diff --git a/NEW/云原生监控-Promethues.md b/NEW/云原生监控-Promethues.md
new file mode 100644
index 0000000..4024d4c
--- /dev/null
+++ b/NEW/云原生监控-Promethues.md
@@ -0,0 +1,2299 @@
+云原生监控-Prometheus
+
+作者:行癫(盗版必究)
+
+------
+
+## 一:Prometheus基础
+
+#### 1.简介
+
+ Prometheus是一个开源系统监控和警报工具,是云原生基金会中的毕业项目
+
+#### 2.特点
+
+ 具有由指标名称和键/值对标识的时间序列数据的多维数据模型
+
+ 支持 PromQL,一种灵活的查询语言
+
+ 不依赖分布式存储;单个服务器节点是自主的
+
+#### 3.指标
+
+ 用通俗的话来说,指标就是数值测量;时间序列是指随时间变化的记录;用户想要测量的内容因应用程序而异;对于 Web 服务器,它可能是请求时间;对于数据库,它可能是活动连接数或活动查询数等等
+
+ 指标在了解应用程序为何以某种方式运行方面起着重要作用;假设正在运行一个 Web 应用程序并发现它运行缓慢;要了解应用程序发生了什么,您需要一些信息;例如,当请求数很高时,应用程序可能会变慢;如果您有请求数指标,则可以确定原因并增加服务器数量以处理负载
+
+#### 4.数据模型
+
+ Prometheus 从根本上将所有数据存储为**时间序列**:属于同一指标和同一组标记维度的带时间戳的值流
+
+ 每个时间序列都由其指标名称和可选的键值对(称为标签)唯一标识
+
+指标名称:
+
+ 指定要测量的系统的一般特征(例如http_requests_total- 收到的 HTTP 请求总数)
+
+ 指标名称可以包含 ASCII 字母、数字、下划线和冒号;它必须与正则表达式匹配
+
+ 冒号是为用户定义的记录规则保留的;它们不能被直接使用
+
+例如:具有指标名称api_http_requests_total和标签的时间序列method="POST"可以handler="/messages"写成这样
+
+```shell
+api_http_requests_total{method="POST", handler="/messages"}
+```
+
+
+
+## 二:Pormetheus部署
+
+#### 1.获取二进制安装包
+
+ https://github.com/prometheus/prometheus/releases/download/v2.53.0/prometheus-2.53.0.linux-amd64.tar.gz
+
+#### 2.解压安装
+
+```shell
+[root@prometheus ~]# tar xf prometheus-2.53.0.linux-amd64.tar.gz -C /usr/local/
+
+[root@prometheus local]# mv prometheus-2.53.0.linux-amd64/ prometheus
+```
+
+#### 3.配置
+
+```yaml
+[root@prometheus prometheus]# cat prometheus.yml
+# my global config
+global:
+ scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
+ evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
+ # scrape_timeout is set to the global default (10s).
+
+# Alertmanager configuration
+alerting:
+ alertmanagers:
+ - static_configs:
+ - targets:
+ # - alertmanager:9093
+
+# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
+rule_files:
+ # - "first_rules.yml"
+ # - "second_rules.yml"
+
+# A scrape configuration containing exactly one endpoint to scrape:
+# Here it's Prometheus itself.
+scrape_configs:
+ # The job name is added as a label `job=` to any timeseries scraped from this config.
+ - job_name: "prometheus"
+
+ # metrics_path defaults to '/metrics'
+ # scheme defaults to 'http'.
+
+ static_configs:
+ - targets: ["localhost:9090"]
+```
+
+##### 配置详解
+
+配置块
+
+ `global`:`global`块控制 Prometheus 服务器的全局配置
+
+ `rule_files`:`rule_files`块指定了我们希望 Prometheus 服务器加载的任何规则
+
+ `scrape_configs`:`scrape_configs`控制 Prometheus 监控哪些资源
+
+```shell
+scrape_interval 控制 Prometheus 抓取目标的频率
+evaluation_interval 控制 Prometheus 评估规则的频率
+```
+
+#### 4.启动服务
+
+```shell
+[root@prometheus prometheus]# nohup ./prometheus --config.file=prometheus.yml &
+```
+
+#### 5.访问测试
+
+Table视图:路径+`/graph`
+
+
+
+获得指标:路径+`/metrics`
+
+
+
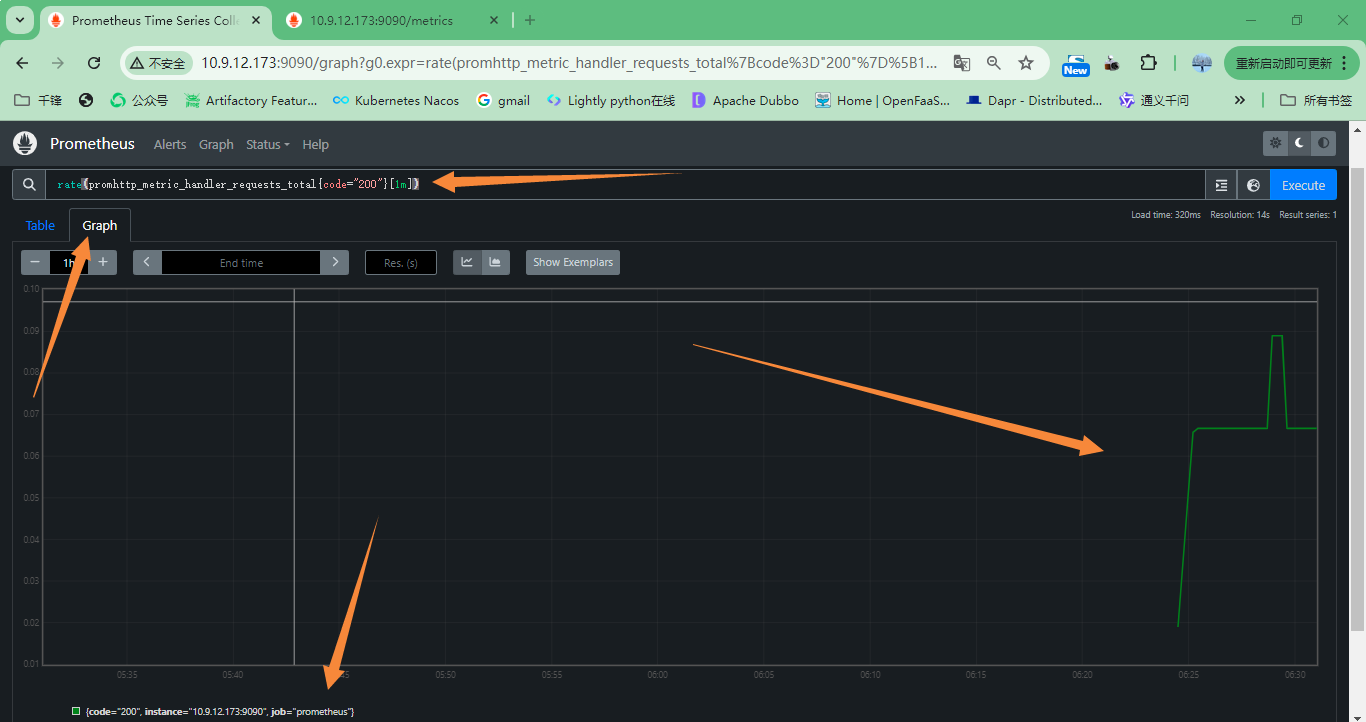
+#### 6.调用案例
+
+1.抓取的 Prometheus 中每秒返回状态代码 200 的 HTTP 请求率,参数图标如下:
+
+`rate(promhttp_metric_handler_requests_total{code="200"}[1m])`
+
+
+
+## 三:监控Kubernetes集群
+
+#### 1.创建命名空间
+
+```shell
+[root@xingdiancloud-native-master-a prometheus]# kubectl create namespace prometheus
+```
+
+#### 2.Kubernetes创建服务账户
+
+```yaml
+[root@xingdiancloud-native-master-a prometheus]# cat serviceaccount.yaml
+apiVersion: v1
+kind: ServiceAccount
+metadata:
+ name: prometheus
+ namespace: prometheus
+```
+
+#### 3.创建角色和角色绑定
+
+```yaml
+[root@xingdiancloud-native-master-a prometheus]# cat role.yaml
+apiVersion: rbac.authorization.k8s.io/v1
+kind: ClusterRole
+metadata:
+ name: prometheus
+rules:
+- apiGroups:
+ - ""
+ resources:
+ - nodes
+ - services
+ - endpoints
+ - pods
+ - nodes/proxy
+ verbs:
+ - get
+ - list
+ - watch
+- apiGroups:
+ - "extensions"
+ resources:
+ - ingresses
+ verbs:
+ - get
+ - list
+ - watch
+- apiGroups:
+ - ""
+ resources:
+ - configmaps
+ - nodes/metrics
+ verbs:
+ - get
+- nonResourceURLs:
+ - /metrics
+ verbs:
+ - get
+---
+
+apiVersion: rbac.authorization.k8s.io/v1
+kind: ClusterRoleBinding
+metadata:
+ name: prometheus
+roleRef:
+ apiGroup: rbac.authorization.k8s.io
+ kind: ClusterRole
+ name: prometheus
+subjects:
+- kind: ServiceAccount
+ name: prometheus
+ namespace: prometheus
+```
+
+#### 4.创建Secret
+
+```yaml
+[root@xingdiancloud-native-master-a prometheus]# cat secret.yaml
+apiVersion: v1
+kind: Secret
+metadata:
+ name: prometheus-token
+ namespace: prometheus
+ annotations:
+ kubernetes.io/service-account.name: prometheus
+type: kubernetes.io/service-account-token
+```
+
+#### 5.获取Token
+
+```shell
+[root@xingdiancloud-native-master-a prometheus]# kubectl -n prometheus describe secret prometheus-token
+Name: prometheus-token
+Namespace: prometheus
+Labels: kubernetes.io/legacy-token-last-used=2024-07-01
+Annotations: kubernetes.io/service-account.name: prometheus
+ kubernetes.io/service-account.uid: f0f6bda3-cd7a-4de4-982d-25c4e0810b84
+
+Type: kubernetes.io/service-account-token
+
+Data
+====
+ca.crt: 1310 bytes
+namespace: 10 bytes
+token: eyJhbGciOiJSUzI1NiIsImtpZCI6ImpzLWJHQXBELURyeUFXZU1Pb0NMYVFVRW40VHVrR3ZJaUR5VlNLajY1ZDAifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJwcm9tZXRoZXVzIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZWNyZXQubmFtZSI6InByb21ldGhldXMtdG9rZW4iLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoicHJvbWV0aGV1cyIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6ImYwZjZiZGEzLWNkN2EtNGRlNC05ODJkLTI1YzRlMDgxMGI4NCIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDpwcm9tZXRoZXVzOnByb21ldGhldXMifQ.g5QsgIfarQ4l5N_1-8j7oE9WJj5bHS27DSinLdGMBwTDjmHrKcrvH_DRnvm4VYQ4zDTNrauk0Yks1S4ZIEsrKv_Iob4VliVRoMCPw1l3BOBZe9T7oDc8sJAYk2fR-rIdYEfgwMtVrXuLHIs3tklTXimUD4_EnzoVBpFshXeXlpITDNMfkh2Uhc6C63cA9Cdt2Wxyjnb3Dz7P27H2pDO2AJ8A-q0JgVLpKNSKks4TaEBeAI6TSZpO1IJIia-OFJpeLJsLUK4xCOc5NIzeUp09O8kbDc0E1c0Jdx1sGQcsP-2Y5YXzeQ_vus0Z4MaqTxNARr95WTW1HfgILw0M5rijWg
+```
+
+#### 6.安装采集器
+
+```yaml
+[root@xingdiancloud-native-master-a prometheus]# cat node-exporte.yaml
+kind: DaemonSet
+apiVersion: apps/v1
+metadata:
+ name: node-exporter
+ annotations:
+ prometheus.io/scrape: 'true'
+spec:
+ selector:
+ matchLabels:
+ app: node-exporter
+ template:
+ metadata:
+ labels:
+ app: node-exporter
+ name: node-exporter
+ spec:
+ containers:
+ - image: quay.io/prometheus/node-exporter:latest
+ #- image: 10.9.12.201/prometheus/node-exporter:latest
+ name: node-exporter
+ ports:
+ - containerPort: 9100
+ hostPort: 9100
+ name: node-exporter
+ hostNetwork: true
+ hostPID: true
+ tolerations:
+ - key: "node-role.kubernetes.io/master"
+ operator: "Exists"
+ effect: "NoSchedule"
+```
+
+#### 7.安装kube-state-metrics
+
+官网地址:https://github.com/kubernetes/kube-state-metrics/tree/main/examples/standard
+
+创建服务账户
+
+```yaml
+[root@xingdiancloud-native-master-a metric]# cat service-account.yaml
+apiVersion: v1
+automountServiceAccountToken: false
+kind: ServiceAccount
+metadata:
+ labels:
+ app.kubernetes.io/component: exporter
+ app.kubernetes.io/name: kube-state-metrics
+ app.kubernetes.io/version: 2.12.0
+ name: kube-state-metrics
+ namespace: kube-system
+```
+
+创建集群角色
+
+```yaml
+[root@xingdiancloud-native-master-a metric]# cat cluster-role.yaml
+apiVersion: rbac.authorization.k8s.io/v1
+kind: ClusterRole
+metadata:
+ labels:
+ app.kubernetes.io/component: exporter
+ app.kubernetes.io/name: kube-state-metrics
+ app.kubernetes.io/version: 2.12.0
+ name: kube-state-metrics
+rules:
+- apiGroups:
+ - ""
+ resources:
+ - configmaps
+ - secrets
+ - nodes
+ - pods
+ - services
+ - serviceaccounts
+ - resourcequotas
+ - replicationcontrollers
+ - limitranges
+ - persistentvolumeclaims
+ - persistentvolumes
+ - namespaces
+ - endpoints
+ verbs:
+ - list
+ - watch
+- apiGroups:
+ - apps
+ resources:
+ - statefulsets
+ - daemonsets
+ - deployments
+ - replicasets
+ verbs:
+ - list
+ - watch
+- apiGroups:
+ - batch
+ resources:
+ - cronjobs
+ - jobs
+ verbs:
+ - list
+ - watch
+- apiGroups:
+ - autoscaling
+ resources:
+ - horizontalpodautoscalers
+ verbs:
+ - list
+ - watch
+- apiGroups:
+ - authentication.k8s.io
+ resources:
+ - tokenreviews
+ verbs:
+ - create
+- apiGroups:
+ - authorization.k8s.io
+ resources:
+ - subjectaccessreviews
+ verbs:
+ - create
+- apiGroups:
+ - policy
+ resources:
+ - poddisruptionbudgets
+ verbs:
+ - list
+ - watch
+- apiGroups:
+ - certificates.k8s.io
+ resources:
+ - certificatesigningrequests
+ verbs:
+ - list
+ - watch
+- apiGroups:
+ - discovery.k8s.io
+ resources:
+ - endpointslices
+ verbs:
+ - list
+ - watch
+- apiGroups:
+ - storage.k8s.io
+ resources:
+ - storageclasses
+ - volumeattachments
+ verbs:
+ - list
+ - watch
+- apiGroups:
+ - admissionregistration.k8s.io
+ resources:
+ - mutatingwebhookconfigurations
+ - validatingwebhookconfigurations
+ verbs:
+ - list
+ - watch
+- apiGroups:
+ - networking.k8s.io
+ resources:
+ - networkpolicies
+ - ingressclasses
+ - ingresses
+ verbs:
+ - list
+ - watch
+- apiGroups:
+ - coordination.k8s.io
+ resources:
+ - leases
+ verbs:
+ - list
+ - watch
+- apiGroups:
+ - rbac.authorization.k8s.io
+ resources:
+ - clusterrolebindings
+ - clusterroles
+ - rolebindings
+ - roles
+ verbs:
+ - list
+ - watch
+```
+
+创建角色绑定
+
+```yaml
+[root@xingdiancloud-native-master-a metric]# cat cluster-role-binding.yaml
+apiVersion: rbac.authorization.k8s.io/v1
+kind: ClusterRoleBinding
+metadata:
+ labels:
+ app.kubernetes.io/component: exporter
+ app.kubernetes.io/name: kube-state-metrics
+ app.kubernetes.io/version: 2.12.0
+ name: kube-state-metrics
+roleRef:
+ apiGroup: rbac.authorization.k8s.io
+ kind: ClusterRole
+ name: kube-state-metrics
+subjects:
+- kind: ServiceAccount
+ name: kube-state-metrics
+ namespace: kube-system
+```
+
+创建kube-state-metrics
+
+```yaml
+[root@xingdiancloud-native-master-a metric]# cat deployment.yaml
+apiVersion: apps/v1
+kind: Deployment
+metadata:
+ labels:
+ app.kubernetes.io/component: exporter
+ app.kubernetes.io/name: kube-state-metrics
+ app.kubernetes.io/version: 2.12.0
+ name: kube-state-metrics
+ namespace: kube-system
+spec:
+ replicas: 1
+ selector:
+ matchLabels:
+ app.kubernetes.io/name: kube-state-metrics
+ template:
+ metadata:
+ labels:
+ app.kubernetes.io/component: exporter
+ app.kubernetes.io/name: kube-state-metrics
+ app.kubernetes.io/version: 2.12.0
+ spec:
+ automountServiceAccountToken: true
+ containers:
+ - image: registry.k8s.io/kube-state-metrics/kube-state-metrics:v2.12.0
+ #- image: 10.9.12.201/prometheus/kube-state-metrics:v2.12.0
+ livenessProbe:
+ httpGet:
+ path: /livez
+ port: 8080
+ initialDelaySeconds: 5
+ timeoutSeconds: 5
+ name: kube-state-metrics
+ ports:
+ - containerPort: 8080
+ name: http-metrics
+ - containerPort: 8081
+ name: telemetry
+ readinessProbe:
+ httpGet:
+ path: /metrics
+ port: 8081
+ initialDelaySeconds: 5
+ timeoutSeconds: 5
+ securityContext:
+ allowPrivilegeEscalation: false
+ capabilities:
+ drop:
+ - ALL
+ readOnlyRootFilesystem: true
+ runAsNonRoot: true
+ runAsUser: 65534
+ seccompProfile:
+ type: RuntimeDefault
+ nodeSelector:
+ kubernetes.io/os: linux
+ serviceAccountName: kube-state-metrics
+```
+
+创建服务
+
+```yaml
+[root@xingdiancloud-native-master-a metric]# cat service.yaml
+apiVersion: v1
+kind: Service
+metadata:
+ labels:
+ app.kubernetes.io/component: exporter
+ app.kubernetes.io/name: kube-state-metrics
+ app.kubernetes.io/version: 2.12.0
+ name: kube-state-metrics
+ namespace: kube-system
+spec:
+ clusterIP: None
+ ports:
+ - name: http-metrics
+ port: 8080
+ targetPort: http-metrics
+ - name: telemetry
+ port: 8081
+ targetPort: telemetry
+ selector:
+ app.kubernetes.io/name: kube-state-metrics
+```
+
+#### 8.配置Prometheus
+
+```yaml
+[root@prometheus prometheus]# cat prometheus.yml
+# my global config
+global:
+ scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
+ evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
+ # scrape_timeout is set to the global default (10s).
+
+# Alertmanager configuration
+alerting:
+ alertmanagers:
+ - static_configs:
+ - targets:
+ # - alertmanager:9093
+
+# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
+rule_files:
+ # - "first_rules.yml"
+ # - "second_rules.yml"
+
+# A scrape configuration containing exactly one endpoint to scrape:
+# Here it's Prometheus itself.
+scrape_configs:
+ # The job name is added as a label `job=` to any timeseries scraped from this config.
+ - job_name: "prometheus"
+
+ # metrics_path defaults to '/metrics'
+ # scheme defaults to 'http'.
