||
例如:
|
||||
|
||||
```shell
|
||||
[root@master diandian]# kubectl get pod test-liveness-exec
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
liveness-exec 0/1 Running 1 1m
|
||||
```
|
||||
|
||||
123
NEW/kubernetes污点与容忍.md
Normal file
123
NEW/kubernetes污点与容忍.md
Normal file
@ -0,0 +1,123 @@
|
||||
<h1><center>kubernetes污点与容忍</center></h1>
|
||||
|
||||
著作:行癫 <盗版必究>
|
||||
|
||||
------
|
||||
|
||||
## 一:污点与容忍
|
||||
|
||||
对于nodeAffinity无论是硬策略还是软策略方式,都是调度POD到预期节点上,而Taints恰好与之相反,如果一个节点标记为Taints ,除非 POD 也被标识为可以容忍污点节点,否则该 Taints 节点不会被调度pod;比如用户希望把 Master 节点保留给 Kubernetes 系统组件使用,或者把一组具有特殊资源预留给某些 POD,则污点就很有用了,POD 不会再被调度到 taint 标记过的节点
|
||||
|
||||
#### 1.将节点设置为污点
|
||||
|
||||
```shell
|
||||
[root@master yaml]# kubectl taint node node-2 key=value:NoSchedule
|
||||
node/node-2 tainted
|
||||
```
|
||||
|
||||
查看污点:
|
||||
|
||||
```shell
|
||||
[root@master yaml]# kubectl describe node node-1 | grep Taint
|
||||
Taints: <none>
|
||||
```
|
||||
|
||||
#### 2.去除节点污点
|
||||
|
||||
```shell
|
||||
[root@master yaml]# kubectl taint node node-2 key=value:NoSchedule-
|
||||
node/node-2 untainted
|
||||
```
|
||||
|
||||
#### 3.污点分类
|
||||
|
||||
NoSchedule:新的不能容忍的pod不能再调度过来,但是之前运行在node节点中的Pod不受影响
|
||||
|
||||
NoExecute:新的不能容忍的pod不能调度过来,老的pod也会被驱逐
|
||||
|
||||
PreferNoScheduler:表示尽量不调度到污点节点中去
|
||||
|
||||
#### 4.使用
|
||||
|
||||
如果仍然希望某个 POD 调度到 taint 节点上,则必须在 Spec 中做出Toleration定义,才能调度到该节点,举例如下:
|
||||
|
||||
```shell
|
||||
[root@master yaml]# kubectl taint node node-2 key=value:NoSchedule
|
||||
node/node-2 tainted
|
||||
[root@master yaml]# cat b.yaml
|
||||
apiVersion: v1
|
||||
kind: Pod
|
||||
metadata:
|
||||
name: sss
|
||||
spec:
|
||||
affinity:
|
||||
nodeAffinity:
|
||||
requiredDuringSchedulingIgnoredDuringExecution:
|
||||
nodeSelectorTerms:
|
||||
- matchExpressions:
|
||||
- key: app
|
||||
operator: In
|
||||
values:
|
||||
- myapp
|
||||
containers:
|
||||
- name: with-node-affinity
|
||||
image: daocloud.io/library/nginx:latest
|
||||
注意:node-2节点设置为污点,所以label定义到node-2,但是因为有污点所以调度失败,以下是新的yaml文件
|
||||
[root@master yaml]# cat b.yaml
|
||||
apiVersion: v1
|
||||
kind: Pod
|
||||
metadata:
|
||||
name: sss-1
|
||||
spec:
|
||||
affinity:
|
||||
nodeAffinity:
|
||||
requiredDuringSchedulingIgnoredDuringExecution:
|
||||
nodeSelectorTerms:
|
||||
- matchExpressions:
|
||||
- key: app
|
||||
operator: In
|
||||
values:
|
||||
- myapp
|
||||
containers:
|
||||
- name: with-node-affinity
|
||||
image: daocloud.io/library/nginx:latest
|
||||
tolerations:
|
||||
- key: "key"
|
||||
operator: "Equal"
|
||||
value: "value"
|
||||
effect: "NoSchedule"
|
||||
```
|
||||
|
||||
结果:旧的调度失败,新的调度成功
|
||||
|
||||
```shell
|
||||
[root@master yaml]# kubectl get pod -o wide
|
||||
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
|
||||
sss 0/1 Pending 0 3m2s <none> <none> <none> <none>
|
||||
sss-1 1/1 Running 0 7s 10.244.2.9 node-2 <none> <none>
|
||||
```
|
||||
|
||||
注意:
|
||||
|
||||
tolerations: #添加容忍策略
|
||||
|
||||
\- key: "key1" #对应我们添加节点的变量名
|
||||
|
||||
operator: "Equal" #操作符
|
||||
|
||||
value: "value" #容忍的值 key1=value对应
|
||||
|
||||
effect: NoExecute #添加容忍的规则,这里必须和我们标记的五点规则相同
|
||||
|
||||
operator值是Exists,则value属性可以忽略
|
||||
|
||||
operator值是Equal,则表示key与value之间的关系是等于
|
||||
|
||||
operator不指定,则默认为Equal
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Loading…
Reference in New Issue
Block a user