+
+ - job_name: 'xingdiancloud-kubernetes-nodes'
+ static_configs:
+ - targets: ['10.9.12.205:9100','10.9.12.204:9100','10.9.12.203:9100']
+ metrics_path: /metrics
+ scheme: http
+ honor_labels: true
+
+ - job_name: "kube-state-metrics"
+ scheme: https
+ tls_config:
+ insecure_skip_verify: true
+ bearer_token: 'eyJhbGciOiJSUzI1NiIsImtpZCI6ImpzLWJHQXBELURyeUFXZU1Pb0NMYVFVRW40VHVrR3ZJaUR5VlNLajY1ZDAifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJwcm9tZXRoZXVzIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZWNyZXQubmFtZSI6InByb21ldGhldXMtdG9rZW4iLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoicHJvbWV0aGV1cyIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6ImYwZjZiZGEzLWNkN2EtNGRlNC05ODJkLTI1YzRlMDgxMGI4NCIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDpwcm9tZXRoZXVzOnByb21ldGhldXMifQ.g5QsgIfarQ4l5N_1-8j7oE9WJj5bHS27DSinLdGMBwTDjmHrKcrvH_DRnvm4VYQ4zDTNrauk0Yks1S4ZIEsrKv_Iob4VliVRoMCPw1l3BOBZe9T7oDc8sJAYk2fR-rIdYEfgwMtVrXuLHIs3tklTXimUD4_EnzoVBpFshXeXlpITDNMfkh2Uhc6C63cA9Cdt2Wxyjnb3Dz7P27H2pDO2AJ8A-q0JgVLpKNSKks4TaEBeAI6TSZpO1IJIia-OFJpeLJsLUK4xCOc5NIzeUp09O8kbDc0E1c0Jdx1sGQcsP-2Y5YXzeQ_vus0Z4MaqTxNARr95WTW1HfgILw0M5rijWg'
+ kubernetes_sd_configs:
+ - role: endpoints
+ api_server: "https://10.9.12.100:6443"
+ tls_config:
+ insecure_skip_verify: true
+ bearer_token: 'eyJhbGciOiJSUzI1NiIsImtpZCI6ImpzLWJHQXBELURyeUFXZU1Pb0NMYVFVRW40VHVrR3ZJaUR5VlNLajY1ZDAifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJwcm9tZXRoZXVzIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZWNyZXQubmFtZSI6InByb21ldGhldXMtdG9rZW4iLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoicHJvbWV0aGV1cyIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6ImYwZjZiZGEzLWNkN2EtNGRlNC05ODJkLTI1YzRlMDgxMGI4NCIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDpwcm9tZXRoZXVzOnByb21ldGhldXMifQ.g5QsgIfarQ4l5N_1-8j7oE9WJj5bHS27DSinLdGMBwTDjmHrKcrvH_DRnvm4VYQ4zDTNrauk0Yks1S4ZIEsrKv_Iob4VliVRoMCPw1l3BOBZe9T7oDc8sJAYk2fR-rIdYEfgwMtVrXuLHIs3tklTXimUD4_EnzoVBpFshXeXlpITDNMfkh2Uhc6C63cA9Cdt2Wxyjnb3Dz7P27H2pDO2AJ8A-q0JgVLpKNSKks4TaEBeAI6TSZpO1IJIia-OFJpeLJsLUK4xCOc5NIzeUp09O8kbDc0E1c0Jdx1sGQcsP-2Y5YXzeQ_vus0Z4MaqTxNARr95WTW1HfgILw0M5rijWg'
+ relabel_configs:
+ - source_labels: [__meta_kubernetes_service_name]
+ action: keep
+ regex: '^(kube-state-metrics)$'
+ - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
+ action: keep
+ regex: true
+ - source_labels: [__address__]
+ action: replace
+ target_label: instance
+ - target_label: __address__
+ replacement: 10.9.12.100:6443
+ - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_pod_name, __meta_kubernetes_pod_container_port_number]
+ regex: ([^;]+);([^;]+);([^;]+)
+ target_label: __metrics_path__
+ replacement: /api/v1/namespaces/${1}/pods/http:${2}:${3}/proxy/metrics
+ - action: labelmap
+ regex: __meta_kubernetes_service_label_(.+)
+ - source_labels: [__meta_kubernetes_namespace]
+ action: replace
+ target_label: kubernetes_namespace
+ - source_labels: [__meta_kubernetes_service_name]
+ action: replace
+ target_label: service_name
+ - job_name: "kube-node-kubelet"
+ scheme: https
+ tls_config:
+ insecure_skip_verify: true
+ bearer_token: 'eyJhbGciOiJSUzI1NiIsImtpZCI6ImpzLWJHQXBELURyeUFXZU1Pb0NMYVFVRW40VHVrR3ZJaUR5VlNLajY1ZDAifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJwcm9tZXRoZXVzIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZWNyZXQubmFtZSI6InByb21ldGhldXMtdG9rZW4iLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoicHJvbWV0aGV1cyIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6ImYwZjZiZGEzLWNkN2EtNGRlNC05ODJkLTI1YzRlMDgxMGI4NCIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDpwcm9tZXRoZXVzOnByb21ldGhldXMifQ.g5QsgIfarQ4l5N_1-8j7oE9WJj5bHS27DSinLdGMBwTDjmHrKcrvH_DRnvm4VYQ4zDTNrauk0Yks1S4ZIEsrKv_Iob4VliVRoMCPw1l3BOBZe9T7oDc8sJAYk2fR-rIdYEfgwMtVrXuLHIs3tklTXimUD4_EnzoVBpFshXeXlpITDNMfkh2Uhc6C63cA9Cdt2Wxyjnb3Dz7P27H2pDO2AJ8A-q0JgVLpKNSKks4TaEBeAI6TSZpO1IJIia-OFJpeLJsLUK4xCOc5NIzeUp09O8kbDc0E1c0Jdx1sGQcsP-2Y5YXzeQ_vus0Z4MaqTxNARr95WTW1HfgILw0M5rijWg'
+ kubernetes_sd_configs:
+ - role: node
+ api_server: "https://10.9.12.100:6443"
+ tls_config:
+ insecure_skip_verify: true
+ bearer_token: 'eyJhbGciOiJSUzI1NiIsImtpZCI6ImpzLWJHQXBELURyeUFXZU1Pb0NMYVFVRW40VHVrR3ZJaUR5VlNLajY1ZDAifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJwcm9tZXRoZXVzIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZWNyZXQubmFtZSI6InByb21ldGhldXMtdG9rZW4iLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoicHJvbWV0aGV1cyIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6ImYwZjZiZGEzLWNkN2EtNGRlNC05ODJkLTI1YzRlMDgxMGI4NCIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDpwcm9tZXRoZXVzOnByb21ldGhldXMifQ.g5QsgIfarQ4l5N_1-8j7oE9WJj5bHS27DSinLdGMBwTDjmHrKcrvH_DRnvm4VYQ4zDTNrauk0Yks1S4ZIEsrKv_Iob4VliVRoMCPw1l3BOBZe9T7oDc8sJAYk2fR-rIdYEfgwMtVrXuLHIs3tklTXimUD4_EnzoVBpFshXeXlpITDNMfkh2Uhc6C63cA9Cdt2Wxyjnb3Dz7P27H2pDO2AJ8A-q0JgVLpKNSKks4TaEBeAI6TSZpO1IJIia-OFJpeLJsLUK4xCOc5NIzeUp09O8kbDc0E1c0Jdx1sGQcsP-2Y5YXzeQ_vus0Z4MaqTxNARr95WTW1HfgILw0M5rijWg'
+ relabel_configs:
+ - target_label: __address__
+ replacement: 10.9.12.100:6443
+ - source_labels: [__meta_kubernetes_node_name]
+ regex: (.+)
+ target_label: __metrics_path__
+ replacement: /api/v1/nodes/${1}:10250/proxy/metrics
+ - action: labelmap
+ regex: __meta_kubernetes_service_label_(.+)
+ - source_labels: [__meta_kubernetes_namespace]
+ action: replace
+ target_label: kubernetes_namespace
+ - source_labels: [__meta_kubernetes_service_name]
+ action: replace
+ target_label: service_name
+
+ - job_name: "kube-node-cadvisor"
+ scheme: https
+ tls_config:
+ insecure_skip_verify: true
+ bearer_token: 'eyJhbGciOiJSUzI1NiIsImtpZCI6ImpzLWJHQXBELURyeUFXZU1Pb0NMYVFVRW40VHVrR3ZJaUR5VlNLajY1ZDAifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJwcm9tZXRoZXVzIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZWNyZXQubmFtZSI6InByb21ldGhldXMtdG9rZW4iLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoicHJvbWV0aGV1cyIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6ImYwZjZiZGEzLWNkN2EtNGRlNC05ODJkLTI1YzRlMDgxMGI4NCIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDpwcm9tZXRoZXVzOnByb21ldGhldXMifQ.g5QsgIfarQ4l5N_1-8j7oE9WJj5bHS27DSinLdGMBwTDjmHrKcrvH_DRnvm4VYQ4zDTNrauk0Yks1S4ZIEsrKv_Iob4VliVRoMCPw1l3BOBZe9T7oDc8sJAYk2fR-rIdYEfgwMtVrXuLHIs3tklTXimUD4_EnzoVBpFshXeXlpITDNMfkh2Uhc6C63cA9Cdt2Wxyjnb3Dz7P27H2pDO2AJ8A-q0JgVLpKNSKks4TaEBeAI6TSZpO1IJIia-OFJpeLJsLUK4xCOc5NIzeUp09O8kbDc0E1c0Jdx1sGQcsP-2Y5YXzeQ_vus0Z4MaqTxNARr95WTW1HfgILw0M5rijWg'
+ kubernetes_sd_configs:
+ - role: node
+ api_server: "https://10.9.12.100:6443"
+ tls_config:
+ insecure_skip_verify: true
+ bearer_token: 'eyJhbGciOiJSUzI1NiIsImtpZCI6ImpzLWJHQXBELURyeUFXZU1Pb0NMYVFVRW40VHVrR3ZJaUR5VlNLajY1ZDAifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJwcm9tZXRoZXVzIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZWNyZXQubmFtZSI6InByb21ldGhldXMtdG9rZW4iLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoicHJvbWV0aGV1cyIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6ImYwZjZiZGEzLWNkN2EtNGRlNC05ODJkLTI1YzRlMDgxMGI4NCIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDpwcm9tZXRoZXVzOnByb21ldGhldXMifQ.g5QsgIfarQ4l5N_1-8j7oE9WJj5bHS27DSinLdGMBwTDjmHrKcrvH_DRnvm4VYQ4zDTNrauk0Yks1S4ZIEsrKv_Iob4VliVRoMCPw1l3BOBZe9T7oDc8sJAYk2fR-rIdYEfgwMtVrXuLHIs3tklTXimUD4_EnzoVBpFshXeXlpITDNMfkh2Uhc6C63cA9Cdt2Wxyjnb3Dz7P27H2pDO2AJ8A-q0JgVLpKNSKks4TaEBeAI6TSZpO1IJIia-OFJpeLJsLUK4xCOc5NIzeUp09O8kbDc0E1c0Jdx1sGQcsP-2Y5YXzeQ_vus0Z4MaqTxNARr95WTW1HfgILw0M5rijWg'
+ relabel_configs:
+ - target_label: __address__
+ replacement: 10.9.12.100:6443
+ - source_labels: [__meta_kubernetes_node_name]
+ regex: (.+)
+ target_label: __metrics_path__
+ replacement: /api/v1/nodes/${1}:10250/proxy/metrics/cadvisor
+ - action: labelmap
+ regex: __meta_kubernetes_service_label_(.+)
+ - source_labels: [__meta_kubernetes_namespace]
+ action: replace
+ target_label: kubernetes_namespace
+ - source_labels: [__meta_kubernetes_service_name]
+ action: replace
+ target_label: service_name
+ static_configs:
+ - targets: ["10.9.12.173:9090"]
+```
+
+#### 9.启动Prometheus
+
+```shell
+[root@prometheus prometheus]# nohup ./prometheus --config.file=prometheus.yml &
+```
+
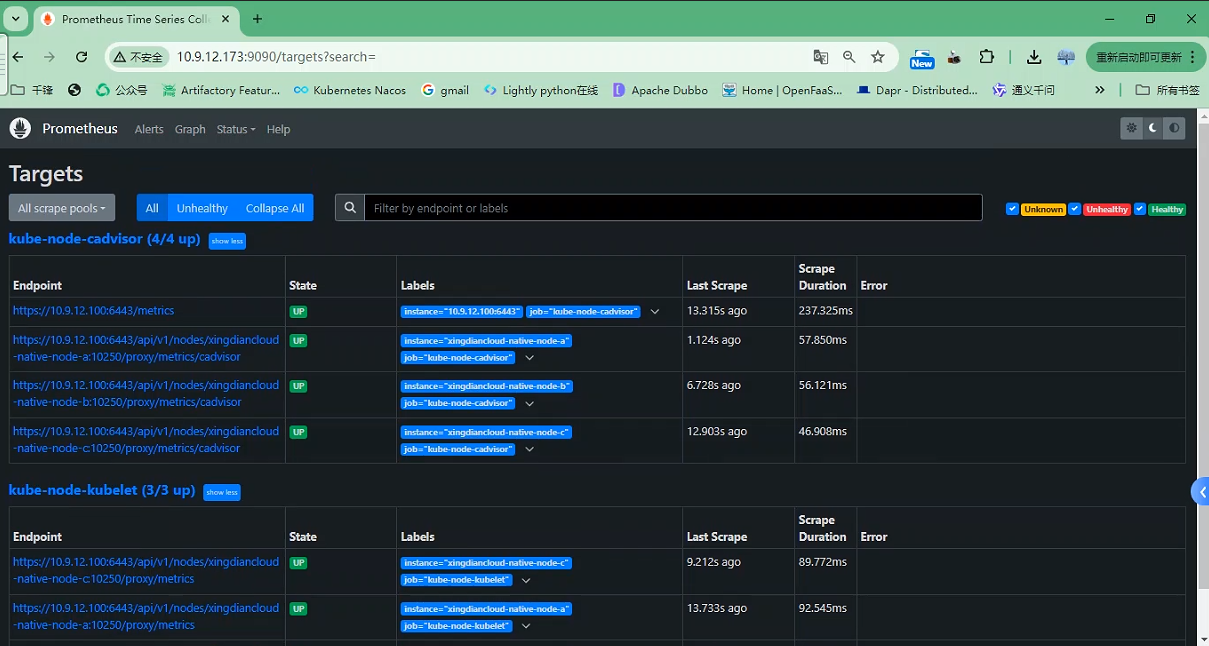
+#### 10.浏览器访问验证
+
+
+
+#### 11.参数解释
+
+```shell
+scrape_configs:
+ - job_name: "prometheus"
+ # 默认的 `metrics_path` 是 `/metrics`
+ # 默认的 `scheme` 是 `http`
+job_name: 用于标识该作业的名称,并作为标签 job= 添加到从该配置抓取的任何时间序列。
+metrics_path: 定义 Prometheus 将要抓取的路径,默认为 /metrics。
+scheme: 定义抓取时使用的协议,默认为 http。我们使用https
+kube-state-metrics 配置
+scheme: 使用 https 协议。
+tls_config: 配置 TLS,insecure_skip_verify: true 意味着忽略证书验证。
+bearer_token: 使用 Bearer Token 进行认证。
+kubernetes_sd_configs: 使用 Kubernetes 服务发现配置。
+role: endpoints: 指定角色为 endpoints,表示抓取 Kubernetes 服务的端点信息。
+api_server: Kubernetes API 服务器的地址。
+relabel_configs: 重新标签配置,用于动态生成指标标签。
+source_labels: [__meta_kubernetes_service_name]: 仅保留 kube-state-metrics 服务。
+source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]: 仅保留被标记为 true 的服务。
+source_labels: [address]: 将原地址替换为 instance 标签。
+target_label: address: 将所有地址替换为 10.9.12.100:6443。
+source_labels: 将命名空间、pod 名称和端口号组合成新的 metrics_path。
+labelmap: 将所有 Kubernetes 服务标签映射到 Prometheus 标签。
+source_labels: [__meta_kubernetes_namespace]: 替换命名空间标签。
+source_labels: [__meta_kubernetes_service_name]: 替换服务名称标签。
+
+kube-node-kubelet 配置
+role: node: 指定角色为 node,表示抓取节点信息。
+relabel_configs: 重新标签配置。
+target_label: address: 将所有地址替换为 10.9.12.100:6443。
+source_labels: [__meta_kubernetes_node_name]: 使用节点名称构造新的 metrics_path。
+
+kube-node-cadvisor 配置
+role: node: 指定角色为 node,表示抓取节点信息。
+relabel_configs: 重新标签配置。
+target_label: address: 将所有地址替换为 10.9.12.100:6443。
+source_labels: [__meta_kubernetes_node_name]: 使用节点名称构造新的 metrics_path。
+static_configs: 定义静态配置目标。
+targets: 定义静态目标地址。
+通过以上配置,Prometheus 将能够正确地抓取 Kubernetes 集群中的各类指标数据。你需要根据实际情况更新 bearer_token 和 api_server 地址。
+```
+
+## 四:Grafana展示分析
+
+#### 1.Grafana简介
+
+ Grafana 是一个广泛使用的开源数据可视化和监控工具
+
+##### 版本
+
+ Grafana OSS
+
+ Grafana Enterprise
+
+##### Grafana OSS (Open Source Software)
+
+ Grafana OSS 是 Grafana 的开源版本,免费提供,并且包含了大多数用户所需的基本功能
+
+ **数据源支持**:支持多种数据源,包括 Prometheus、Graphite、Elasticsearch、MySQL、PostgreSQL 等
+
+ **仪表盘和可视化**:提供丰富的可视化组件,可以创建各种图表、仪表盘和告警
+
+ **插件生态系统**:支持社区和官方开发的插件,可以扩展 Grafana 的功能
+
+ **用户管理**:提供基本的用户和组织管理功能
+
+ **告警**:支持基本的告警功能,可以通过电子邮件、Slack 等方式发送告警通知
+
+##### Grafana Enterprise
+
+ Grafana Enterprise 是 Grafana 的商业版本,基于 Grafana OSS 构建,并增加了许多企业级功能
+
+ **高级数据源**:除了支持 OSS 中的数据源外,还提供企业级数据源支持,比如ServiceNow、Datadog等
+
+ **企业插件**:提供专有的企业插件和增强功能
+
+ **团队和角色管理**:提供更细粒度的权限管理,可以针对不同的团队和角色设置不同的权限
+
+ **审计日志**:记录用户操作日志,方便审计和合规管理
+
+ **报表和导出**:支持生成报表和数据导出功能
+
+ **企业支持**:提供专业的技术支持和咨询服务
+
+#### 2.安装部署
+
+注意
+
+ 安装Grafana OSS 版本
+
+ 本次采用基于二进制方式安装,基于Docker Image或者Kubernetes集群或者Helm Charts 见其他文档
+
+##### 安装方式
+
+ 基于YUM方式安装
+
+ 基于二进制方式安装
+
+ 基于Docker Image 部署
+
+ 基于Kubernetes集群部署
+
+ 基于Helm Charts 部署
+
+##### 获取二进制包
+
+```shell
+[root@grafana ~]# wget https://dl.grafana.com/oss/release/grafana-11.1.0.linux-amd64.tar.gz
+```
+
+##### 安装
+
+```shell
+[root@grafana ~]# tar xf grafana-11.1.0.linux-amd64.tar.gz -C /usr/local/
+[root@grafana ~]# mv /usr/local/grafana-v11.1.0/ /usr/local/grafana
+```
+
+##### 安装数据库
+
+ 注意:
+
+ Grafana会产生数据,并使用数据库存储,默认使用主数据库,我们也可以自己配置数据库
+
+ 本案例中以Mysql为例,安装略
+
+ 如果使用,需要按照要求完成对数据库的配置
+
+##### 安装Redis
+
+ 注意:
+
+ Grafana可以配置缓存服务器,来提升Grafana的性能
+
+ 本案例中以Redis为例,安装略
+
+ 如果使用,需要按照要求完成对Redis的配置
+
+##### 配置Grafana
+
+配置文件官方地址:https://grafana.com/docs/grafana/latest/setup-grafana/configure-grafana/
+
+Grafana 实例的默认设置存储在该`$WORKING_DIR/conf/defaults.ini`文件中
+
+自定义配置文件可以是文件`$WORKING_DIR/conf/custom.ini`或`/usr/local/etc/grafana/grafana.ini`
+
+##### 参数解释
+
+服务端配置:
+
+```shell
+[server]
+# Protocol (http, https, h2, socket)
+protocol = http
+
+# Minimum TLS version allowed. By default, this value is empty. Accepted values are: TLS1.2, TLS1.3. If nothing is set TLS1.2 would be taken
+min_tls_version = ""
+
+# The ip address to bind to, empty will bind to all interfaces
+http_addr = 10.9.12.172
+
+# The http port to use
+http_port = 3000
+
+# The public facing domain name used to access grafana from a browser
+domain = localhost
+
+# Redirect to correct domain if host header does not match domain
+# Prevents DNS rebinding attacks
+enforce_domain = false
+
+# The full public facing url
+root_url = %(protocol)s://%(domain)s:%(http_port)s/
+
+# Serve Grafana from subpath specified in `root_url` setting. By default it is set to `false` for compatibility reasons.
+serve_from_sub_path = false
+```
+
+**`protocol`**:设置为 `http` 以使用 HTTP 协议
+
+**`min_tls_version`**:此参数在 HTTP 协议下不需要配置,可以留空
+
+**`http_addr`**:绑定的 IP 地址,设置为 `10.9.12.172`
+
+**`http_port`**:HTTP 端口,设置为 `3000`
+
+**`domain`**:域名,设置为 `localhost`
+
+**`enforce_domain`**:设置为 `false` 以禁用域名重定向检查
+
+**`root_url`**:设置为 `http://localhost:3000/`,包含协议、域名和端口
+
+**`serve_from_sub_path`**:如果你不需要从子路径提供服务,设置为 `false`
+
+连接数据库配置:
+
+```shell
+[database]
+# You can configure the database connection by specifying type, host, name, user and password
+# as separate properties or as a url in the following format:
+# url = postgres://grafana:grafana@localhost:5432/grafana
+
+# Either "mysql", "postgres" or "sqlite3", it's your choice
+type = mysql
+host = 127.0.0.1:3306
+name = grafana
+user = root
+password = your_password
+
+# Use either URL or the previous fields to configure the database
+# url = mysql://root:your_password@127.0.0.1:3306/grafana
+
+# For "postgres" only, either "disable", "require" or "verify-full"
+ssl_mode = disable
+
+# For "sqlite3" only, path relative to data_path setting
+# file = grafana.db
+```
+
+**`type`**:设置为 `mysql` 以使用 MySQL 数据库
+
+**`host`**:设置为 MySQL 数据库的地址和端口
+
+**`name`**:数据库名称
+
+**`user`**:数据库用户
+
+**`password`**:数据库用户的密码
+
+连接Redis配置:
+
+```shell
+# Cache configuration section
+[cache]
+
+# Cache type: Either "redis", "memcached" or "database" (default is "database")
+type = redis
+
+# Cache connection string options
+# database: will use Grafana primary database.
+# redis: config like redis server e.g. `addr=127.0.0.1:6379,pool_size=100,db=0,ssl=false`. Only addr is required. ssl may be 'true', 'false', or 'insecure'.
+# memcache: 127.0.0.1:11211
+connstr = addr=10.9.12.206:6379,pool_size=100,db=0,ssl=false
+
+# Prefix prepended to all the keys in the remote cache
+prefix = grafana_
+
+# This enables encryption of values stored in the remote cache
+encryption = true
+
+```
+
+**`type`**:缓存类型,可以是 `redis`、`memcached` 或 `database`。默认是 `database`,即使用 Grafana 的主数据库进行缓存
+
+**`connstr`**:缓存连接字符串,根据缓存类型不同而不同
+
+- **`database`**:无需配置连接字符串,会自动使用 Grafana 的主数据库
+- **`redis`**:配置类似 `addr=127.0.0.1:6379,pool_size=100,db=0,ssl=false`。其中 `addr` 是必需的,`ssl` 可以是 `true`、`false` 或 `insecure`
+- **`memcache`**:配置类似 `127.0.0.1:11211`
+
+**`prefix`**:在所有缓存键前添加的前缀,用于区分不同应用的数据
+
+**`encryption`**:启用存储在远程缓存中的值的加密
+
+##### 运行Grafana
+
+```shell
+[root@grafana ~]# nohup ./bin/grafana-server --config ./conf/defaults.ini &
+```
+
+注意:在Grafana的安装目录下执行
+
+##### 安装目录
+
+**bin**:存放 Grafana 的可执行文件,通常包含 `grafana-server` 和 `grafana-cli` 等
+
+**data**:存放运行时数据,如 SQLite 数据库文件、日志文件和临时文件等
+
+**docs**:存放项目的文档,包括用户手册、开发者文档等
+
+**npm-artifacts**:存放由 npm 构建生成的文件和包
+
+**plugins-bundled**:包含预打包的插件,默认插件通常都放在这里
+
+**README.md**:项目的 README 文件,包含项目的介绍、安装使用说明等信息
+
+**tools**:存放开发和维护 Grafana 的工具脚本或程序
+
+**conf**:存放 Grafana 的配置文件,如 `grafana.ini` 等
+
+**Dockerfile**:用于构建 Grafana Docker 镜像的文件,定义了如何在 Docker 中安装和配置 Grafana
+
+**LICENSE**:项目的许可证文件,说明了 Grafana 的使用和分发许可
+
+**NOTICE.md**:包含版权和许可声明的文件,通常用于第三方组件的声明
+
+**packaging**:包含用于构建和分发 Grafana 的打包脚本和配置文件
+
+**public**:包含前端静态资源,如 HTML、CSS、JavaScript 文件等,用于 Grafana 的 Web 界面
+
+**storybook**:用于存放 Storybook 配置和故事文件,Storybook 是一个用于开发和测试 UI 组件的工具
+
+**VERSION**:包含当前 Grafana 版本号的文件,通常是一个文本文件
+
+#### 3.使用案例
+
+案例一:监控Kubernetes集群中某个Node节点的POD数量
+
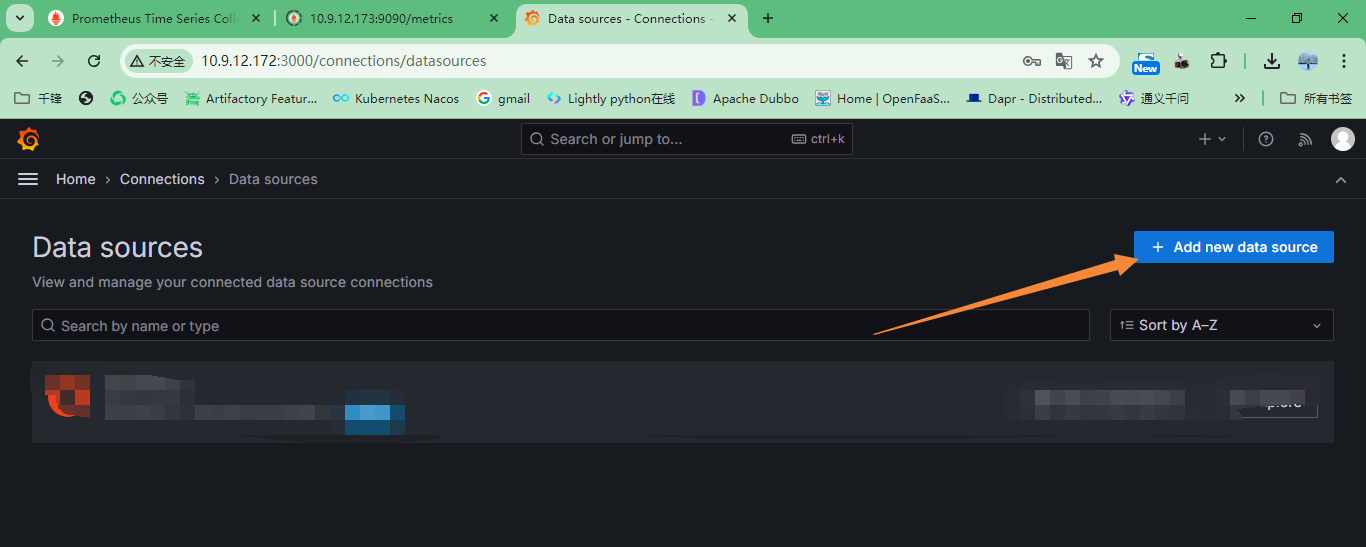
+##### 添加数据源
+
+ 数据源不需要额外重复添加
+
+
+
+
+
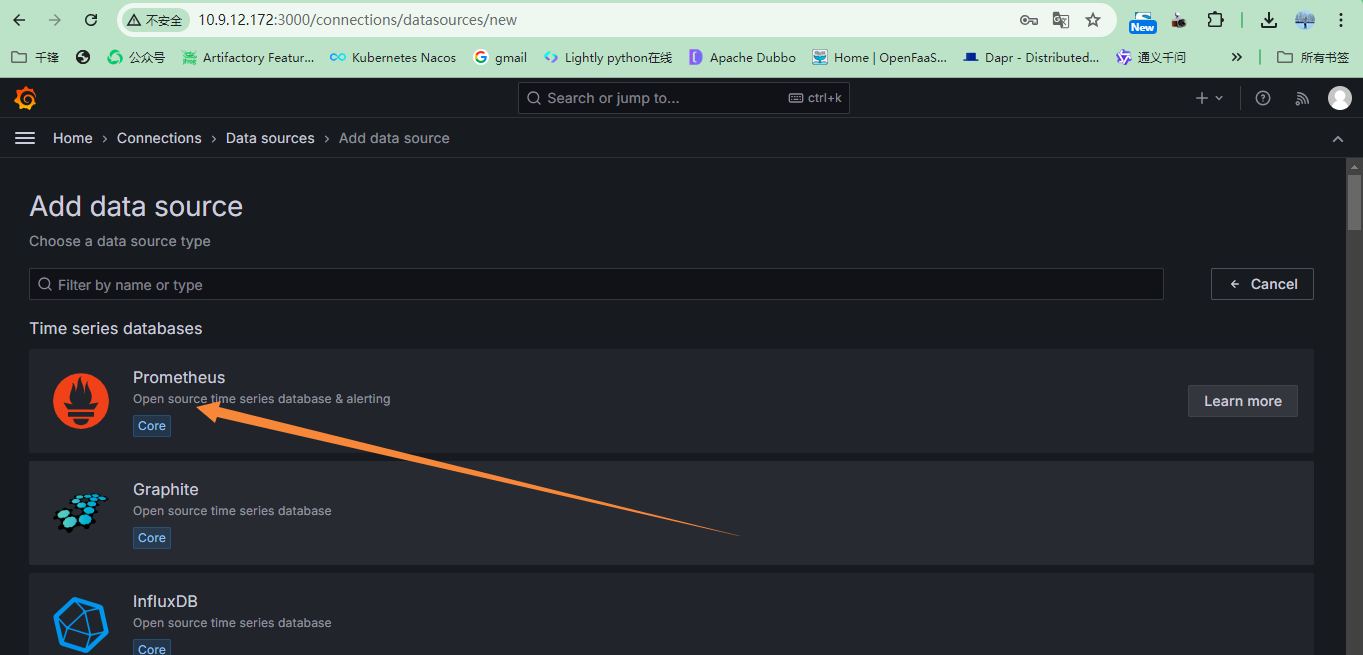
+添加数据源:本实验数据源来自Prometheus,也可以是其他的数据源,例如:InfluxDB,Zabbix等
+
+
+
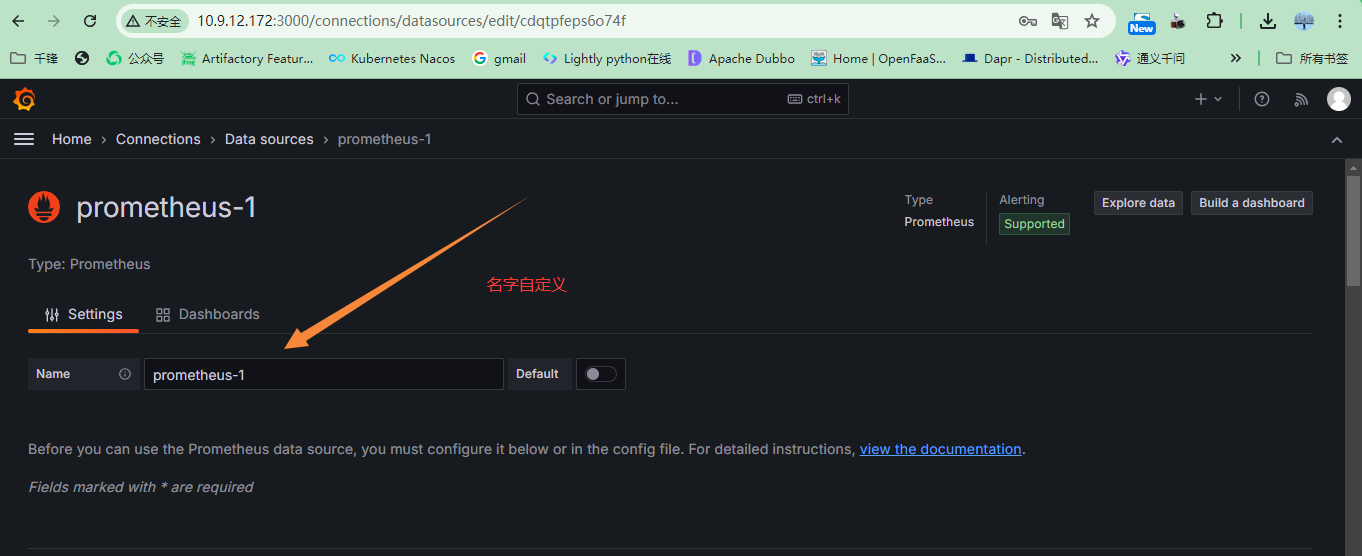
+指定数据源的名字,名字自定义,有意义就可以
+
+
+
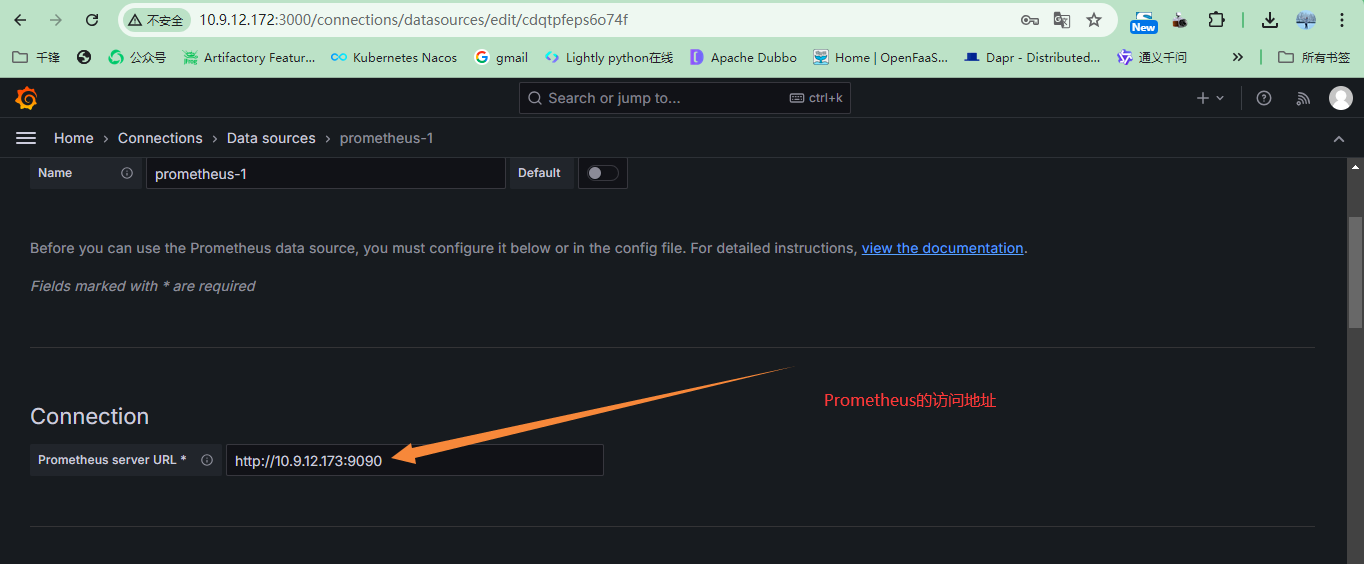
+指定数据源的地址,本案例是Prometheus的地址
+
+
+
+保存及测试
+
+
+
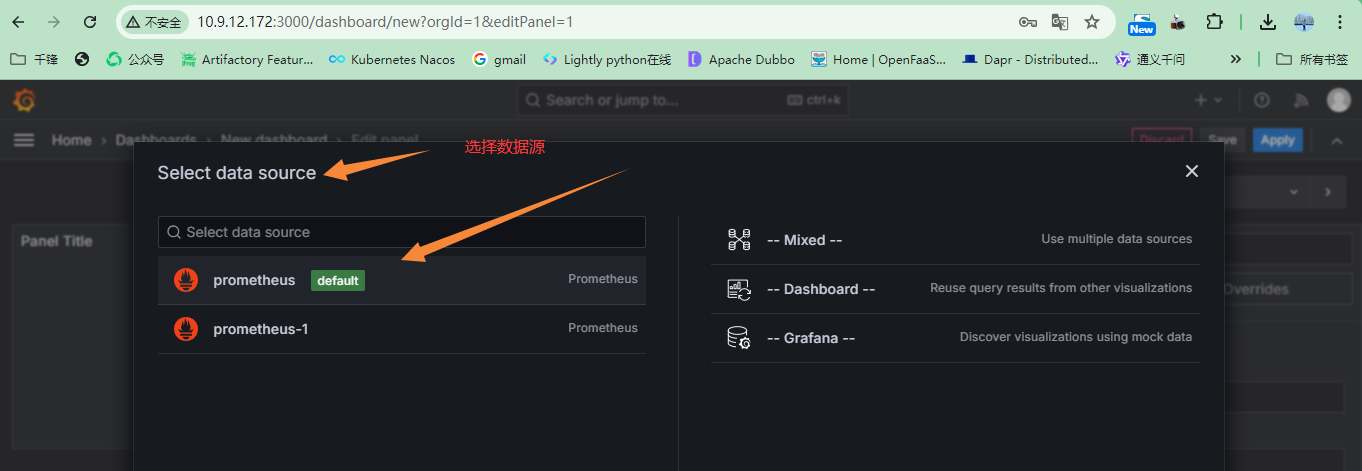
+##### 创建仪表盘
+
+
+
+
+
+
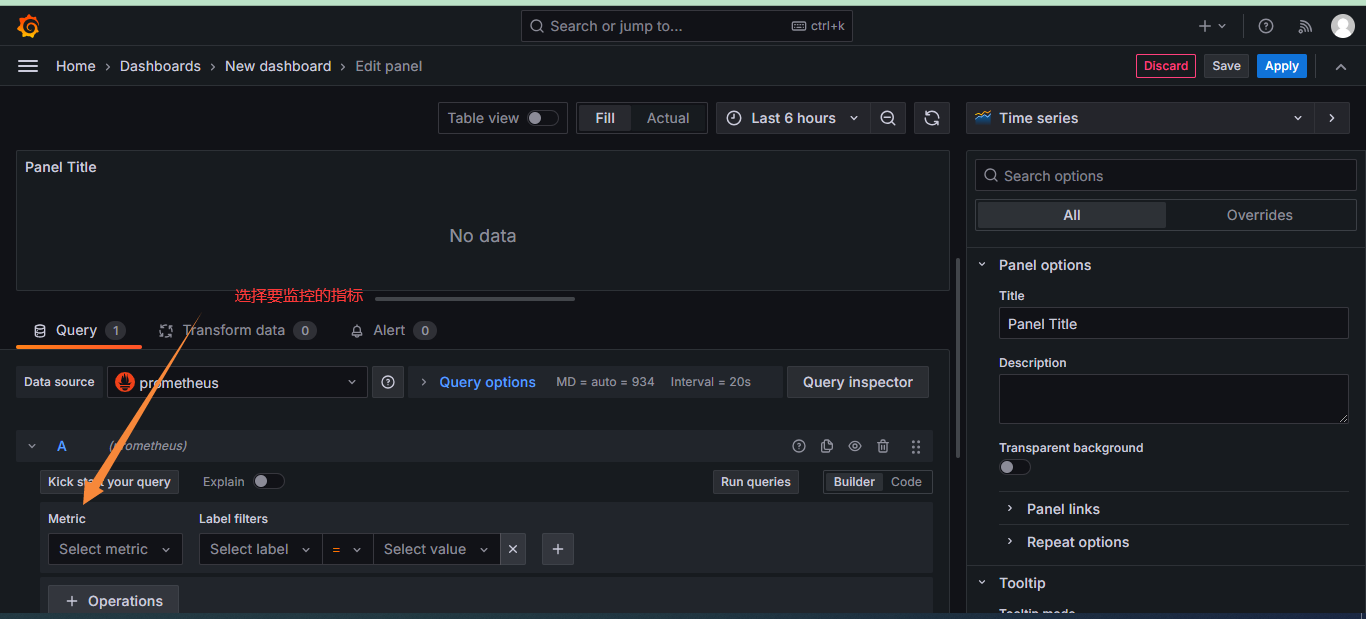
+
+
+
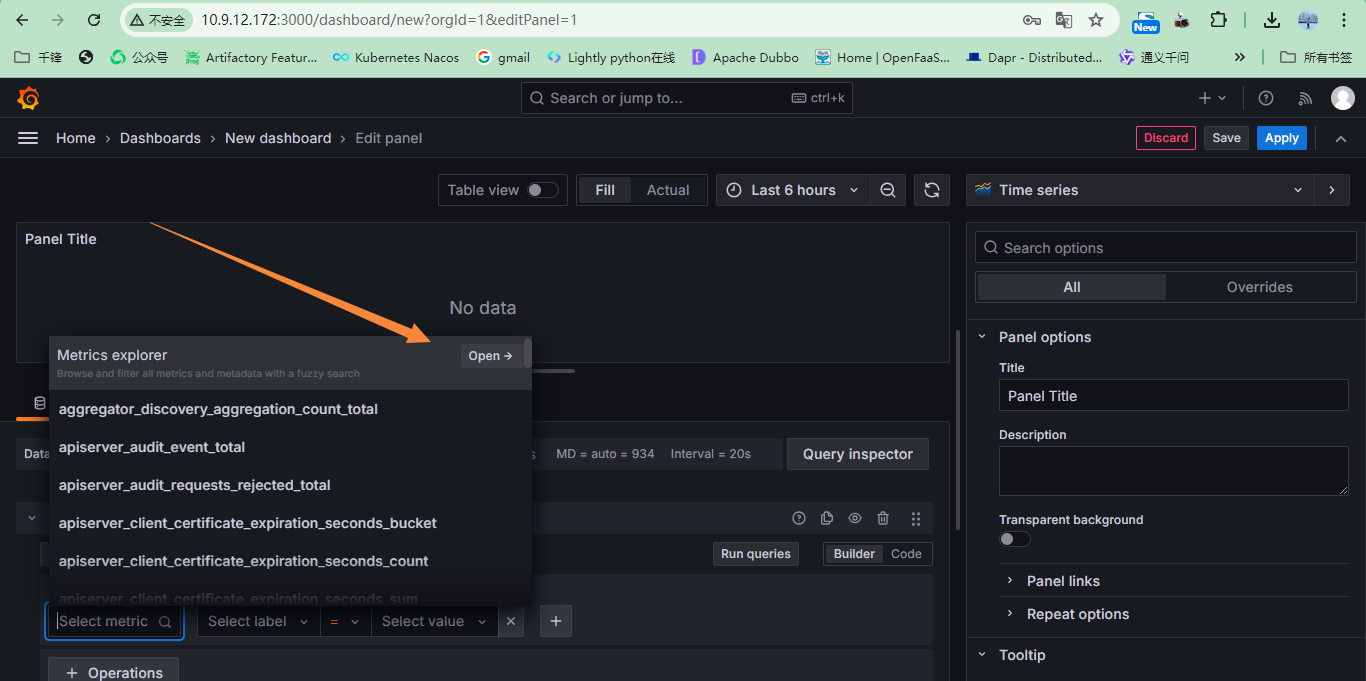
+添加指标:这些指标都来自于Prometheus
+
+
+
+
+
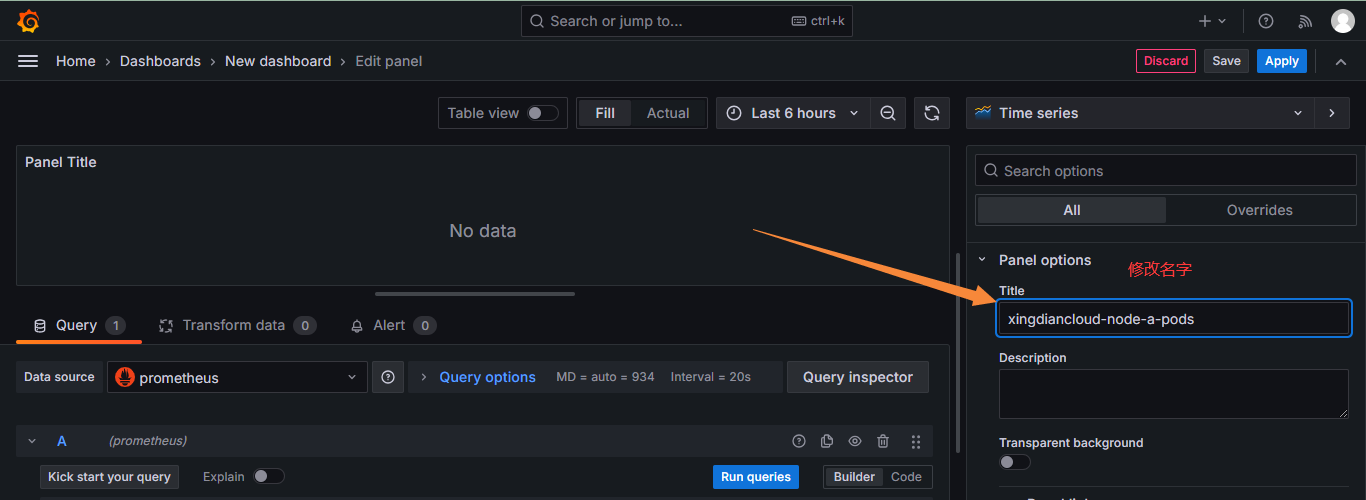
+
+
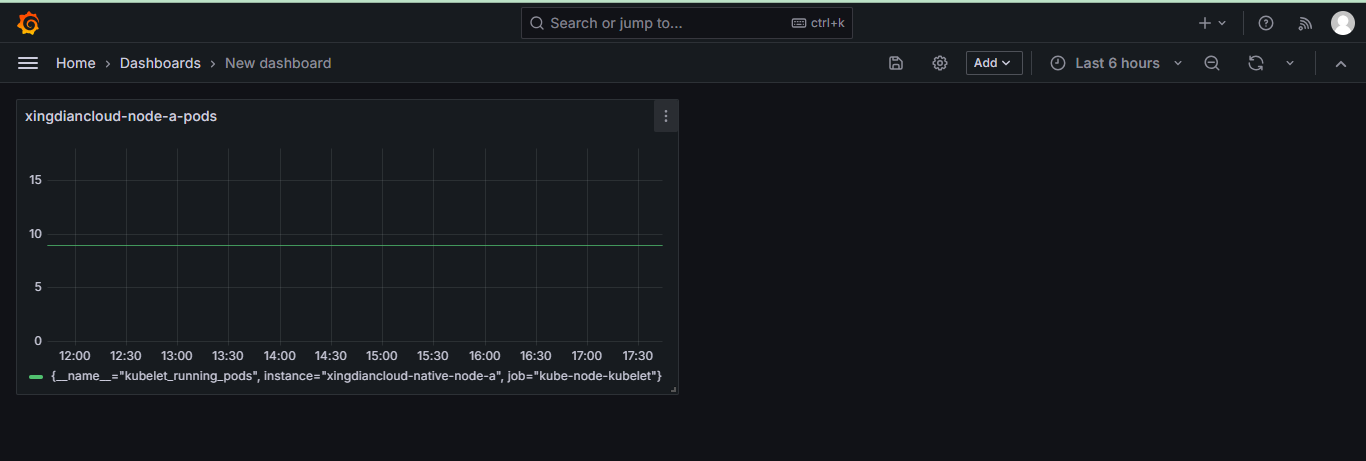
+##### 查看图形
+
+
+
+#### 4.Variables使用
+
+##### 初识变量
+
+ 变量(Variables)一般包含一个或多个可选择的值
+
+ 使用变量我们可以创建出交互式的动态仪表盘
+
+ 类似于Zabbix中的模板
+
+##### 使用原因
+
+ 当用户只想关注其中某些主机时,基于当前我们已经学习到的知识只有两种方式,要么每次手动修改Panel中的PromQL表达式,要么直接为这些主机创建单独的Panel;主机有很多时,需要新建无数的仪表盘来展示不同的主机状态,好在Grafana中有Variables,可以动态修改仪表盘中的参数,这样仪表盘的内容也会随参数的值改变而改变
+
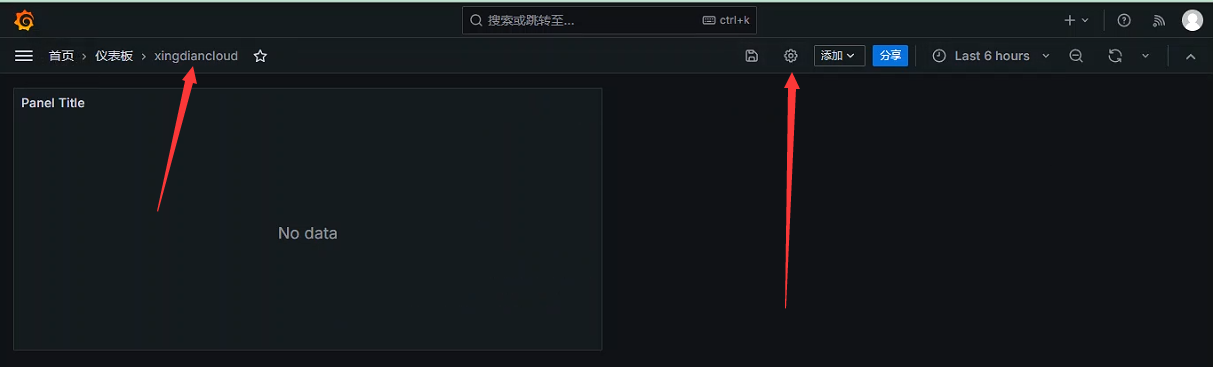
+##### 如何定义
+
+ 通过Dashboard页面的Settings选项,可以进入Dashboard的配置页面并且选择Variables子菜单
+
+
+
+
+
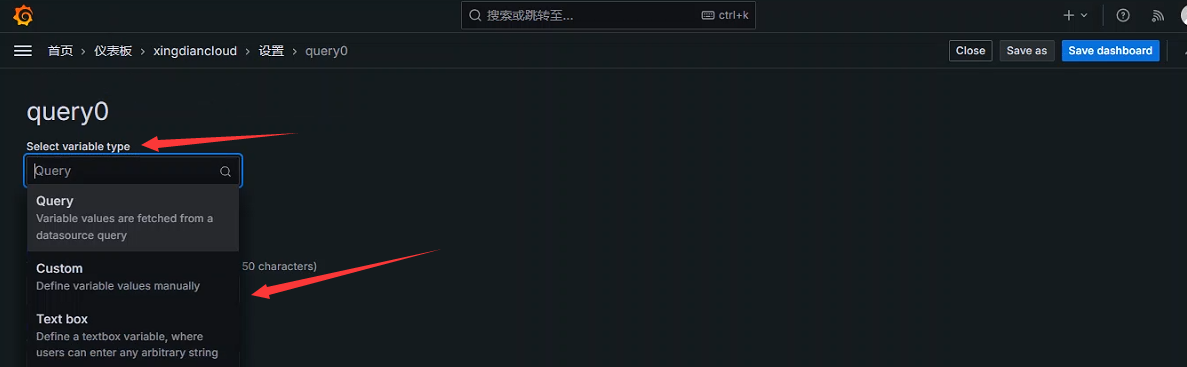
+##### 变量类型
+
+
+
+`Interval`(间隔)此变量可以表示查询的时间跨度,使用interval变量来定义时间间隔
+
+`Query`(查询)此变量用于编写数据源查询,与Query Options中的设置配合使用,通常返回度量名称,标签值等。例如,返回主机或主机组的名称
+
+`Datasource`(数据源)次变量 用于指定数据源,例如有多个zabbix源时,就可以使用此类变量,方便在Dashboard中交互切换数据源,快速显示不同数据源中的数据
+
+`Custom`(自定义)用户自定义设置的变量
+
+`Constant`(常量)定义可以隐藏的常量。对于要共享的仪表盘中包括路径或者前缀很有用。在仪表盘导入过程中。常量变量将成为导入时的选项
+
+`Ad hoc filters`(Ad hoc过滤器)这是一种非常特殊的变量、目前只适用于某些数据源、如InfluxDB、Prometheus、Elasticsearch。使用指定数据源时将自动添加所有度量查询出的键/值
+
+`Text Box`(文本框)次变量用于提供一个可以自由输入的文本框
+
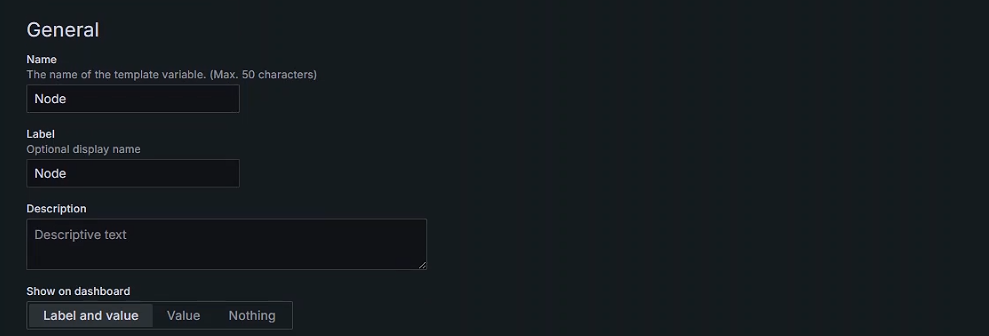
+##### General配置
+
+
+
+- Name(定义变量名称)
+- Label(标签),在仪表盘上显示标签的名字
+- Description (描述),类似于说明书可以省略
+- Show on dashboard (展示在仪表盘)默认展示标签和值
+
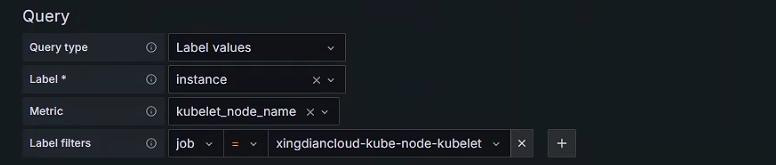
+##### Query options 配置
+
+Data source(可以指定数据源)
+
+
+
+##### Refresh 配置
+
+
+
+##### Selection options 配置
+
+
+
+Multi-value:Enables multiple values to be selected at the same time 允许选择多个值
+
+##### Apply
+
+
+
+##### Kubernetes应用案例
+
+
+
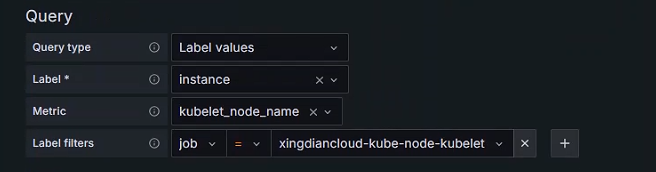
+Node变量
+
+
+
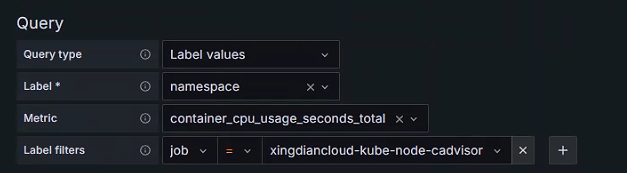
+Namespace变量
+
+
+
+Pod变量
+
+ 注意:Pod变量的上级是Namespace
+
+
+
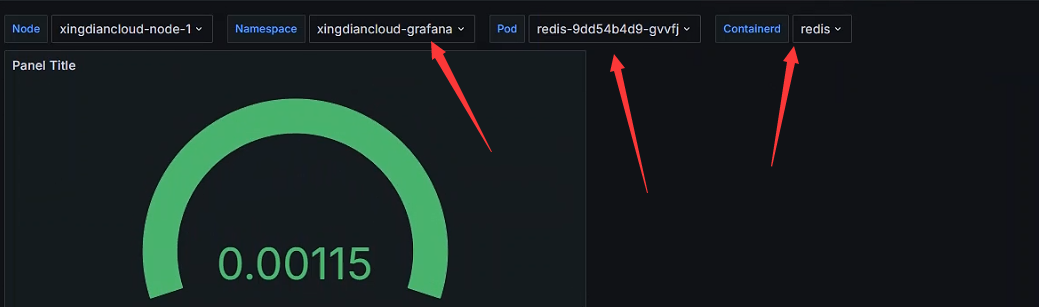
+Containerd变量
+
+ 注意:Containerd变量的上一级是Pod,Pod的上一级是Namespace
+
+
+
+变量在Dashboard中展示
+
+
+
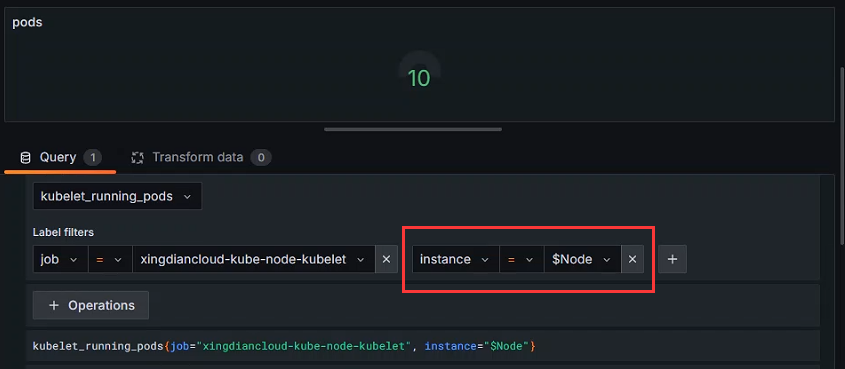
+###### 获取每个节点POD的数量
+
+指标中调用变量
+
+
+
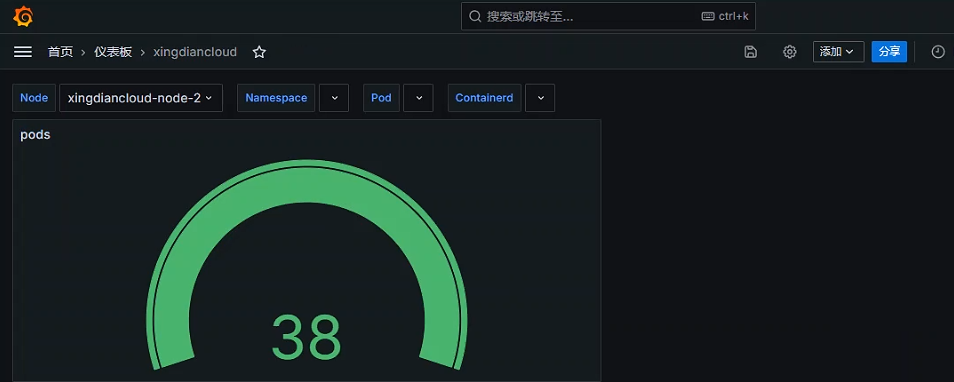
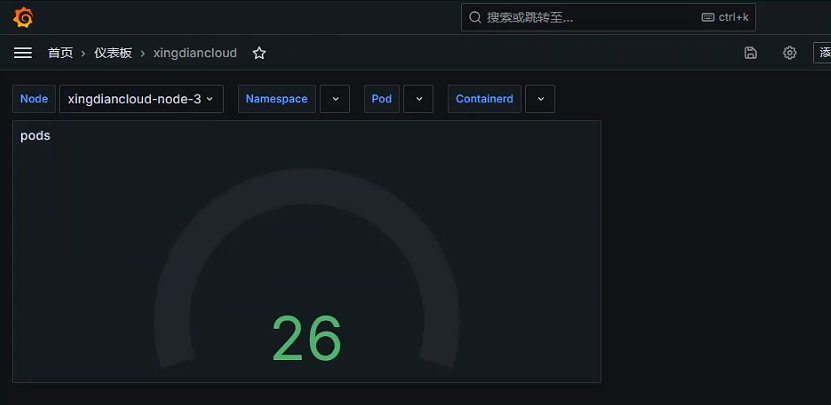
+数据展示
+
+
+
+
+
+###### 每个容器在该时间窗口内的总 CPU 使用率
+
+指标中调用变量
+
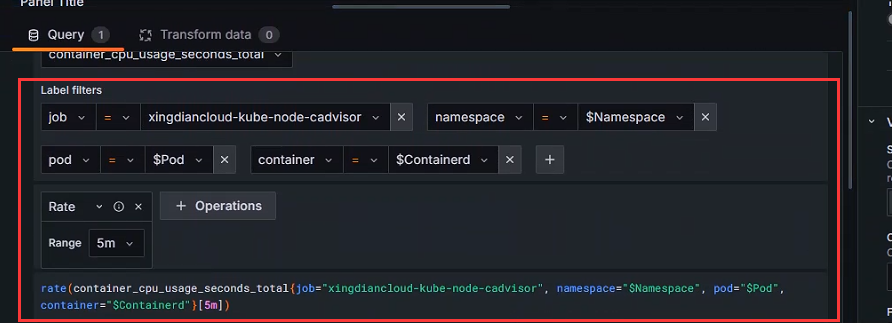
+```shell
+rate(container_cpu_usage_seconds_total{job="xingdiancloud-kube-node-cadvisor", namespace="$Namespace", pod="$Pod", container="$Containerd"}[5m])
+```
+
+
+
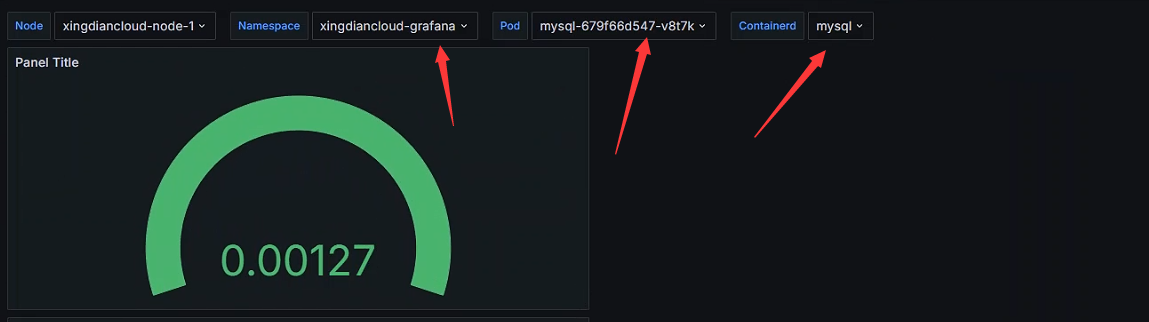
+数据展示
+
+
+
+
+
+## 五:Promql使用
+
+#### 1.Promql简介
+
+ Prometheus 是一个强大的开源监控系统,其查询语言 PromQL (Prometheus Query Language) 允许用户执行灵活的时间序列数据查询和分析
+
+ PromQL是Prometheus提供的一个函数式的表达式语言,可以使用户实时地查找和聚合时间序列数据
+
+ 表达式计算结果可以在图表中展示,也可以在 Prometheus表达式浏览器中以表格形式展示,或者作为数据源以HTTP API的方式提供给外部系统使用
+
+ PromQL虽然以QL结尾,但是它不是类似SQL的语言,因为在时间序列上执行计算类型时,SQL语言相对缺乏表达能力
+
+ PromQL语言表达能力非常丰富,可以使用标签进行任意聚合,还可以使用标签将不同的标签连接到一起进行算术运算操作
+
+ 内置了时间和数学等很多函数可以使用
+
+ 时间序列: 时间序列是 Prometheus 中的核心数据单元。它由一个唯一的 metric 名称和一组键值对标签标识
+
+ 样本: 每个时间序列由多个样本组成。样本包括一个时间戳和一个值
+
+ 指标 : 指标是 Prometheus 中收集的数据类型,有四种:Counter(计数器)、Gauge(仪表盘)、Histogram(直方图)和 Summary(摘要)
+
+#### 2.Promql基本语法
+
+##### 语言数据类型
+
+ Instant vector:瞬时向量,一组time series(时间序列),每个time series包括了一个时间戳的数据点,所有time series数据点拥有相同的时间戳
+
+ Range vector:范围向量,一组time series包含一个时间范围内的一组数据点
+
+ Scalar:标量,为一个浮点数值
+
+ String:字符串,为一个字符串数值;当前未使用
+
+##### Literals数据格式
+
+String literals:字符串可以用单引号(‘’)、双引号(“”)或反引号(``)指定为文字
+
+Float literals:浮点类型数值的格式为:-[.(digits)]
+
+##### Time series(时间序列)选择器
+
+Instant vector selectors(即时矢量选择器)
+
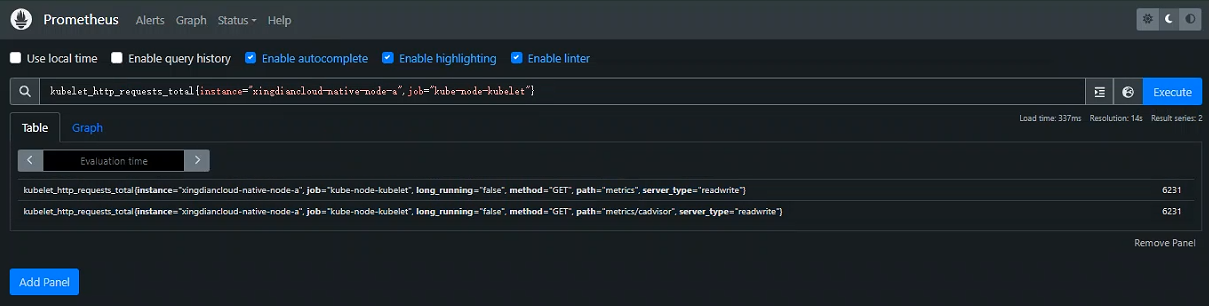
+ 瞬时向量选择器用于选择一组time series和每个time series对应的某一个时间戳数据点,唯一的要求是必须指定metric指标名
+
+案例:查询指标名`kubelet_http_requests_total`对应的所有time series表达式
+
+> 可以通过在花括号 ( {}) 中附加一个逗号分隔的标签匹配器列表来进一步过滤这些时间序列
+>
+> 仅选择具有`kubelet_http_requests_total`度量名称且`instance`标签设置为`xingdiancloud-native-node-a`且其`job`标签设置为的时间序列`kube-node-kubelet`
+
+```promql
+kubelet_http_requests_total{instance="xingdiancloud-native-node-a",job="kube-node-kubelet"}
+```
+
+
+
+通过负匹配或正则表达式匹配tag选择时间序列,支持如下匹配运算符:
+
+> = 等于
+
+> != 不等于
+
+> =~ 选择与提供的字符串进行正则表达式匹配的标签
+
+> !~ 选择与提供的字符串不匹配的标签
+
+##### Range vector selectors(范围矢量选择器)
+
+ 范围向量字面量的工作方式类似于即时向量字面量,唯一区别是选择的时间序列是一个时间范围内的时序数据。从语法上讲,持续时间附加在[]向量选择器末尾的方括号 ( ) 中,以指定应该为每个结果范围向量元素获取多远的时间值
+
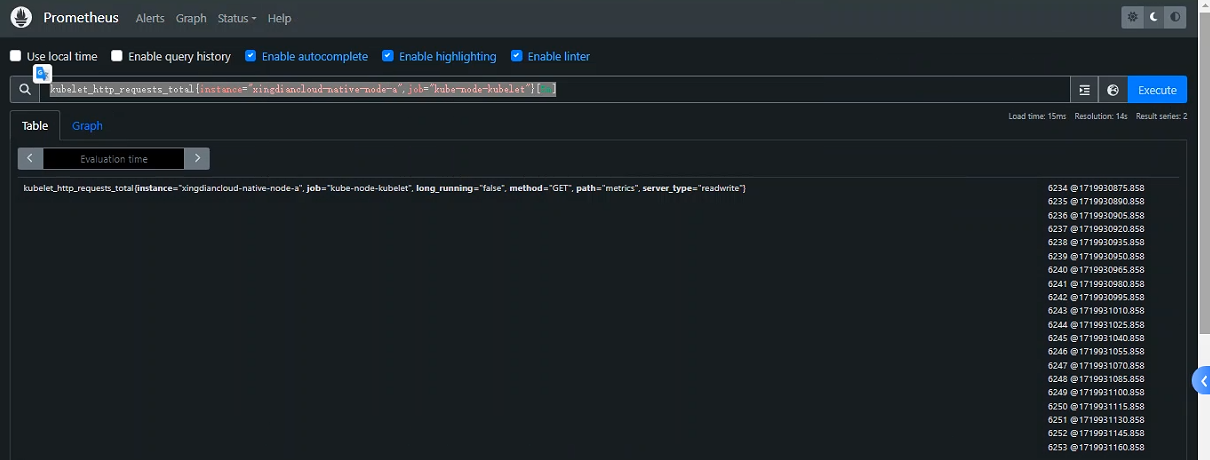
+案例:为所有时间序列选择了过去 5 分钟内记录的所有值,指标名称`kubelet_http_requests_total`和`job`标签设置为`kube-node-kubelet`且`instance`标签设置为`xingdiancloud-native-node-a`
+
+```promql
+kubelet_http_requests_total{instance="xingdiancloud-native-node-a",job="kube-node-kubelet"}[5m]
+```
+
+
+
+##### Offset modifier(偏移修改器)
+
+ Offset修改器允许修改查询中瞬时向量和范围向量的时间偏移
+
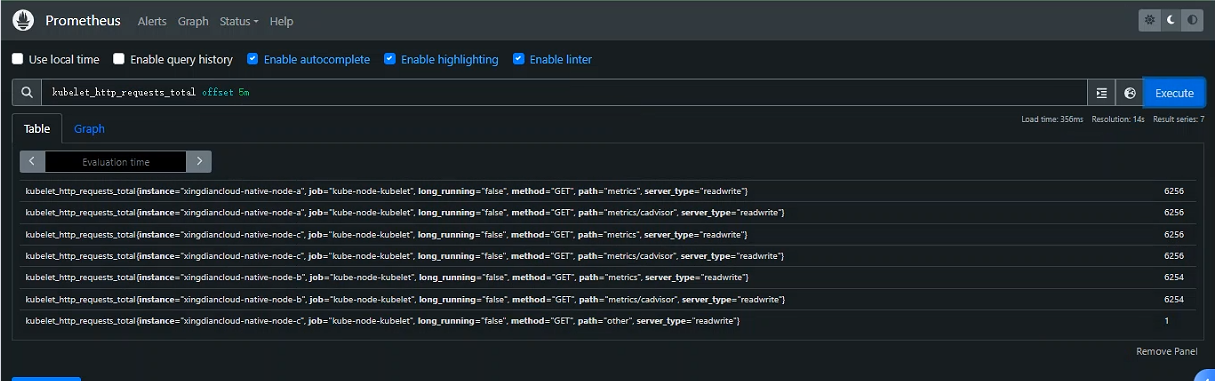
+案例:返回`kubelet_http_requests_total`相对于当前查询评估时间过去 5 分钟的值
+
+注意:offset修饰符总是需要立即跟随选择器
+
+```promql
+kubelet_http_requests_total offset 5m
+```
+
+
+
+##### Subquery(子查询)
+
+ 子查询允许针对给定的范围和分辨率运行即时查询;子查询的结果是一个范围向量
+
+> [ : []] [offset ]
+>
+> 注:是可选的,默认为全局评估间隔
+
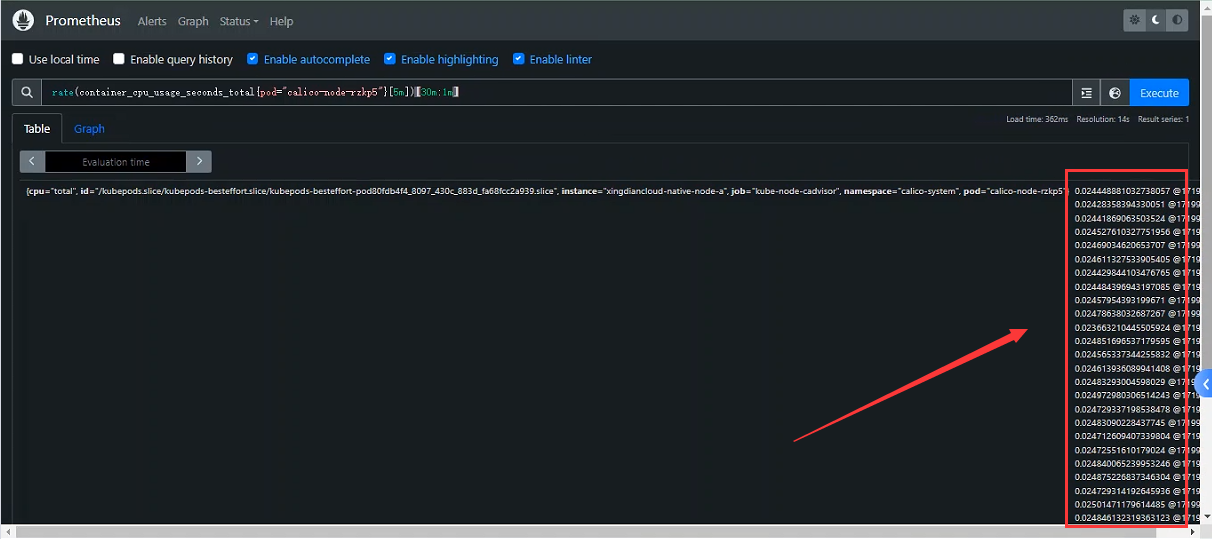
+案例:过去30分钟`container_cpu_usage_seconds_total` 5m统计的rate(平均增长速率)值,精度是1分钟
+
+```promql
+rate(container_cpu_usage_seconds_total{pod="calico-node-rzkp5"}[5m])[30m:1m]
+```
+
+
+
+
+
+#### 3.PromQL运算符
+
+ PromQL支持基本的逻辑和算术运算;对于两个瞬时向量的运算,其结果可能影响匹配行为
+
+##### 算数运算符
+
+> +(加法)
+>
+> \- (减法)
+>
+> \* (乘法)
+>
+> / (除法)
+>
+> %(模数)
+>
+> ^(幂)
+
+##### 匹配运算符
+
+> == (等于)
+>
+> != (不等于)
+>
+> \> (大于)
+>
+> < (小于)
+>
+> \>=(大于或等于)
+>
+> <=(小于或等于)
+>
+> `=~` (正则表达式匹配)
+>
+> `!~` (正则表达式不匹配)
+
+##### 逻辑/集合运算符
+
+> and 过滤出两个向量里都有的时间序列
+>
+> or 过滤出两个向量里所有的时间序列
+>
+> unless 过滤出左边向量里,右边没有的时间序列
+
+##### 聚合运算符
+
+ 支持以下内置聚合运算符,可用于聚合单个即时向量的元素,从而生成具有聚合值的元素更少的新向量
+
+> sum (总和)
+>
+> min (最小值)
+>
+> max (最大值)
+>
+> avg (平均值)
+>
+> group (结果向量中的所有值都是1)
+>
+> stddev (计算维度上的总体标准偏差)
+>
+> stdvar (计算维度上的总体标准方差)
+>
+> count (计算向量中的元素个数)
+>
+> count_values(计算具有相同值的元素个数)
+>
+> bottomk (样本值的最小k个元素)
+>
+> topk (按样本值计算的最大k个元素)
+>
+> quantile (在维度上计算 φ-quantile (0 ≤ φ ≤ 1))
+
+##### 选择运算符
+
+> `{}` (标签选择器)
+>
+> `[]` (时间范围选择器)
+
+##### 集合运算符
+
+> on 指定了应该用于匹配的标签。只有这些标签完全匹配的向量才会被计算在内
+>
+> ignoring 指定了在匹配时应该忽略的标签;除了这些被忽略的标签外,其他标签必须匹配
+>
+> group_left、group_right 用于多对一或一对多的匹配,保留其他不匹配的标签
+
+##### 函数调用
+
+> ```
+> rate() 函数用于计算每秒的平均变化率,通常用于计算每秒钟的平均增长量。它适用于计数器类型的指标,这些指标只会单调递增
+> increase() 函数同样用于计算计数器指标的增长量,但它返回的是指定时间窗口内的增量总和
+> delta() 函数用于计算任意类型指标的增量,它可以计算两个样本点之间的差值
+> irate() 函数用于估计瞬时的变化率,它计算在最近的时间间隔内的变化率。与 rate() 相比,irate() 可以更快速地反映短期的变化趋势
+> ```
+
+##### 运算符优先级
+
+> 聚合运算符
+>
+> 选择运算符
+>
+> 函数调用
+>
+> 逻辑运算符
+>
+> 匹配运算符
+>
+> 算术运算符
+>
+> 集合运算符
+
+案例:
+
+```promql
+sum(rate(kubelet_http_requests_total{job="kube-node-kubelet"}[5m])) / sum(rate(kubelet_http_requests_total[5m]))
+```
+
+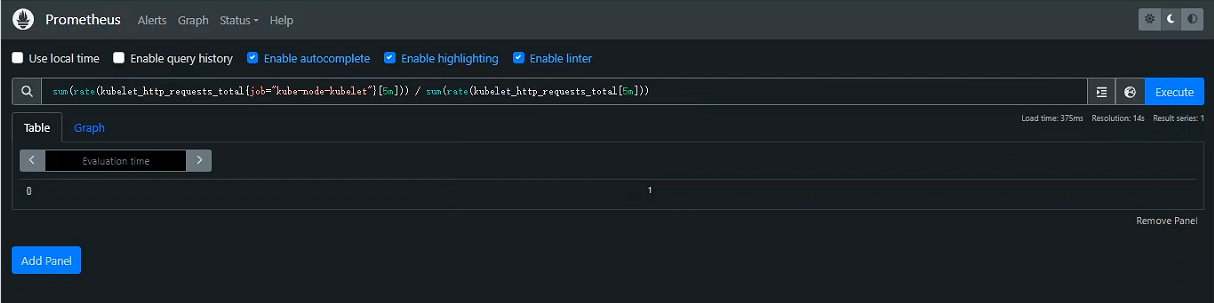
+
+> `rate(kubelet_http_requests_total{job="kube-node-kubelet"}[5m])` 和 `rate(kubelet_http_requests_total[5m])` 中的选择运算符 `[]` 具有最高优先级
+
+> 然后是函数调用 `rate()`
+
+> 接下来是聚合运算符 `sum()`
+
+> 最后是算术运算符 `/`
+
+总结:了解这些优先级可以帮助你更准确地构建 PromQL 查询,确保查询按预期顺序执行
+
+#### 4.PromQL内置函数
+
+ 一些函数有默认参数,例如`year(v=vector(time()) instant-vector)`;这意味着有一个参数v是一个即时向量,如果没有提供,它将默认为表达式的值`vector(time())`
+
+> abs():`abs(v instant-vector)`返回输入向量,其中所有样本值都转换为其绝对值
+
+> absent():`absent(v instant-vector)`如果传递给它的瞬时向量有任何元素,则返回一个空向量;如果传递给它的向量没有元素,则返回一个值为 1 的 1 元素向量;通常用于设置告警,判断给定的指标和标签没有数据时产生告警
+
+> absent_over_time():`absent_over_time(v range-vector)`如果传递给它的范围向量有任何元素,则返回一个空向量;如果传递给它的范围向量没有元素,则返回一个值为 1 的 1 元素向量;同absent(),常用于判断指标与标签组合,不存在于时间序列时报警
+
+> ceil():`ceil(v instant-vector)`将所有元素的样本值四舍五入到最接近的整数
+
+> changes():`changes(v range-vector)`计算给出的时间范围内,value是否发生变化,将发生变化时的条目作为即时向量返回
+
+> clamp():`clamp(v instant-vector, min scalar, max scalar)`设定所有元素的样本值的上限与下限注:当min>max时,返回一个空向量:NaN if min or max is NaN
+
+> day_of_month():`day_of_month(v=vector(time()) instant-vector)`以 UTC 格式返回每个给定时间的月份日期,返回值从 1 到 31
+
+> day_of_week():`day_of_week(v=vector(time()) instant-vector)`以 UTC 格式返回每个给定时间的星期几,返回值从 0 到 6,其中 0 表示星期日
+
+> days_in_month():`days_in_month(v=vector(time()) instant-vector)`以 UTC 格式返回每个给定时间该月的天数,返回值从 28 到 31
+
+> delta():`delta(v range-vector)`计算范围向量中每个时间序列元素的第一个值和最后一个值之间的差,返回具有给定增量和等效标签的即时向量;增量被外推以覆盖范围向量选择器中指定的整个时间范围,因此即使样本值都是整数,也可以获得非整数结果
+
+案例:
+
+ 监控容器 CPU 使用情况的指标。具体来说,它表示容器在系统模式下使用的总 CPU 时间(以秒为单位)
+
+ 现在跟2个小时前的差异
+
+```promql
+delta(container_cpu_system_seconds_total{pod="calico-node-pwlrv"}[2h])
+```
+
+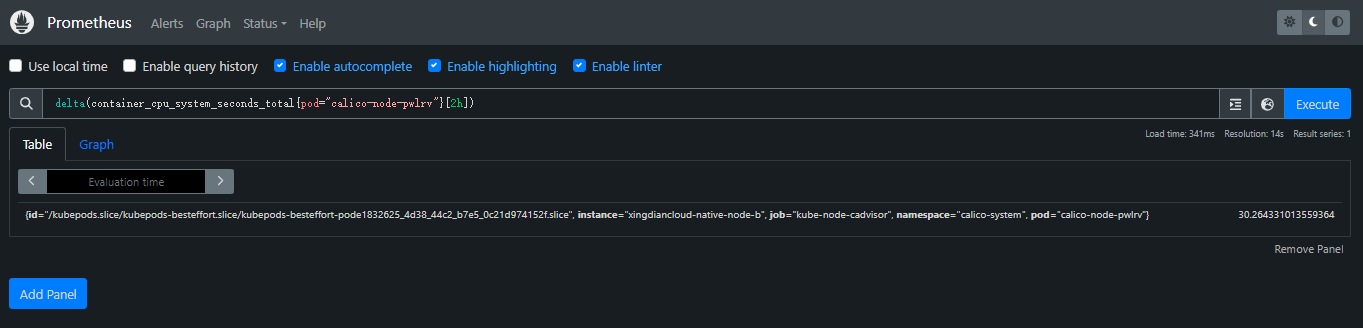
+
+> **container**:表示特定容器的 CPU 使用情况
+>
+> **cpu**:表示 CPU 资源
+>
+> **system_seconds_total**:系统模式下使用的总 CPU 时间,系统模式指的是操作系统内核执行的时间。
+
+
+
+> deriv(): deriv(v range-vector) 使用简单线性回归的方法计算时间序列在范围向量 中的每秒导数
+>
+> 注:deriv()函数在可视化页面上只能用于仪表盘
+
+> exp(): exp(v instant-vector) 计算v中所有元素的指数函数
+
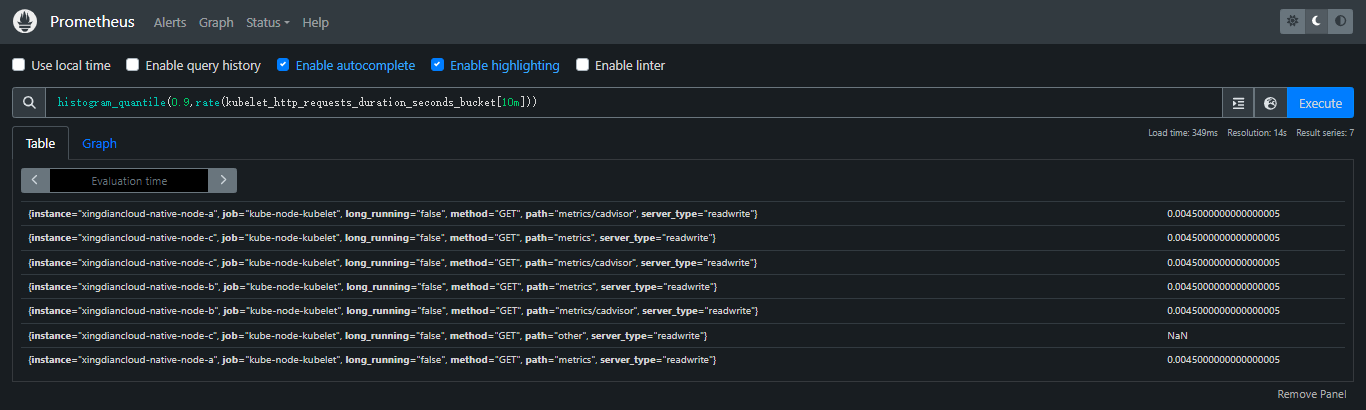
+> histogram_quantile():分位直方图; histogram_quantile(φ scalar, b instant-vector) 从instant vector中获取数据计算q分位(0<= q <=1);b里的样本是每个桶的计数。每个样本必须具有标签le,表示桶的上限。直方图指标类型会自动提供了_bucket后缀和相应tags的time series;使用rate()函数指定分位计算的时间窗口
+
+案例:指标名为`kubelet_http_requests_duration_seconds_bucket`,计算其对应所有time series过去10分钟90分位数
+
+```promql
+histogram_quantile(0.9,rate(kubelet_http_requests_duration_seconds_bucket[10m]))
+```
+
+
+
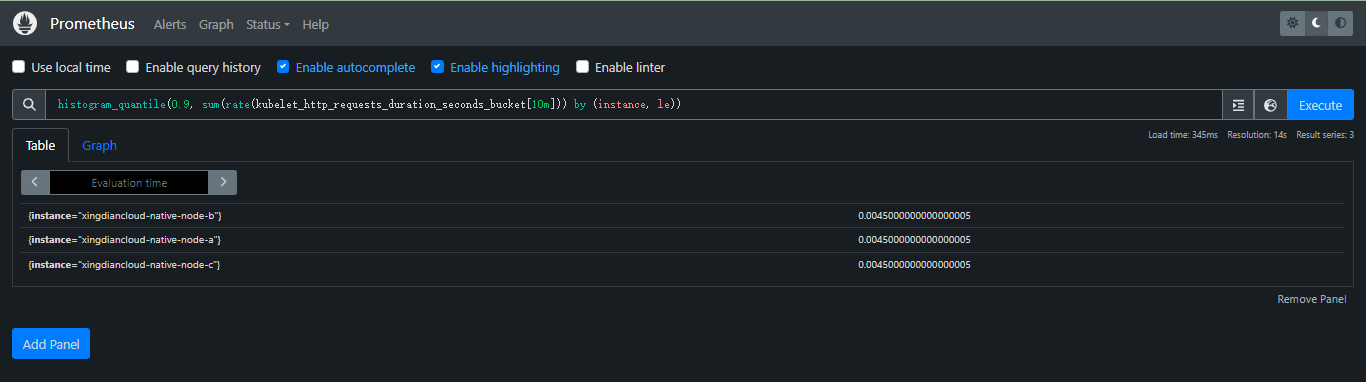
+案例:指标名`kubelet_http_requests_duration_seconds_bucket`对应的每个tags组合(每个time series)计算90分位数;为了聚合数据,比如使用sum()进行聚合,需要通过by子句包含le标签
+
+```promql
+histogram_quantile(0.9, sum(rate(kubelet_http_requests_duration_seconds_bucket[10m])) by (instance, le))
+```
+
+
+
+
+
+> hour(): hour(v=vector(time()) instant-vector) 以 UTC 格式返回每个给定时间的一天中的小时,返回值从 0 到 23
+
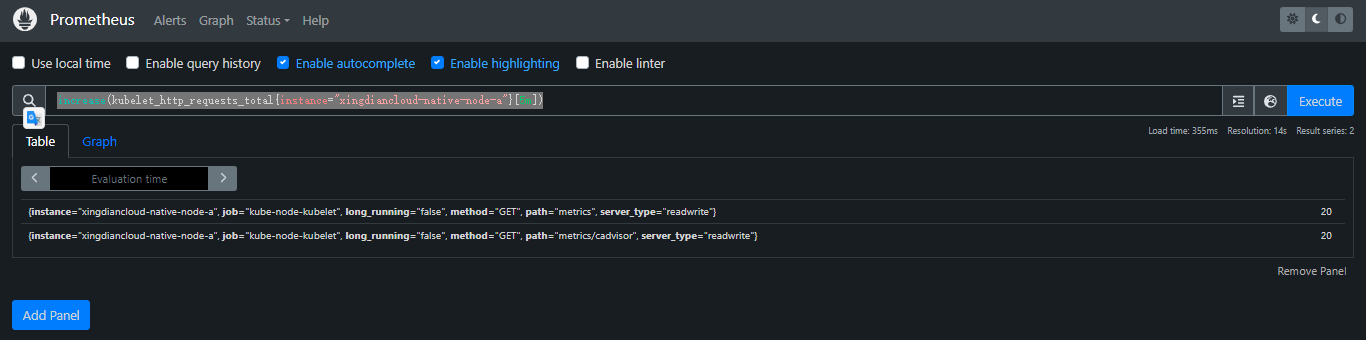
+> increase(): increase(v range-vector) 计算范围向量中时间序列的增量。单调性的中断(例如由于目标重新启动而导致的计数器重置)会自动调整。该增加被外推以覆盖范围向量选择器中指定的整个时间范围,因此即使计数器仅增加整数增量,也可以获得非整数结果
+
+案例:返回范围向量中每个时间序列在过去 5 分钟内测量的 HTTP 请求数
+
+```
+increase(kubelet_http_requests_total{instance="xingdiancloud-native-node-a"}[5m])
+```
+
+
+
+> 注:increase只能与counter类型指标(按增长率展示,即相邻两个时间点的差值除以时间差)一起使用。它是rate(v)乘以指定时间范围窗口下的秒数(相当于rate()乘以秒数),更易于人类理解。在记录规则中使用rate,以便每秒一致地跟踪增长。
+
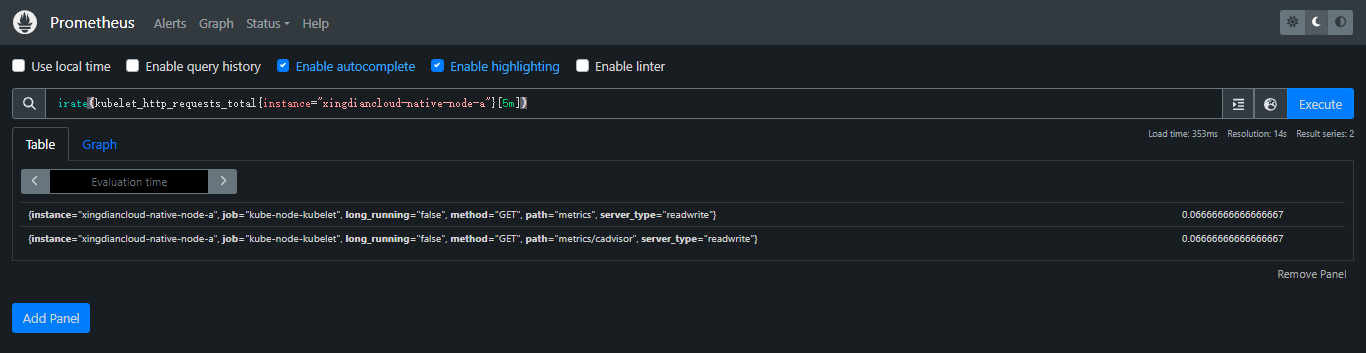
+> irate():`irate(v range-vector)`计算范围向量中时间序列的每秒瞬时增长率。这是基于最后两个数据点。单调性的中断(例如由于目标重新启动而导致的计数器重置)会自动调整
+
+案例:返回针对范围向量中每个时间序列的两个最近数据点的 HTTP 请求的每秒速率,最多可追溯 5 分钟(瞬时增长速率)
+
+```promql
+irate(kubelet_http_requests_total{instance="xingdiancloud-native-node-a"}[5m])
+```
+
+
+
+> 注:irate仅应在绘制易失性、快速移动的计数器时使用。用于rate警报和缓慢移动的计数器,因为速率的短暂变化可以重置
+
+
+
+> ln():ln(v instant-vector) 计算v中所有元素的自然对数
+
+> log2():log2(v instant-vector) 计算v中所有元素的二进制对数
+
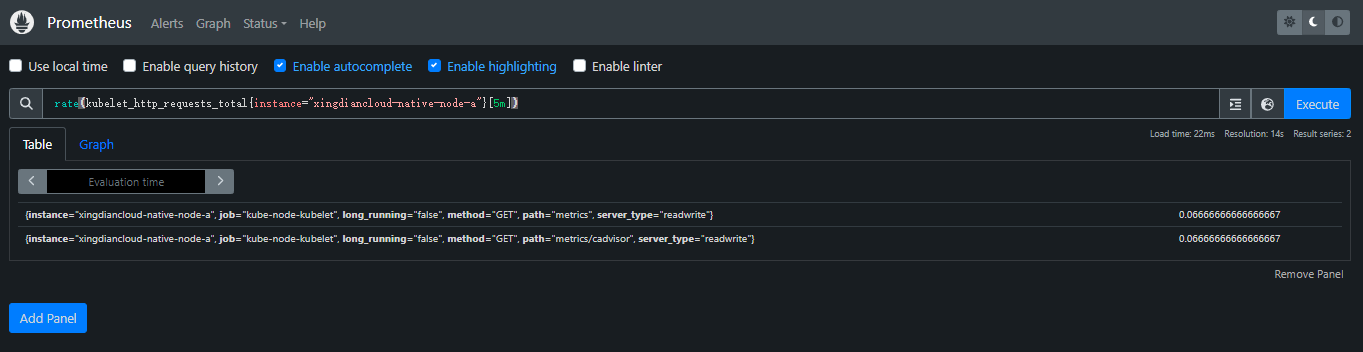
+> rate(): rate(v range-vector) 计算范围向量中时间序列的每秒平均增长率。单调性的中断(例如由于目标重新启动而导致的计数器重置)会自动调整。此外,计算推断到时间范围的末端,允许错过刮擦或刮擦周期与该范围的时间段的不完美对齐
+
+案例:返回在过去 5 分钟内测量的每秒 HTTP 请求速率,范围向量中的每个时间序列
+
+```派人快马起来、
+rate(kubelet_http_requests_total{instance="xingdiancloud-native-node-a"}[5m])
+```
+
+
+
+
+
+> resets():resets(v range-vector) 对于每个输入时间序列,resets(v range-vector)将提供的时间范围内的计数器重置次数作为即时向量返回。两个连续样本之间值的任何减少都被解释为计数器复位;
+>
+> 注意:resets()只能作用于counter类型指标
+
+> round():round(v instant-vector, to_nearest=1 scalar) 将所有元素的样本值四舍五入为v最接近的整数。平局通过四舍五入解决。可选to_nearest参数允许指定样本值应该四舍五入的最接近的倍数。这个倍数也可以是分数。默认为1
+
+> scalar(): scalar(v instant-vector) 给定一个单元素输入向量,scalar(v instant-vector)以标量形式返回该单元素的样本值。如果输入向量没有恰好一个元素,scalar将返回NaN
+
+> sort():sort(v instant-vector) 返回按样本值升序排序的向量元素
+
+> time(): time() 返回自 1970 年 1 月 1 日 UTC 以来的秒数。请注意,这实际上并不返回当前时间,而是要计算表达式的时间
+
+> year():year(v=vector(time()) instant-vector) 以 UTC 格式返回每个给定时间的年份
+
+#### 5.相关案例
+
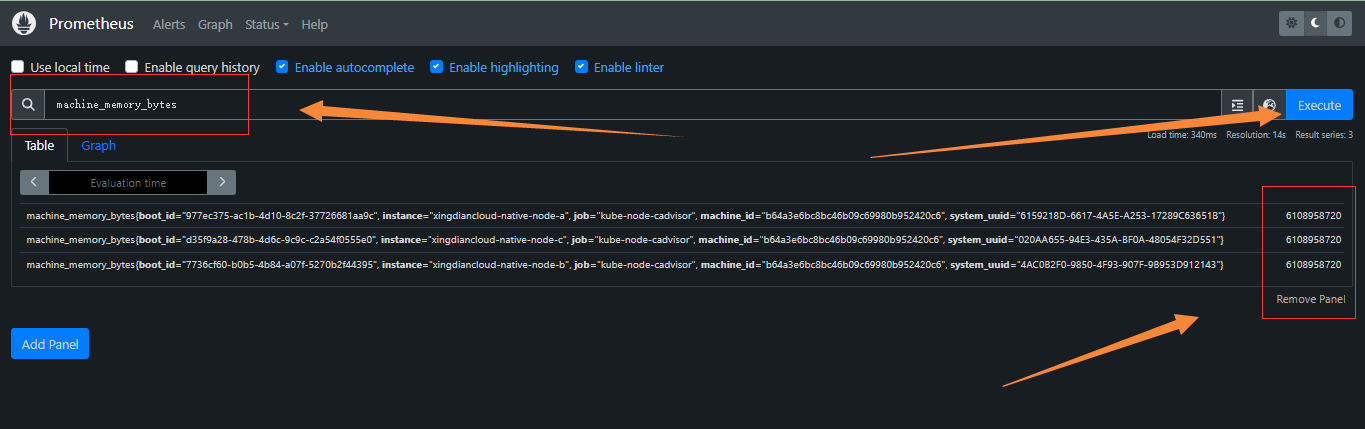
+**获取被监控的服务器内存的总量**
+
+```promql
+machine_memory_bytes
+```
+
+
+
+上图中每一行都是一个服务器的内存总量指标数据,后面是具体的值,单位: 字节。
+
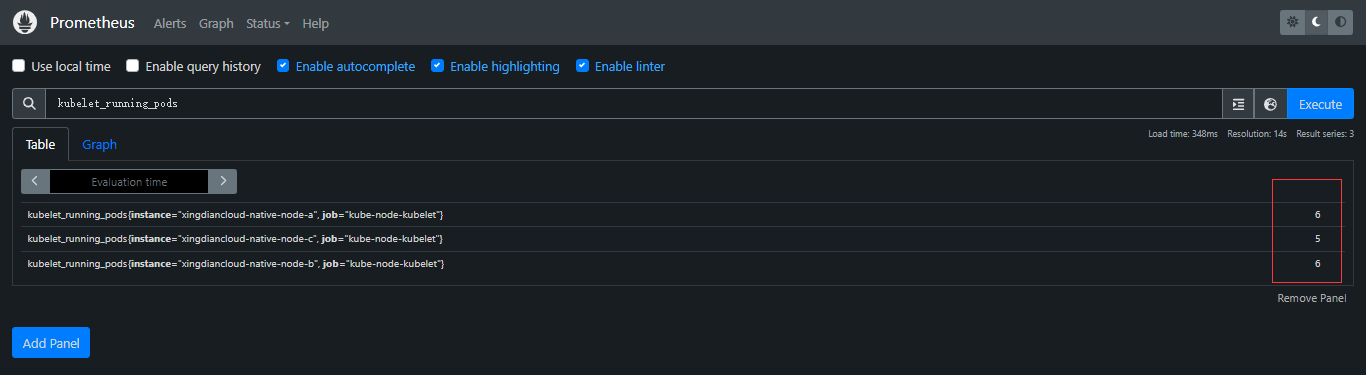
+**获取被监控节点每个节点POD数量**
+
+```promql
+kubelet_running_pods
+```
+
+
+
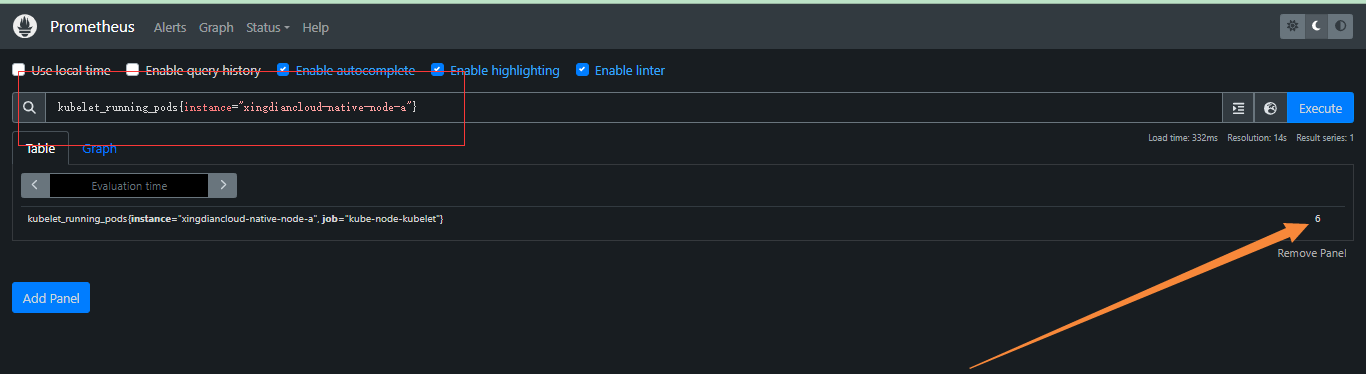
+**获取其中某一个节点POD数量**
+
+```promql
+kubelet_running_pods{instance="xingdiancloud-native-node-a"}
+```
+
+
+
+注意:`instance` 是一个标签,用来表示数据来源的实例。它通常用于区分不同的主机、服务器或服务实例;在 PromQL 查询中,`instance` 标签常用于筛选、分组和聚合来自不同实例的监控数据
+
+#### 基本查询
+
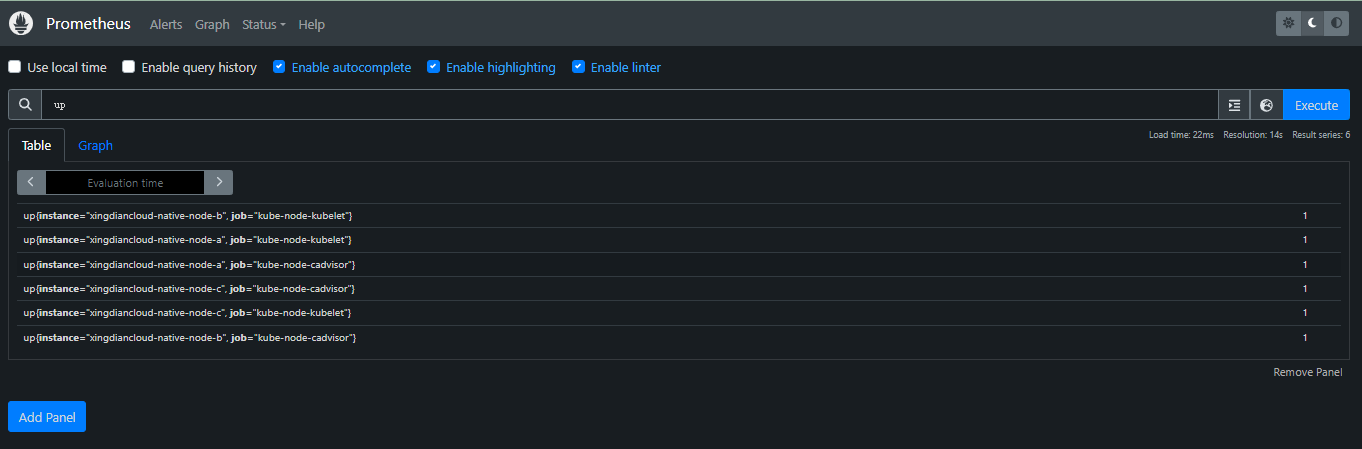
+**查询某个时间序列的最新值**
+
+```promql
+up
+```
+
+`up` 是一个内置指标,表示目标是否处于活动状态
+
+
+
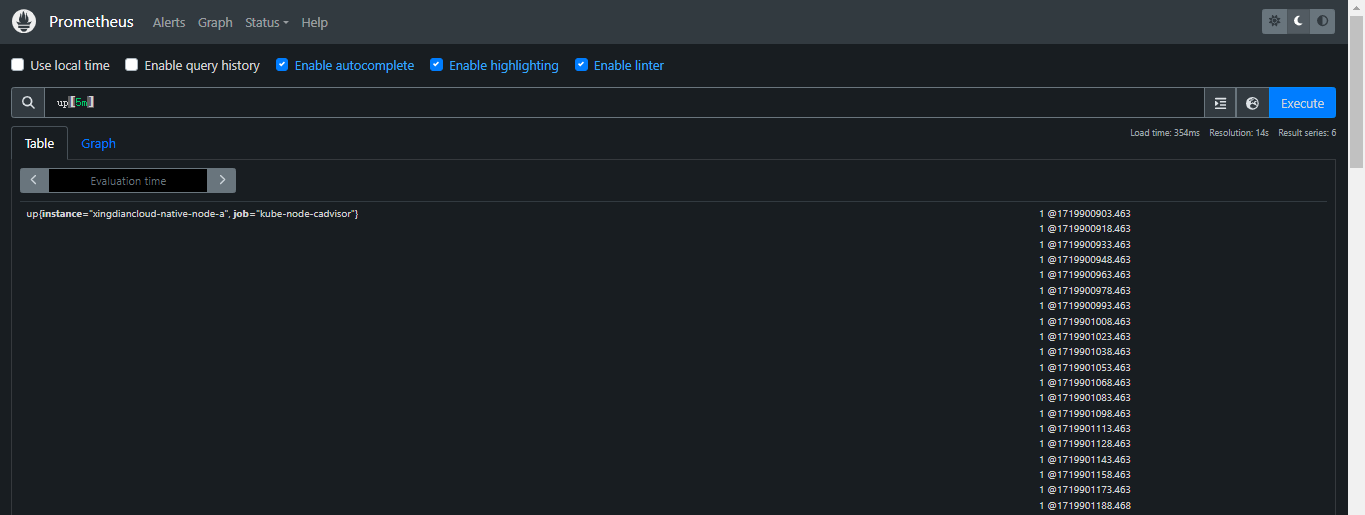
+**查询某个时间序列的所有数据点**
+
+```promql
+up[5m]
+```
+
+
+
+案例二:
+
+**自带指标**
+
+
+
+
+
+#### 比率和变化率
+
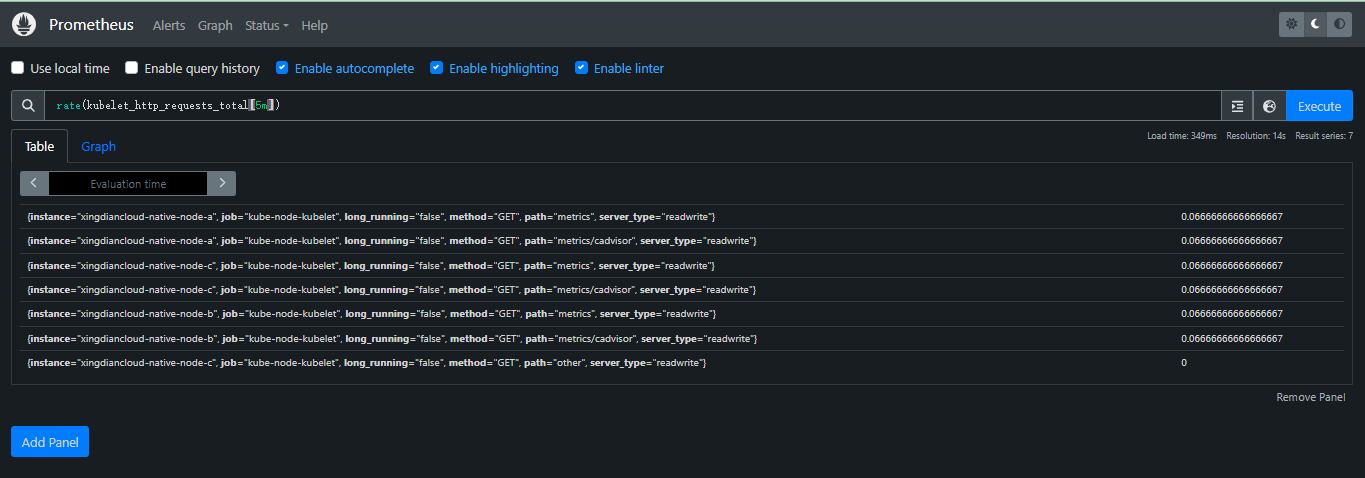
+**计算指标在过去 5 分钟内每秒的变化率**
+
+```promql
+rate(kubelet_http_requests_total[5m])
+
+kubelet_http_requests_total: 这个指标表示 Kubelet 处理的 HTTP 请求的总数。
+rate(): 这个函数用于计算时间序列的平均速率。它需要一个时间范围作为参数。
+[5m]: 这个时间范围表示计算过去 5 分钟内的数据。
+```
+
+
+
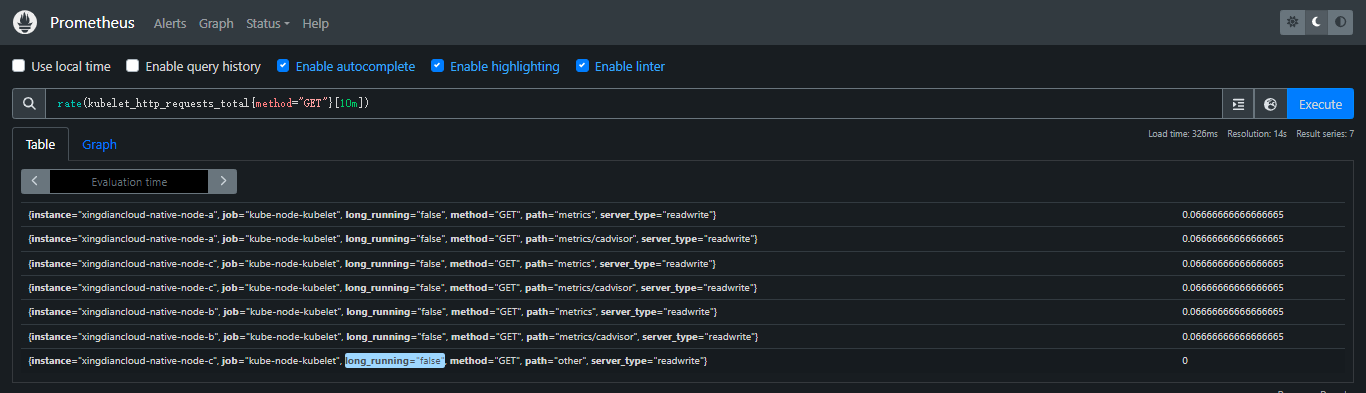
+##### 扩展了解
+
+如果`kubelet_http_requests_total`指标包含`method`标签,你可以按 HTTP 方法分组查看请求速率:
+
+```promql
+rate(kubelet_http_requests_total{method="GET"}[5m])
+```
+
+
+
+如果 `kubelet_http_requests_total` 指标包含 `code` 标签,你可以按状态码分组查看请求速率
+
+```
+rate(kubelet_http_requests_total{code="200"}[5m])
+```
+
+## 六:企业案例
+
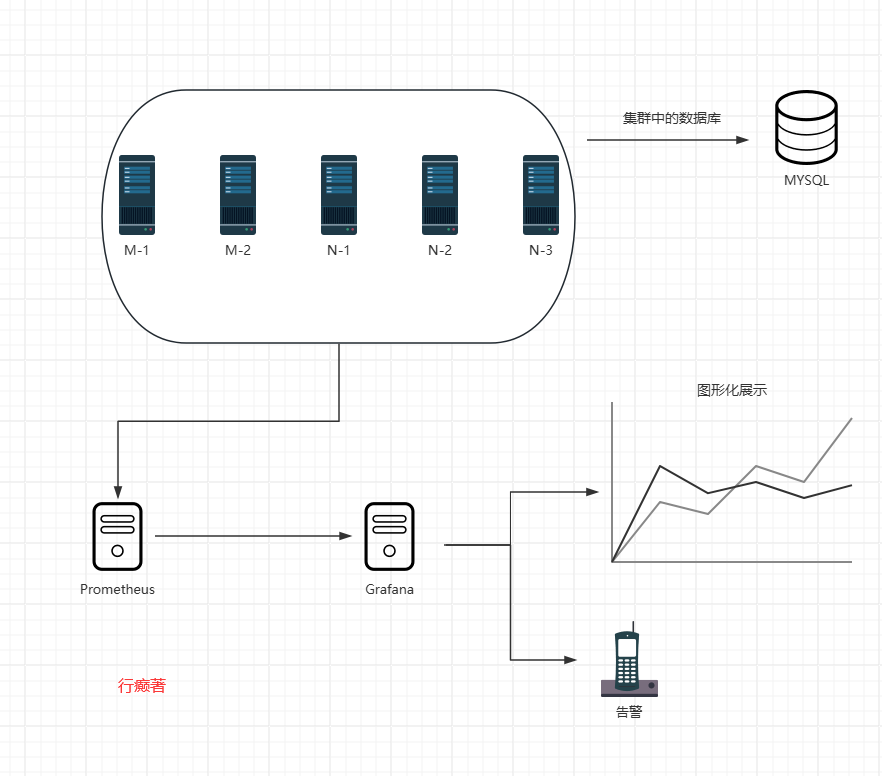
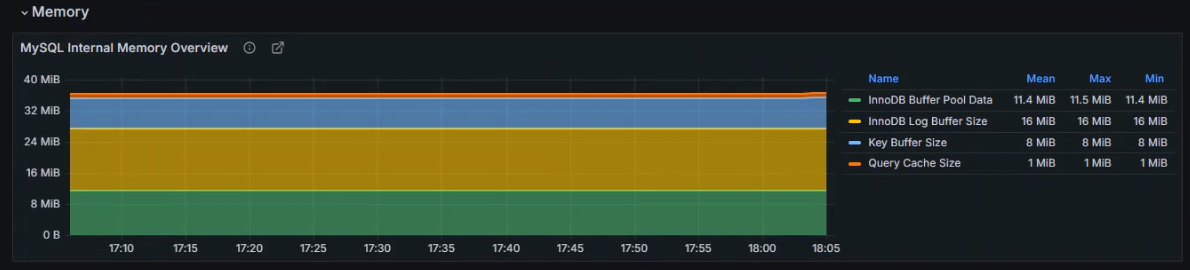
+#### 1.监控Kubernetes集群中数据库MYSQL应用
+
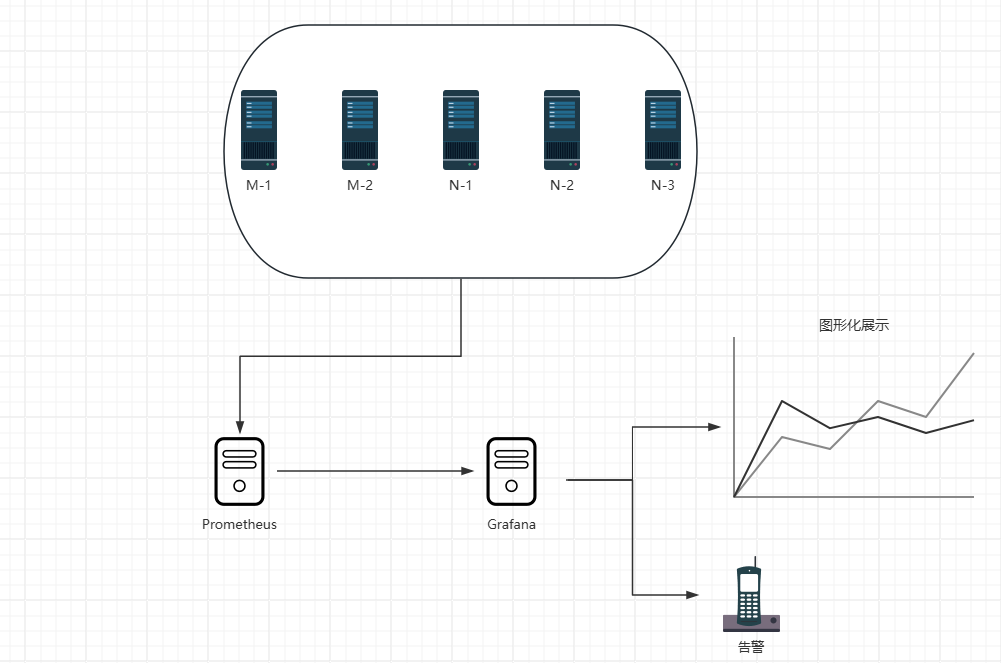
+ 在现代应用中,MySQL数据库的性能和稳定性对业务至关重要;有效的监控可以帮助预防问题并优化性能;Prometheus作为一款强大的开源监控系统,结合Grafana的可视化能力,可以提供全面的MySQL监控方案
+
+##### 集群架构
+
+
+
+##### 部署Mysql-exporter
+
+###### 部署方式
+
+ 部署在Kubernetes集群内部(采用)
+
+ 基于物理服务器单独部署
+
+###### 简介
+
+ MySQL Exporter 是一个专门用于从 MySQL 数据库收集性能和运行状况指标,并提供给Prometheus的工具
+
+ 帮助用户监控 MySQL 数据库的各种指标,如查询性能、连接数、缓存命中率、慢查询等
+
+###### 功能
+
+ 收集 MySQL 服务器的全局状态、InnoDB 状态、表和索引统计信息等
+
+ 收集与性能相关的指标,如查询执行时间、连接数、缓存使用情况等
+
+ 支持自定义查询,用户可以定义自己的查询以收集特定指标
+
+ MySQL Exporter 将收集到的指标以 Prometheus 可读的格式暴露出来,供 Prometheus 抓取
+
+ 提供了丰富的指标标签,便于在 Prometheus 中进行查询和分析
+
+###### 常见 MySQL Exporter 指标
+
+ `mysql_global_status_uptime`: MySQL 服务器的运行时间
+
+ `mysql_global_status_threads_connected`: 当前连接的线程数
+
+ `mysql_global_status_threads_connected`: 当前连接的线程数
+
+ `mysql_global_status_slow_queries`: 慢查询的数量
+
+ `mysql_global_status_queries`: 总查询数
+
+###### 安装部署
+
+前提:Kubernetes集群正常运行,本次安装在Kubernetes集群内部,对应的yaml文件如下
+
+```yaml
+[root@xingdiancloud-master mysql-exporter]# cat mysql-exporter.yaml
+apiVersion: v1
+kind: Secret
+metadata:
+ name: mysql-exporter-secret
+type: Opaque
+data:
+ mysql_user: cm9vdA== # base64 encoded value of your MySQL username
+ mysql_password: MTIzNDU2 # base64 encoded value of your MySQL password
+
+
+---
+apiVersion: v1
+kind: Service
+metadata:
+ name: mysql-exporter-service
+ labels:
+ app: mysql-exporter
+spec:
+ type: NodePort
+ ports:
+ - name: mysql-exporter
+ port: 9104
+ targetPort: 9104
+ nodePort: 30182
+ selector:
+ app: mysql-exporter
+
+---
+apiVersion: apps/v1
+kind: Deployment
+metadata:
+ name: mysql-exporter
+spec:
+ selector:
+ matchLabels:
+ app: mysql-exporter
+ template:
+ metadata:
+ labels:
+ app: mysql-exporter
+ spec:
+ containers:
+ - name: mysql-exporter
+ #image: prom/mysqld-exporter
+ image: 10.9.12.201/xingdian/mysql-exporter
+ env:
+ - name: DATA_SOURCE_NAME
+ value: "root:123456@(10.9.12.206:30180)/"
+ - name: DATA_SOURCE_PASS
+ valueFrom:
+ secretKeyRef:
+ name: mysql-exporter-secret
+ key: mysql_password
+ ports:
+ - containerPort: 9104
+```
+
+```shell
+[root@xingdiancloud-master mysql-exporter]# kubectl create -f mysql-exporter.yaml
+```
+
+##### 关联Prometheus
+
+前提:Prometheus已经安装完成并正常运行,参考第二部分,配置文件如下
+
+```
+scrape_configs:
+ # The job name is added as a label `job=` to any timeseries scraped from this config.
+ - job_name: 'xingdiancloud-mysql-exporter'
+ scrape_interval: 15s
+ static_configs:
+ - targets: ['10.9.12.206:30182']
+```
+
+##### 案例
+
+注意:
+
+ 所有案例最终将在Grafana中进行展示和分析
+
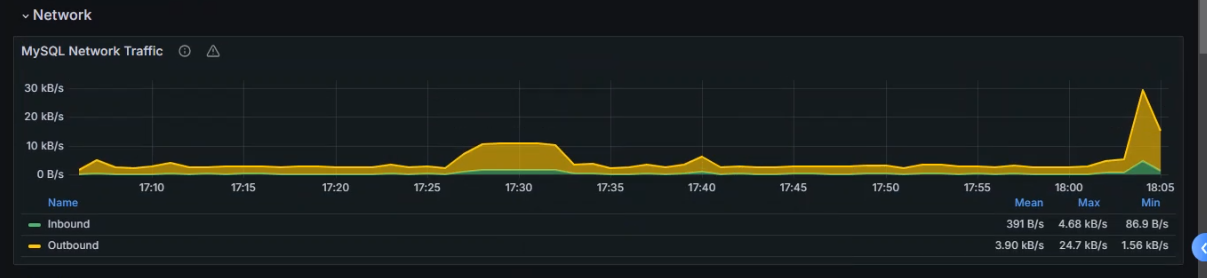
+###### 监控总查询数
+
+数据源已添加完成
+
+创建Dashboard
+
+
+
+添加图标
+
+
+
+选择数据源
+
+
+
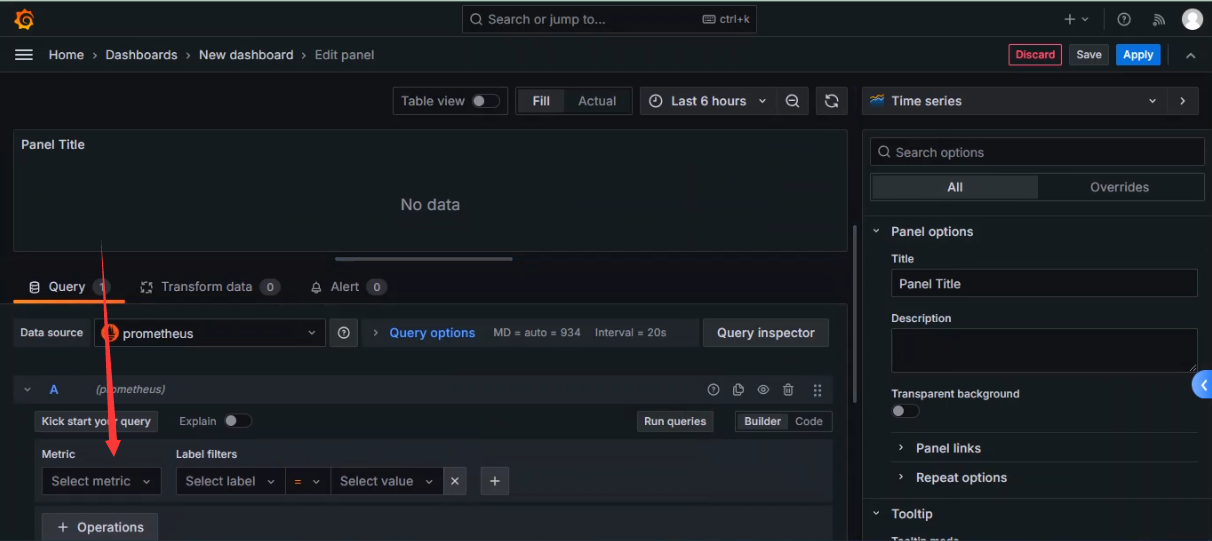
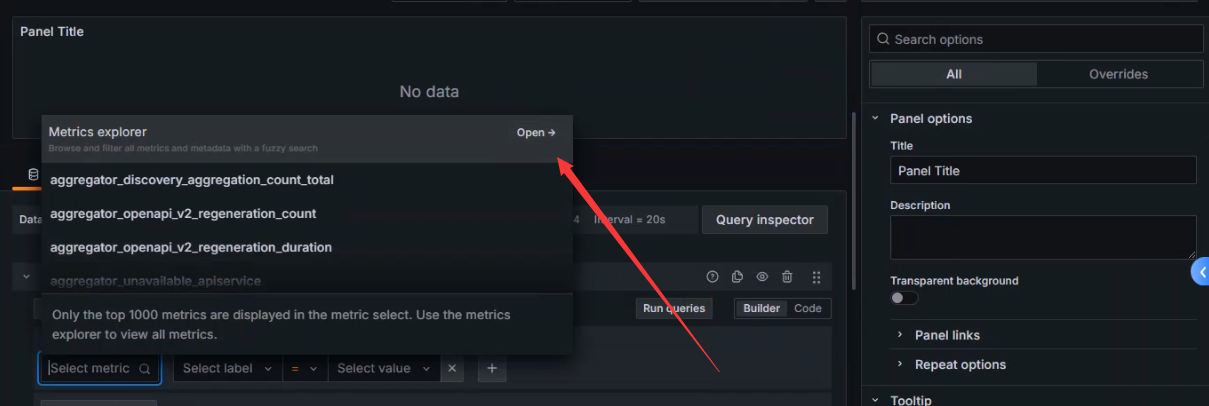
+选择指标
+
+
+
+
+
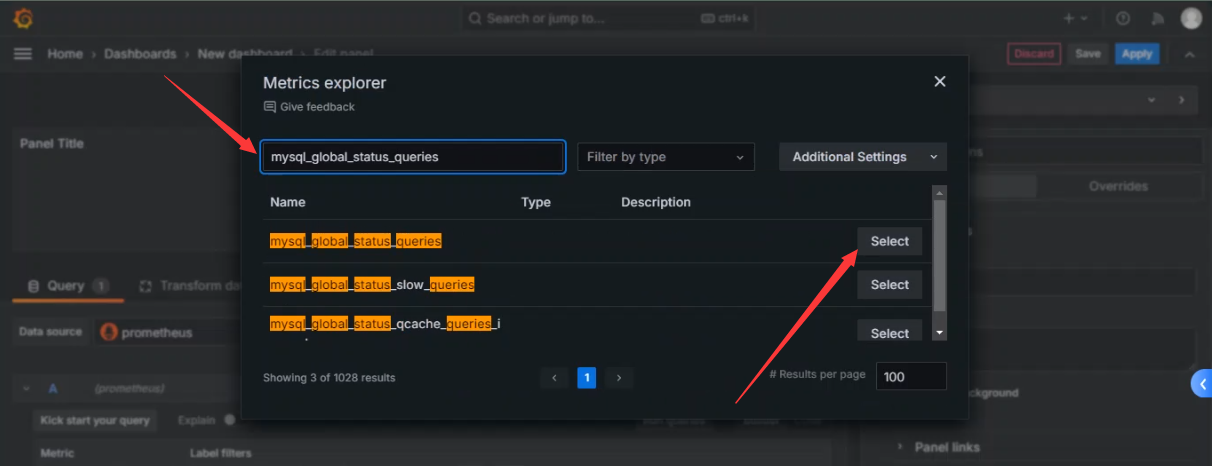
+选择总查询数指标
+
+
+
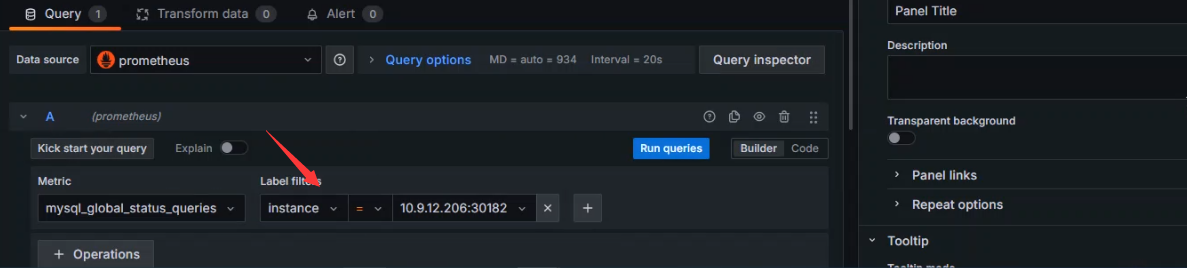
+标签过滤,如果监控数据库集群,可以使用标签指定对应的数据库主机
+
+
+
+设置图标名字
+
+
+
+获取数据
+
+
+
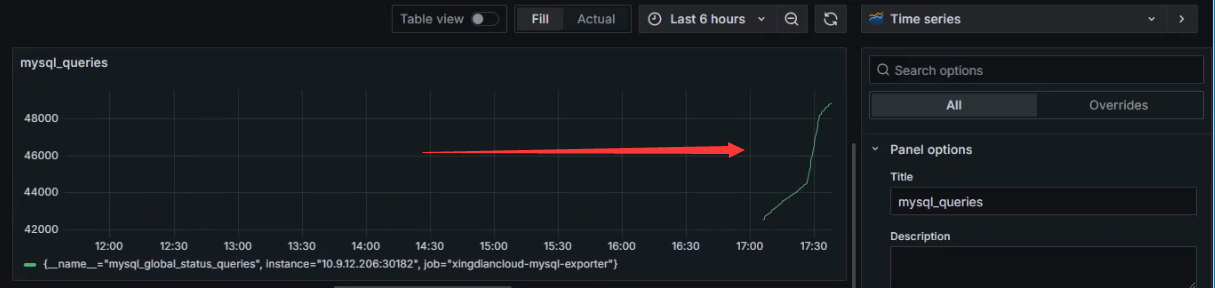
+查看数据
+
+
+
+保存并应用
+
+
+
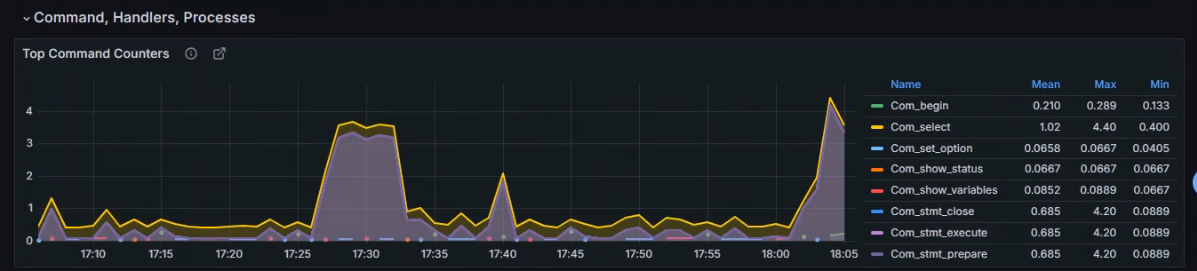
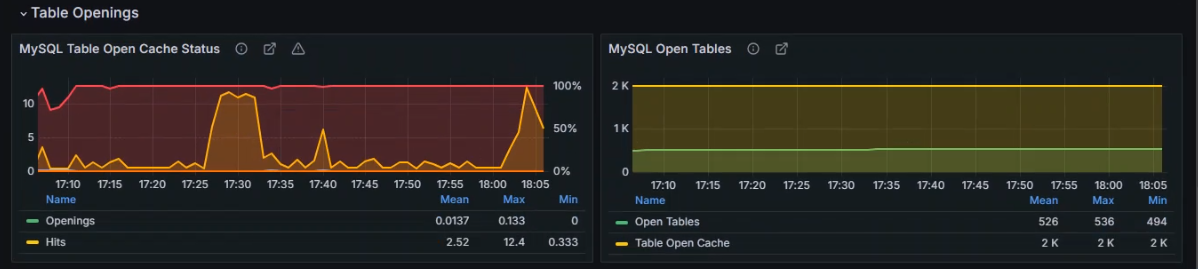
+###### 监控 MySQL 中 TPS 的指标
+
+ TPS代表每秒事务数
+
+ MySQL 的 TPS 指标主要通过以下状态变量来衡量
+
+ `mysql_global_status_commands_total`: 提交事务的次数
+
+ 具体来说,`mysql_global_status_commands_total` 包含了以下几种命令的执行次数统计:
+
+- `com_select`: 查询操作的次数
+- `com_insert`: 插入操作的次数
+- `com_update`: 更新操作的次数
+- `com_delete`: 删除操作的次数
+- `com_replace`: 替换操作的次数
+- `com_load`: 加载数据操作的次数
+- `com_commit`: 提交事务的次数
+- `com_rollback`: 回滚事务的次数
+- `com_prepare_sql`: 准备 SQL 语句的次数
+- `com_stmt_execute`: 执行 SQL 语句的次数
+- `com_stmt_prepare`: 准备 SQL 语句的次数
+- `com_stmt_close`: 关闭 SQL 语句的次数
+- `com_stmt_reset`: 重置 SQL 语句的次数
+
+添加数据源
+
+ 略
+
+创建Dashboard
+
+ 略
+
+创建图标
+
+ 略
+
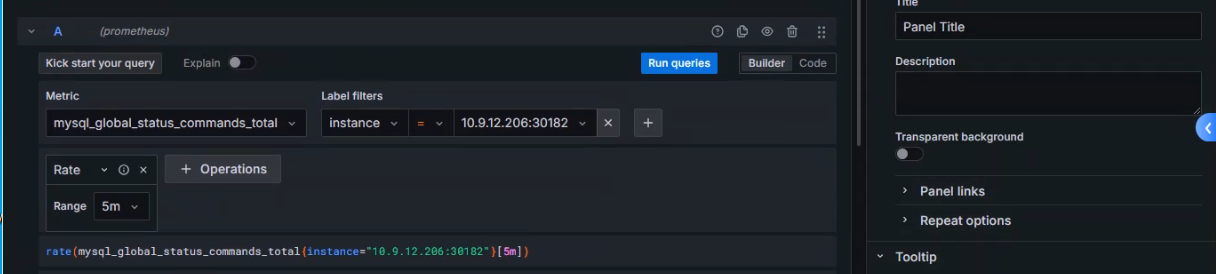
+设置指标
+
+ 选择指标:`mysql_global_status_commands_total`
+
+ 使用函数:rate()
+
+ 时间范围:5m
+
+
+
+查询数据
+
+ 略
+
+设置图标名称
+
+ 略
+
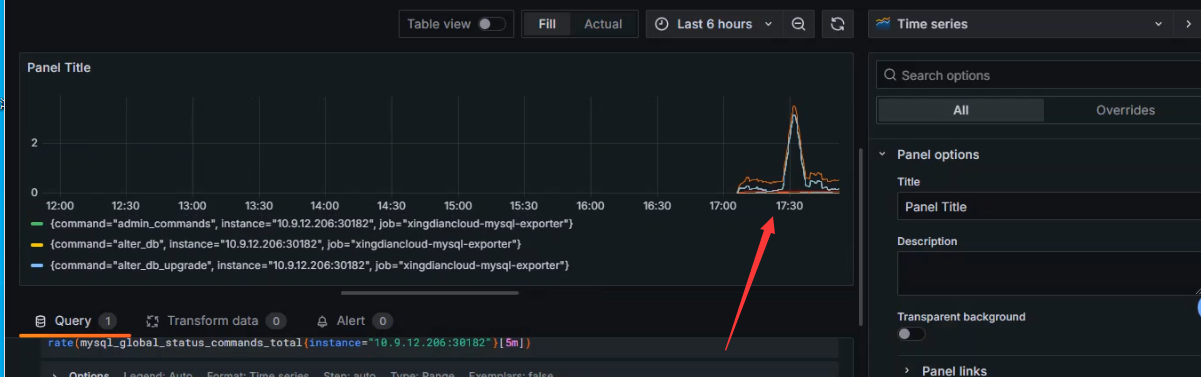
+数据展示
+
+
+
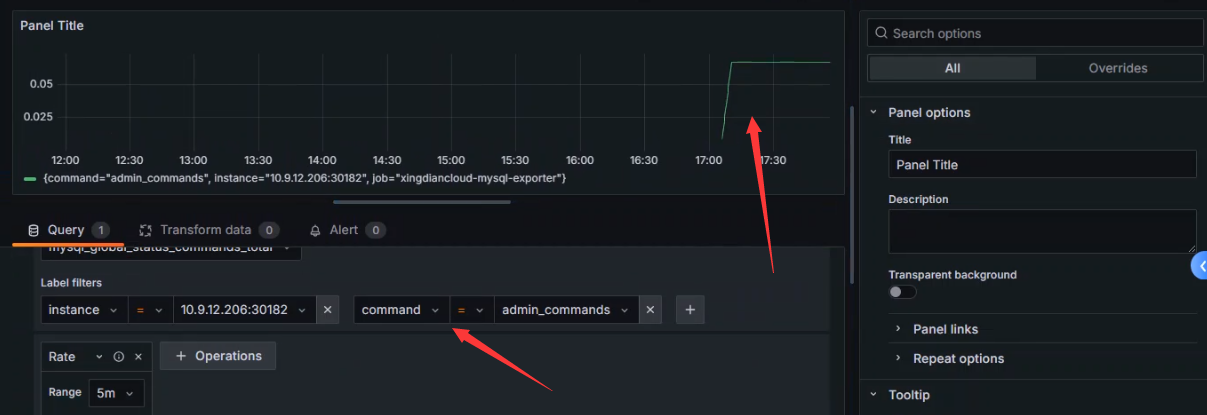
+管理员执行的操作的TPS
+
+
+
+扩展该指标的command
+
+ `mysql_global_status_commands_total` 中的 `command` 标签代表了 MySQL 数据库执行的不同类型的命令,这些命令涵盖了数据库的各个方面,包括管理、查询、事务等
+
+```shell
+admin_commands: 管理命令,涉及数据库服务器的管理操作,如用户管理、权限管理等
+user_commands: 用户命令,用户发起的数据库操作命令,如查询、更新等
+delete: DELETE 操作的次数
+insert: INSERT 操作的次数
+update: UPDATE 操作的次数
+select: SELECT 操作的次数
+commit: 事务提交的次数
+rollback: 事务回滚的次数
+create_db: 创建数据库的次数
+drop_db: 删除数据库的次数
+create_table: 创建表的次数
+drop_table: 删除表的次数
+alter_table: 修改表结构的次数
+set: 执行 SET 命令的次数
+show: 执行 SHOW 命令的次数
+.....
+```
+
+###### Grafana模板监控
+
+获取模板地址:https://grafana.com/grafana/dashboards/14057-mysql/
+
+
+
+Grafana导入模板
+
+
+
+
+
+
+
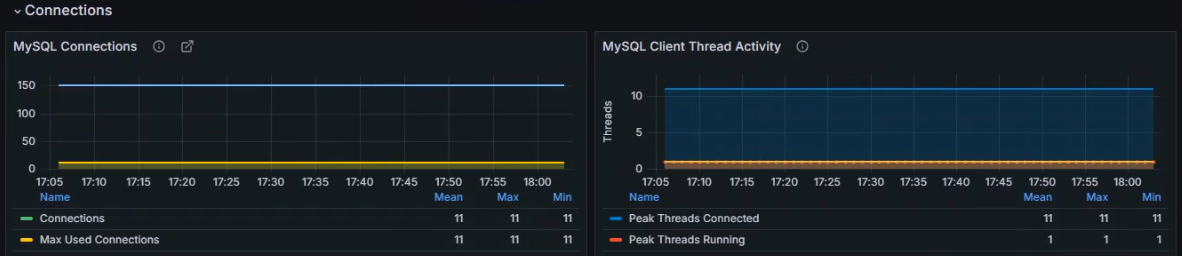
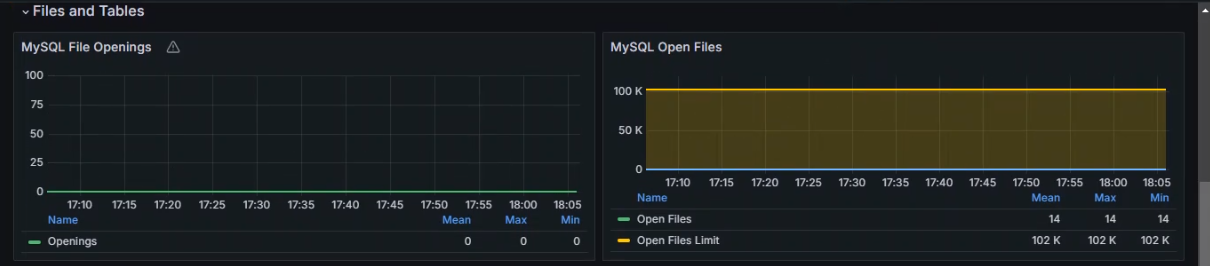
+数据展示
+
+
+
+
+
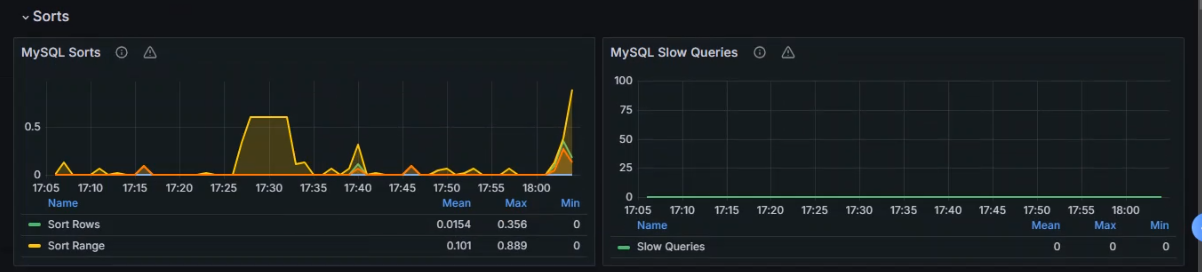
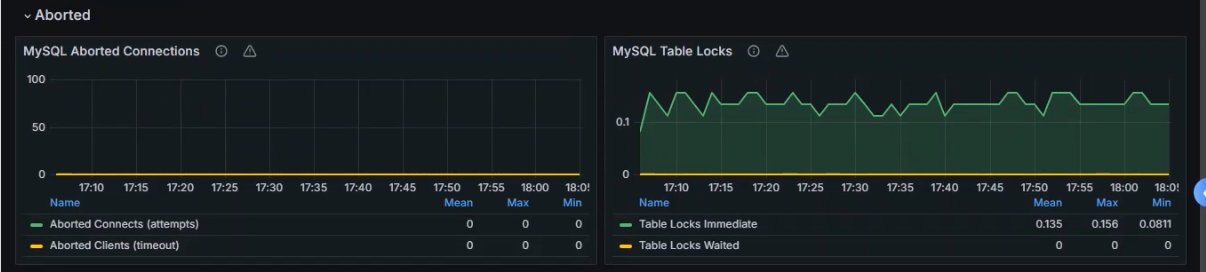
+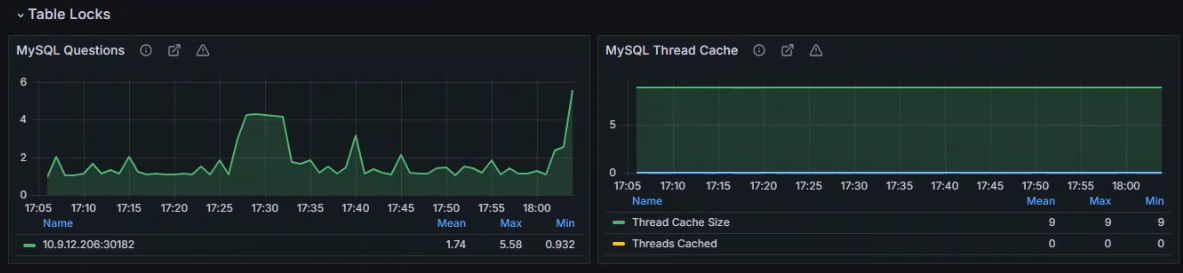
+
+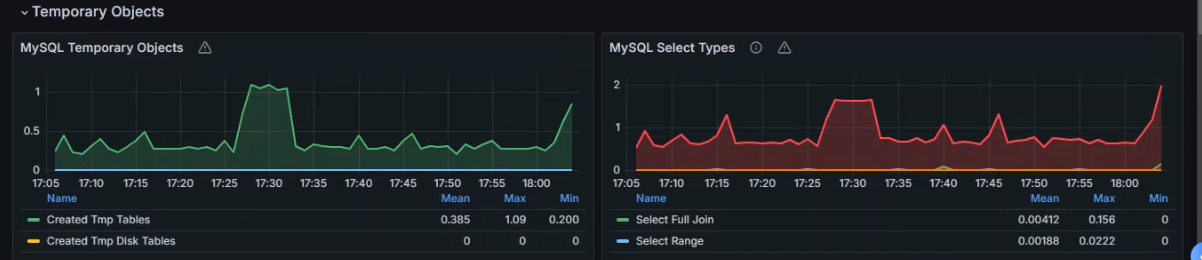
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+#### 2.监控Kubernetes集群
+
+##### 集群架构
+
+
+
+##### 部署采集器
+
+###### 简介
+
+ Node Exporter是安装在Kubernetes集群中采集器
+
+ 可以定期收集系统资源使用情况并将其暴露给 Prometheus 或其他监控系统
+
+ 其主要功能包括收集 CPU、内存、磁盘、网络等系统指标
+
+ 帮助管理员和开发人员了解 Kubernetes 集群的健康状况、资源利用率和性能指标
+
+###### 部署
+
+ 略;见本文章的第二部分
+
+##### 常见指标
+
+注意:指标名字可能会有所差别但是其原理不变
+
+###### kubelet 相关指标
+
+```shell
+kubelet_running_pod_count: 当前运行的 Pod 数量
+kubelet_running_containers: 当前运行的容器数量
+kubelet_volume_stats_used_bytes: 使用的卷存储字节数
+kubelet_volume_stats_available_bytes: 可用的卷存储字节数
+```
+
+###### kube-state-metrics 提供的指标
+
+```shell
+kube_deployment_status_replicas_available: 可用的部署副本数
+kube_node_status_capacity_cpu_cores: 节点的 CPU 核心容量
+kube_node_status_capacity_memory_bytes: 节点的内存容量
+```
+
+###### Kubernetes API Server 相关指标
+
+```shell
+apiserver_request_count: API 请求计数
+apiserver_request_latencies: API 请求的延迟
+```
+
+###### Etcd 相关指标
+
+```shell
+etcd_server_has_leader: 是否存在 Etcd 集群的领导者
+etcd_server_storage_db_size_bytes: Etcd 存储的数据库大小Etcd 相关指标
+```
+
+##### 案例
+
+###### 集群中所有容器在该时间窗口内的总 CPU 使用率
+
+添加数据源
+
+ 略
+
+创建Dashboard
+
+ 略
+
+创建图标
+
+ 略
+
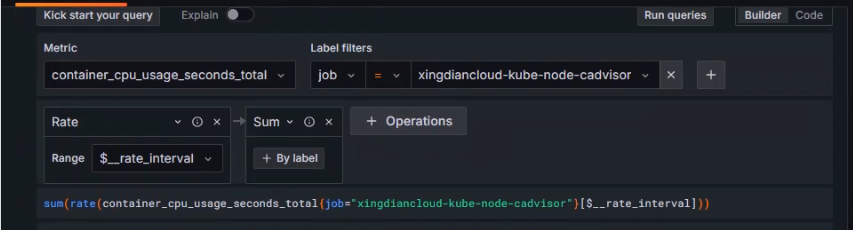
+设置指标
+
+ 选择指标:`container_cpu_usage_seconds_total`
+
+ 使用函数:rate()
+
+ 时间范围:[$__rate_interval]
+
+ 使用函数:sum()
+
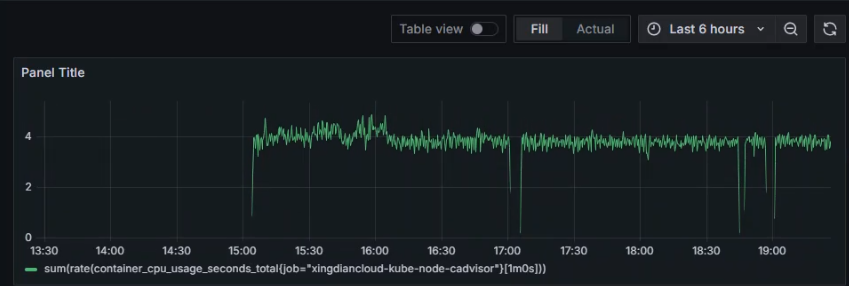
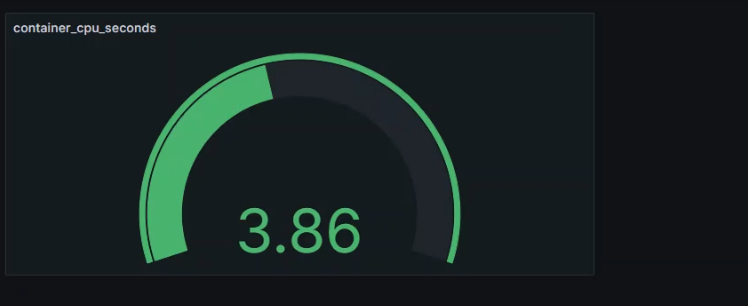
+表达式为
+
+```shell
+sum(rate(container_cpu_usage_seconds_total[$__rate_interval]))
+```
+
+
+
+数据展示
+
+
+
+
+
+###### 集群某节点 CPU 核心在指定时间间隔内的空闲时间速率
+
+添加数据源
+
+ 略
+
+创建Dashboard
+
+ 略
+
+创建图标
+
+ 略
+
+设置指标
+
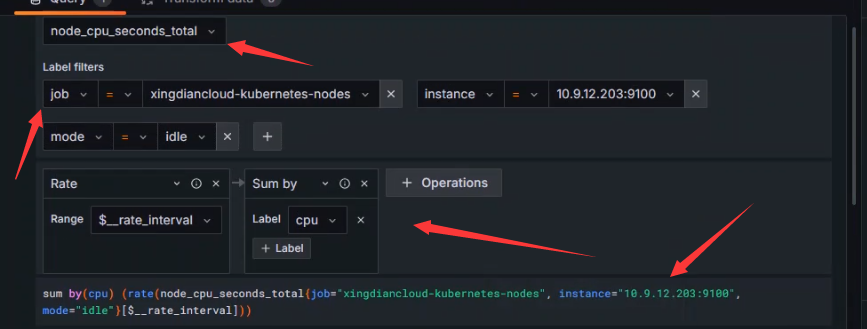
+```shell
+sum by(cpu) (rate(node_cpu_seconds_total{job="xingdiancloud-kubernetes-nodes", instance="10.9.12.203:9100", mode="idle"}[$__rate_interval]))
+```
+
+指标解释
+
+**`rate(node_cpu_seconds_total{...}[$__rate_interval])`**:
+
+- `rate` 函数计算在指定时间间隔(`$__rate_interval`)内时间序列的每秒平均增长率。
+- `node_cpu_seconds_total{...}`过滤 `node_cpu_seconds_total`指标,使其只包括以下标签:
+ - `job="xingdiancloud-kubernetes-nodes"`:指定 Prometheus 监控任务的名称
+ - `instance="10.9.12.203:9100"`:指定特定节点的实例地址。
+ - `mode="idle"`:指定 CPU 模式为 `idle`,即空闲时间
+
+**`sum by(cpu) (...)`**:
+
+- `sum by(cpu)` 汇总计算结果,按 `cpu` 标签分组
+- 这意味着它会计算每个 CPU 核心的空闲时间速率
+
+综上所述,这段查询语句的功能是:
+
+- 计算特定节点(`10.9.12.203:9100`)上每个 CPU 核心在指定时间间隔内的空闲时间速率
+- 结果按 CPU 核心进行分组和汇总
+
+
+
+数据展示
+
+
+
+## 七:Grafana监控告警
+
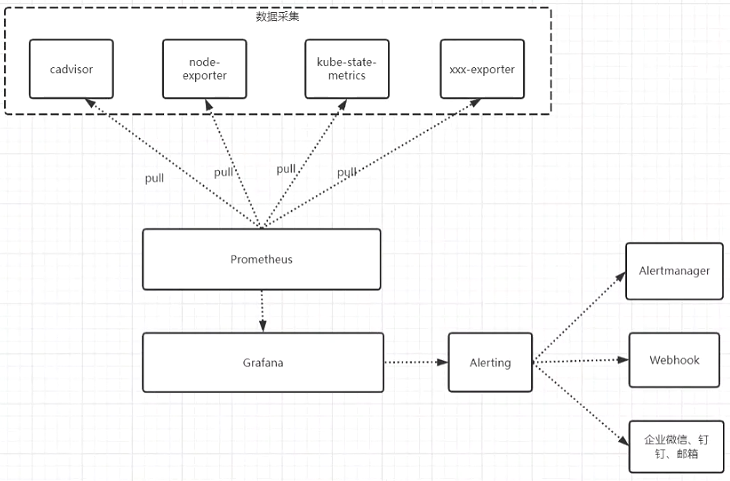
+#### 1.监控简介
+
+ Grafana能够将监控数据和告警配置集成到同一个界面中,便于用户一站式管理和查看监控数据及其相关告警
+
+ Grafana支持多种通知方式,如邮件、Slack、Webhook等,可以根据不同的情况选择合适的通知方式
+
+#### 2.监控架构
+
+
+
+#### 3.Grafana Alerting
+
+ 除了Prometheus的AlertManager可以发送报警,Grafana Alerting同时也支持
+
+ Grafana Alerting可以无缝定义告警在数据中的位置,可视化的定义阈值,通过钉钉、email等获取告警通知
+
+ 可直观的定义告警规则,不断的评估并发送通知
+
+#### 4.原理图
+
+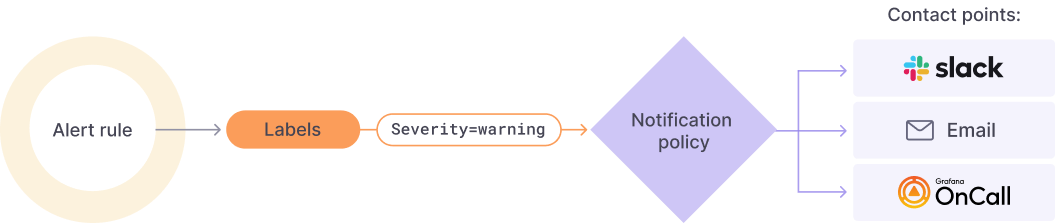
+
+`Alert rule` :设置确定警报实例是否会触发的评估标准;警报规则由一个或多个查询和表达式、条件、评估频率以及满足条件的持续时间(可选)组成
+
+`Labels`:将警报规则及其实例与通知策略和静默相匹配;它们还可用于按严重性对警报进行分组
+
+`Notification policy`:设置警报的发送地点、时间和方式;每个通知策略指定一组标签匹配器来指示它们负责哪些警报;通知策略具有分配给它的由一个或多个通知者组成的联系点
+
+`Contact points`:定义触发警报时如何通知您的联系人;我们支持多种 ChatOps 工具,确保您的团队收到警报
+
+#### 5.配置关联邮箱
+
+##### 修改Grafana配置文件
+
+```shell
+[root@grafana grafana]# vim conf/defaults.ini
+[smtp]
+enabled = true 启用SMTP邮件发送 false:禁用SMTP邮件发送
+host = smtp.163.com:25 SMTP服务器的主机名和端口
+user = zhuangyaovip@163.com 用于身份验证的SMTP用户名,对应的邮箱地址
+password = MYNCREJBMRFBV*** 授权密码
+cert_file = 用于TLS/SSL连接的证书文件路径;如果不使用证书文件,可以留空
+key_file = 用于TLS/SSL连接的私钥文件路径;如果不使用私钥文件,可以留空
+skip_verify = true 是否跳过对SMTP服务器证书的验证;false:验证服务器证书;true:跳过验证
+from_address = zhuangyaovip@163.com 发送邮件时的发件人地址
+from_name = Grafana 发送邮件时的发件人名称
+ehlo_identity = 用于EHLO命令的标识符,可以留空,默认使用Grafana服务器的主机名
+startTLS_policy = 指定STARTTLS的策略,可选值包括:always, never, optional。默认是optional,即如果SMTP服务器支持STARTTLS就使用
+enable_tracing = false 是否启用SMTP通信的调试跟踪;true:启用调试跟踪,false:禁用调试跟踪
+```
+
+##### 重启服务
+
+```
+[root@grafana grafana]# nohup ./bin/grafana-server --config ./conf/defaults.ini &
+```
+
+##### 配置联络点
+
+
+
+
+
+##### 指定联络点名称,收件人地址
+
+
+
+##### 配置信息模板和主题模板
+
+
+
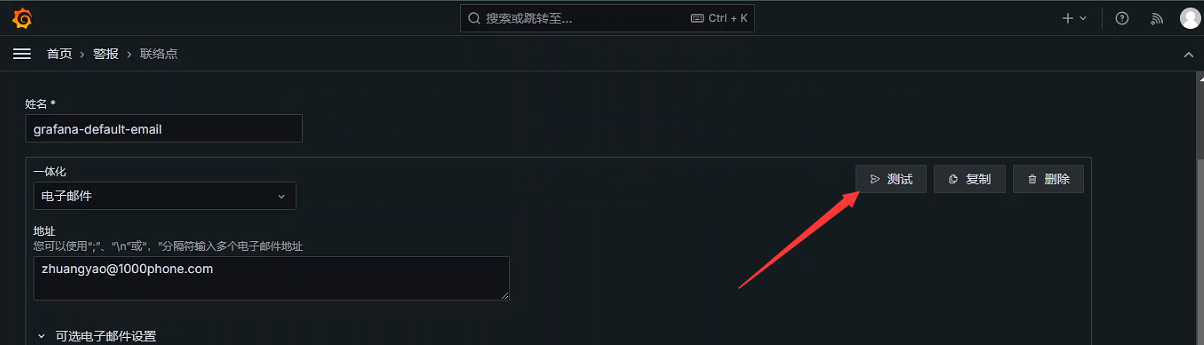
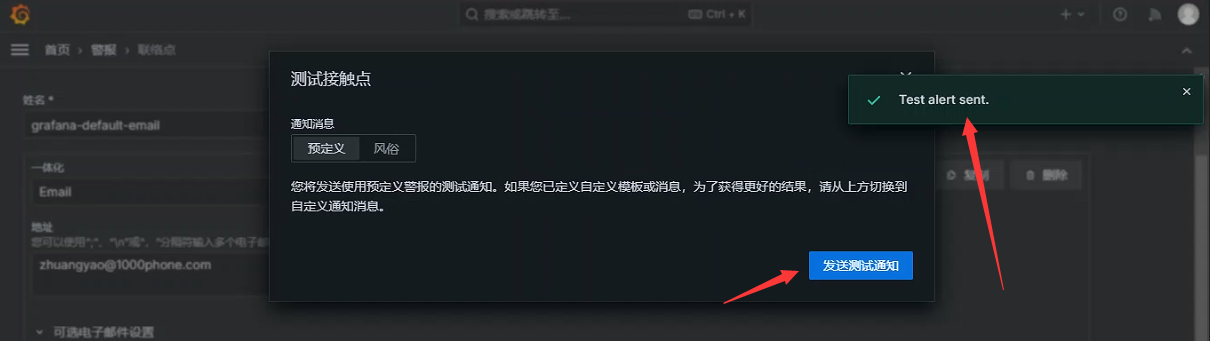
+##### 测试是否可用
+
+
+
+
+
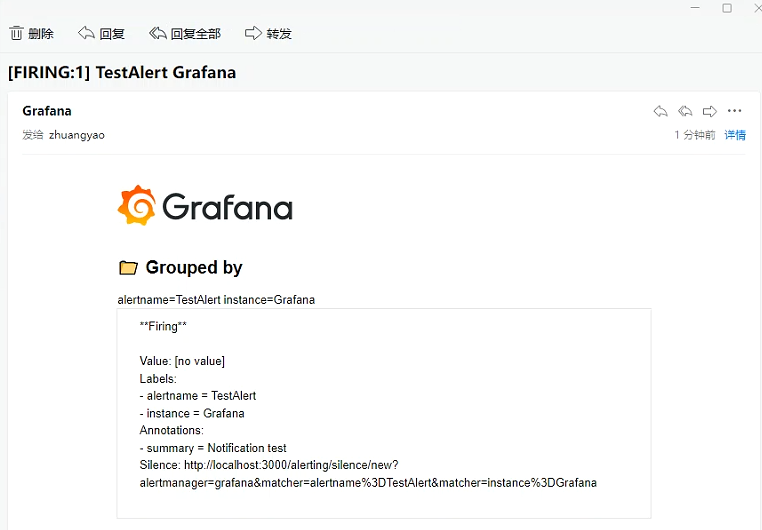
+##### 收件人确认
+
+
+
+至此,邮箱配置成功
+
+#### 6.通知策略
+
+##### 作用
+
+ 确定警报如何路由到联络点
+
+##### 配置
+
+ 系统自带默认策略:如果没有找到其他匹配的策略,所有警报实例将由默认策略处理
+
+
+
+#### 7.配置使用
+
+
+
+##### 查看警报规则
+
+关联数据源和Dashboard
+
+
+
+###### 告警规则(Alert rules)
+
+- 告警规则是一组评估标准,用于确定告警实例是否会触发。该规则由一个或多个查询和表达式、一个条件、评估频率以及满足条件的持续时间(可选)组成
+- 在查询和表达式选择要评估的数据集时,条件会设置告警必须达到或超过才能创建警报的阈值
+- 间隔指定评估警报规则的频率。持续时间在配置时表示必须满足条件的时间。告警规则还可以定义没有数据时的告警行为
+
+###### 告警规则状态(Alert rule state)
+
+| 状态 | 描述 |
+| :-----: | :-----------------------------------------------------: |
+| Normal | 评估引擎返回的时间序列都不是处于Pending 或者 Firing状态 |
+| Pending | 评估引擎返回的至少一个时间序列是Pending |
+| Firing | 评估引擎返回的至少一个时间序列是Firing |
+
+###### 告警规则运行状况(Alert rule health)
+
+| 状态 | 描述 |
+| :----: | :--------------------------------------------: |
+| Ok | 评估告警规则时没有错误 |
+| Error | 评估告警规则时没有错误 |
+| NoData | 在规则评估期间返回的至少一个时间序列中缺少数据 |
+
+###### 告警实例状态(Alert instance state)
+
+| 状态 | 描述 |
+| :------: | :--------------------------------------: |
+| Normal | 既未触发也未挂起的告警状态,一切正常 |
+| Pending | 已激活的告警状态少于配置的阈值持续时间 |
+| Alerting | 已激活超过配置的阈值持续时间的告警的状态 |
+| NoData | 在配置的时间窗口内未收到任何数据 |
+| Error | 尝试评估告警规则时发生的错误 |
+
+##### New alert rule
+
+Enter alert rule name
+
+
+
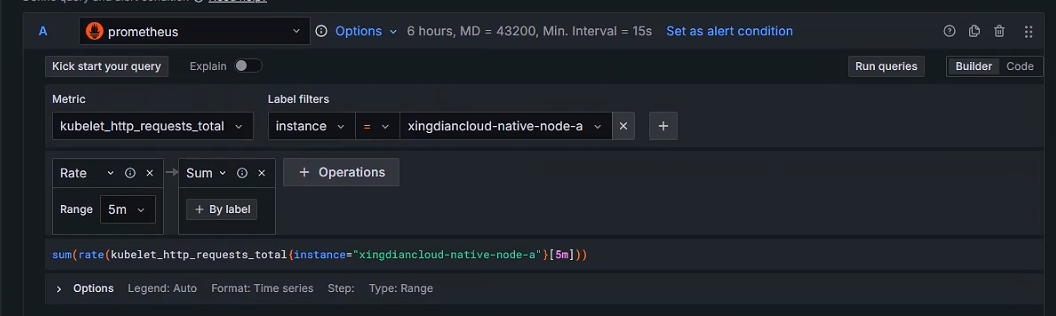
+Define query and alert condition
+
+
+
+Rule type
+
+
+
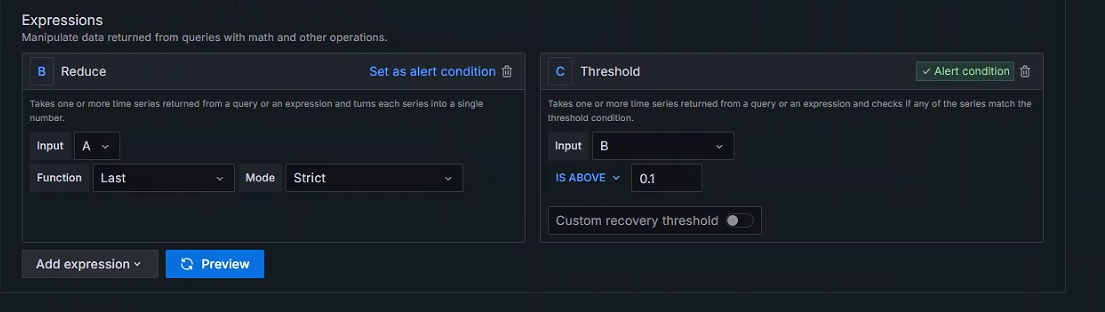
+Expressions
+
+表达式
+
+ 将Reduce(减少)的Function选为最后一个值
+
+ 将Threshold(临界点)的IS ABOVE的值设置为会触发的值,模拟报警产生
+
+
+
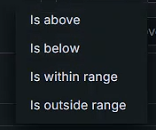
+临界点参数:
+
+IS ABOVE:高于
+
+IS BELOW:在下面,低于
+
+IS WITHIN RANGE:在范围内
+
+IS OUTSIDE RANGE:超出范围
+
+
+
+
+
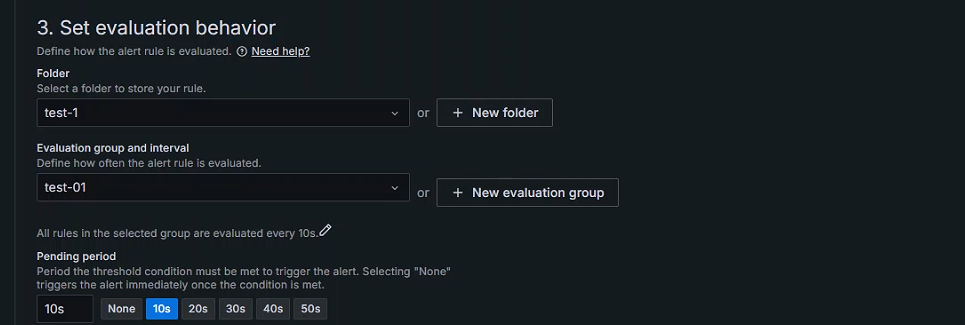
+Set evaluation behavior
+
+定义如何评估警报规则
+
+ 选择文件夹存储规则,文件夹不存在需要自行创建
+
+ 定义评估警报规则的频率
+
+ 触发警报的阈值条件必须满足的时间段;选择“无”会在满足条件后立即触发警报
+
+
+
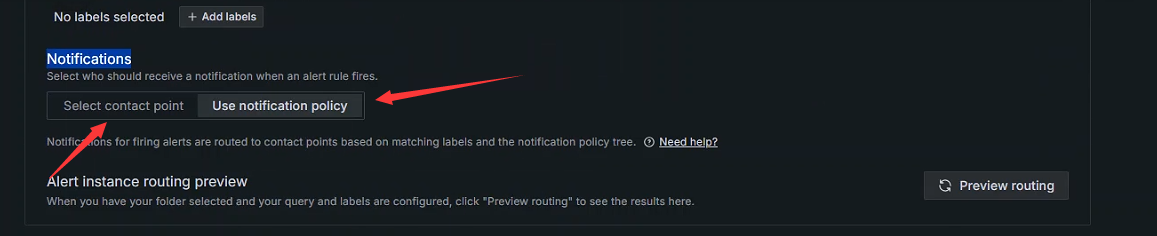
+Notifications
+
+ 选择当警报规则触发时应该如何接收通知
+
+ 选择联络点:直接将告警信息发送给对应的接收者
+
+ 使用通知策略:触发警报的通知会根据匹配的标签和通知策略树路由到联络者
+
+
+
+使用通知策略
+
+
+
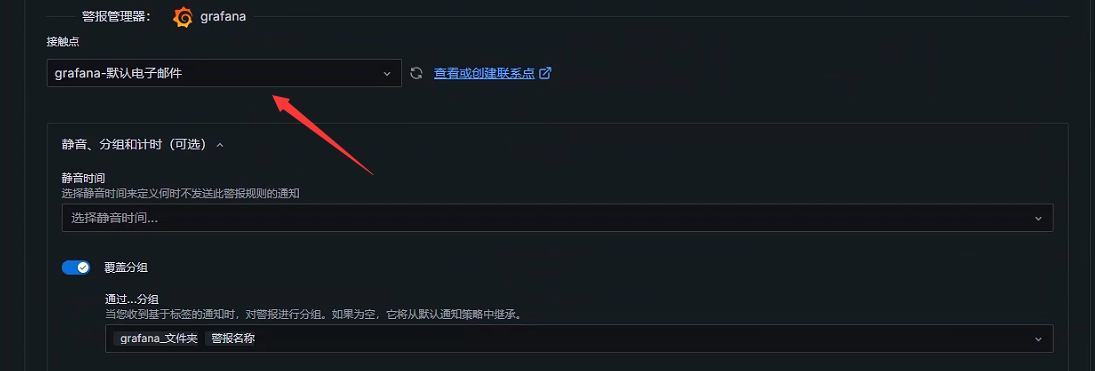
+使用联络点
+
+
+
+保存规则
+
+
+
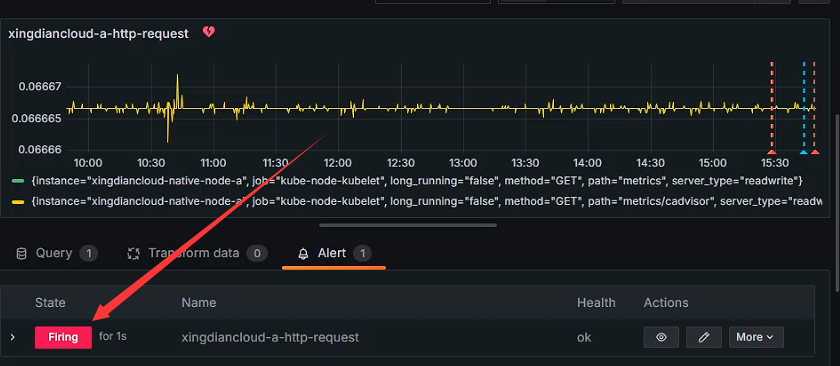
+查看状态
+
+ 状态为Firing 意为触发了告警
+
+
+
+查看是否接收到邮件
+
+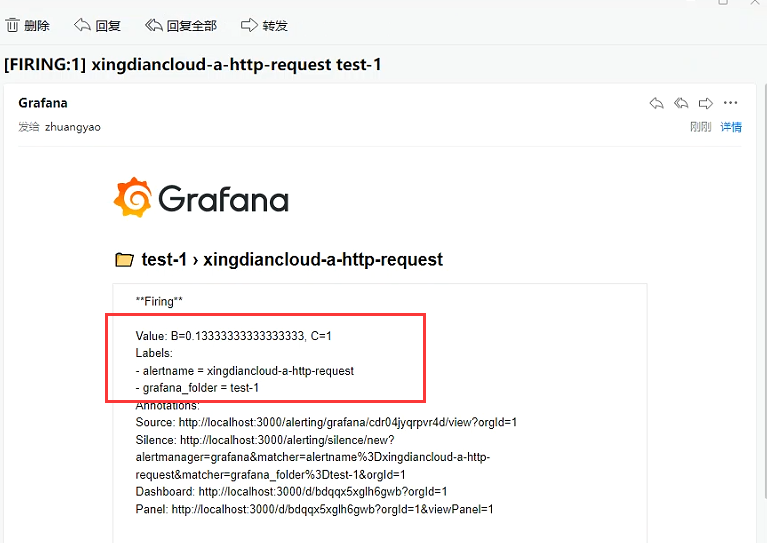
+
+邮箱告警成功
+
+修改临界点值回复正常状态
+
+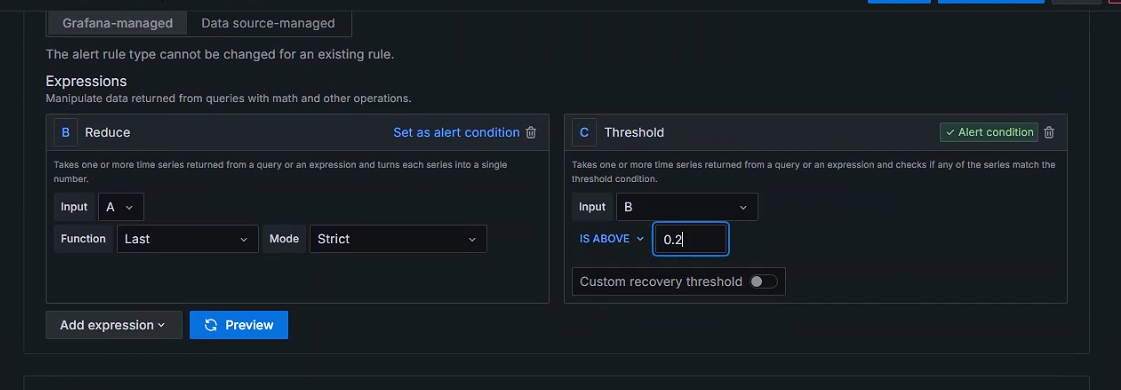
+
+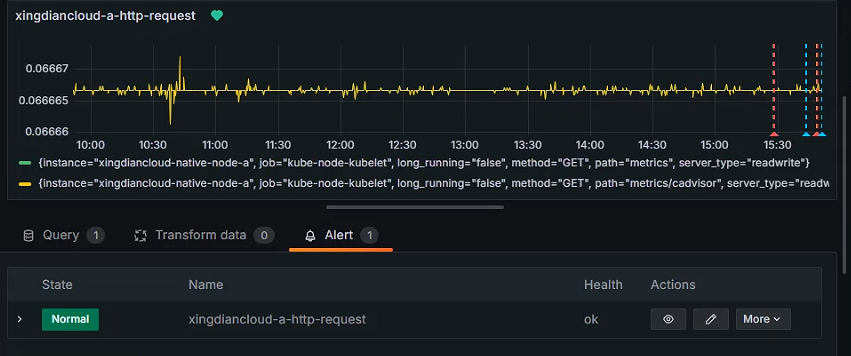
+
diff --git a/NEW/利用kubernetes部署微服务项目.md b/NEW/利用kubernetes部署微服务项目.md
new file mode 100644
index 0000000..e7e8fd1
--- /dev/null
+++ b/NEW/利用kubernetes部署微服务项目.md
@@ -0,0 +1,807 @@
+利用kubernetes部署微服务项目
+
+著作:行癫 <盗版必究>
+
+------
+
+## 一:环境准备
+
+#### 1.kubernetes集群环境
+
+集群环境检查
+
+```shell
+[root@master ~]# kubectl get node
+NAME STATUS ROLES AGE VERSION
+master Ready control-plane,master 11d v1.23.1
+node-1 Ready 11d v1.23.1
+node-2 Ready 11d v1.23.1
+node-3 Ready 11d v1.23.1
+```
+
+#### 2.harbor环境
+
+harbor环境检查
+
+ +
+## 二:项目准备
+
+#### 1.项目包
+
+
+
+#### 2.项目端口准备
+
+| 服务 | 内部端口 | 外部端口 |
+| :---------------------: | :------: | -------- |
+| tensquare_eureka_server | 10086 | 30020 |
+| tensquare_zuul | 10020 | 30021 |
+| tensquare_admin_service | 9001 | 30024 |
+| tensquare_gathering | 9002 | 30022 |
+| mysql | 3306 | 30023 |
+
+
+
+## 三:项目部署
+
+#### 1.eureka部署
+
+application.yml文件修改
+
+```
+spring:
+ application:
+ name: EUREKA-HA
+
+---
+#单机配置
+server:
+ port: 10086
+
+eureka:
+ instance:
+ hostname: localhost
+ client:
+ register-with-eureka: false
+ fetch-registry: false
+ service-url:
+ defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/
+ #defaultZone: http://pod主机名称.service名称:端口/eureka/
+```
+
+Dockerfile创建:
+
+```shell
+[root@nfs-harbor jdk]# ls
+Dockerfile tensquare_eureka_server-1.0-SNAPSHOT.jar jdk-8u211-linux-x64.tar.gz
+[root@nfs-harbor jdk]# cat Dockerfile
+FROM xingdian
+MAINTAINER "xingdian"
+ADD jdk-8u211-linux-x64.tar.gz /usr/local/
+RUN mv /usr/local/jdk1.8.0_211 /usr/local/java
+ENV JAVA_HOME /usr/local/java/
+ENV PATH $PATH:$JAVA_HOME/bin
+COPY tensquare_eureka_server-1.0-SNAPSHOT.jar /usr/local
+EXPOSE 10086
+CMD java -jar /usr/local/tensquare_eureka_server-1.0-SNAPSHOT.jar
+```
+
+镜像构建:
+
+```shell
+[root@nfs-harbor jdk]# docker build -t eureka:v2022.1 .
+```
+
+上传到镜像仓库:
+
+```shell
+[root@nfs-harbor jdk]# docker tag eureka:v2022.1 10.0.0.230/xingdian/eureka:v2022.1
+[root@nfs-harbor jdk]# docker push 10.0.0.230/xingdian/eureka:v2022.1
+```
+
+仓库验证:
+
+
+
+## 二:项目准备
+
+#### 1.项目包
+
+
+
+#### 2.项目端口准备
+
+| 服务 | 内部端口 | 外部端口 |
+| :---------------------: | :------: | -------- |
+| tensquare_eureka_server | 10086 | 30020 |
+| tensquare_zuul | 10020 | 30021 |
+| tensquare_admin_service | 9001 | 30024 |
+| tensquare_gathering | 9002 | 30022 |
+| mysql | 3306 | 30023 |
+
+
+
+## 三:项目部署
+
+#### 1.eureka部署
+
+application.yml文件修改
+
+```
+spring:
+ application:
+ name: EUREKA-HA
+
+---
+#单机配置
+server:
+ port: 10086
+
+eureka:
+ instance:
+ hostname: localhost
+ client:
+ register-with-eureka: false
+ fetch-registry: false
+ service-url:
+ defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/
+ #defaultZone: http://pod主机名称.service名称:端口/eureka/
+```
+
+Dockerfile创建:
+
+```shell
+[root@nfs-harbor jdk]# ls
+Dockerfile tensquare_eureka_server-1.0-SNAPSHOT.jar jdk-8u211-linux-x64.tar.gz
+[root@nfs-harbor jdk]# cat Dockerfile
+FROM xingdian
+MAINTAINER "xingdian"
+ADD jdk-8u211-linux-x64.tar.gz /usr/local/
+RUN mv /usr/local/jdk1.8.0_211 /usr/local/java
+ENV JAVA_HOME /usr/local/java/
+ENV PATH $PATH:$JAVA_HOME/bin
+COPY tensquare_eureka_server-1.0-SNAPSHOT.jar /usr/local
+EXPOSE 10086
+CMD java -jar /usr/local/tensquare_eureka_server-1.0-SNAPSHOT.jar
+```
+
+镜像构建:
+
+```shell
+[root@nfs-harbor jdk]# docker build -t eureka:v2022.1 .
+```
+
+上传到镜像仓库:
+
+```shell
+[root@nfs-harbor jdk]# docker tag eureka:v2022.1 10.0.0.230/xingdian/eureka:v2022.1
+[root@nfs-harbor jdk]# docker push 10.0.0.230/xingdian/eureka:v2022.1
+```
+
+仓库验证:
+
+ +
+#### 2.tensquare_zuul部署
+
+Dockerfile创建:
+
+```shell
+[root@nfs-harbor jdk]# cat Dockerfile
+FROM xingdian
+MAINTAINER "xingdian"
+ADD jdk-8u211-linux-x64.tar.gz /usr/local/
+RUN mv /usr/local/jdk1.8.0_211 /usr/local/java
+ENV JAVA_HOME /usr/local/java/
+ENV PATH $PATH:$JAVA_HOME/bin
+COPY tensquare_zuul-1.0-SNAPSHOT.jar /usr/local
+EXPOSE 10020
+CMD java -jar /usr/local/tensquare_zuul-1.0-SNAPSHOT.jar
+```
+
+镜像构建:
+
+```shell
+[root@nfs-harbor jdk]# docker build -t zuul:v2022.1 .
+```
+
+镜像上传:
+
+```shell
+[root@nfs-harbor jdk]# docker tag zuul:v2022.1 10.0.0.230/xingdian/zuul:v2022.1
+[root@nfs-harbor jdk]# docker push 10.0.0.230/xingdian/zuul:v2022.1
+```
+
+仓库验证:
+
+
+
+#### 2.tensquare_zuul部署
+
+Dockerfile创建:
+
+```shell
+[root@nfs-harbor jdk]# cat Dockerfile
+FROM xingdian
+MAINTAINER "xingdian"
+ADD jdk-8u211-linux-x64.tar.gz /usr/local/
+RUN mv /usr/local/jdk1.8.0_211 /usr/local/java
+ENV JAVA_HOME /usr/local/java/
+ENV PATH $PATH:$JAVA_HOME/bin
+COPY tensquare_zuul-1.0-SNAPSHOT.jar /usr/local
+EXPOSE 10020
+CMD java -jar /usr/local/tensquare_zuul-1.0-SNAPSHOT.jar
+```
+
+镜像构建:
+
+```shell
+[root@nfs-harbor jdk]# docker build -t zuul:v2022.1 .
+```
+
+镜像上传:
+
+```shell
+[root@nfs-harbor jdk]# docker tag zuul:v2022.1 10.0.0.230/xingdian/zuul:v2022.1
+[root@nfs-harbor jdk]# docker push 10.0.0.230/xingdian/zuul:v2022.1
+```
+
+仓库验证:
+
+ +
+注意:
+
+ 在构建之前使用vim修改源码jar包,修改的内容如下(文件:application.yml):
+
+```yml
+server:
+ port: 10020 # 端口
+
+# 基本服务信息
+spring:
+ application:
+ name: tensquare-zuul # 服务ID
+
+# Eureka配置
+eureka:
+ client:
+ service-url:
+ #defaultZone: http://192.168.66.103:10086/eureka,http://192.168.66.104:10086/eureka # Eureka访问地址
+ #tensquare_eureka_server地址和端口(修改)
+ defaultZone: http://10.0.0.220:30020/eureka
+ instance:
+ prefer-ip-address: true
+
+# 修改ribbon的超时时间
+ribbon:
+ ConnectTimeout: 1500 # 连接超时时间,默认500ms
+ ReadTimeout: 3000 # 请求超时时间,默认1000ms
+
+
+# 修改hystrix的熔断超时时间
+hystrix:
+ command:
+ default:
+ execution:
+ isolation:
+ thread:
+ timeoutInMillisecond: 2000 # 熔断超时时长,默认1000ms
+
+
+# 网关路由配置
+zuul:
+ routes:
+ admin:
+ path: /admin/**
+ serviceId: tensquare-admin-service
+ gathering:
+ path: /gathering/**
+ serviceId: tensquare-gathering
+
+ # jwt参数
+jwt:
+ config:
+ key: itcast
+ ttl: 1800000
+```
+
+#### 3.mysql部署
+
+镜像获取(使用官方镜像):
+
+```shell
+[root@nfs-harbor mysql]# docker pull mysql:5.7.38
+```
+
+镜像上传:
+
+```shell
+[root@nfs-harbor mysql]# docker tag mysql:5.7.38 10.0.0.230/xingdian/mysql:v1
+[root@nfs-harbor mysql]# docker push 10.0.0.230/xingdian/mysql:v1
+```
+
+#### 4.admin_service部署
+
+Dockerfile创建:
+
+```shell
+[root@nfs-harbor jdk]# cat Dockerfile
+FROM xingdian
+MAINTAINER "xingdian"
+ADD jdk-8u211-linux-x64.tar.gz /usr/local/
+RUN mv /usr/local/jdk1.8.0_211 /usr/local/java
+ENV JAVA_HOME /usr/local/java/
+ENV PATH $PATH:$JAVA_HOME/bin
+COPY tensquare_admin_service-1.0-SNAPSHOT.jar /usr/local
+EXPOSE 9001
+CMD java -jar /usr/local/tensquare_admin_service-1.0-SNAPSHOT.jar
+```
+
+镜像构建:
+
+```shell
+[root@nfs-harbor jdk]# docker build -t admin_service:v2022.1 .
+```
+
+镜像上传:
+
+```shell
+[root@nfs-harbor jdk]# docker tag admin_service:v2022.1 10.0.0.230/xingdian/admin_service:v2022.1
+[root@nfs-harbor jdk]# docker push 10.0.0.230/xingdian/admin_service:v2022.1
+```
+
+注意:
+
+ 在构建之前使用vim修改源码jar包,修改的内容如下(文件:application.yml):
+
+```yml
+spring:
+ application:
+ name: tensquare-admin-service #指定服务名
+ datasource:
+ driverClassName: com.mysql.jdbc.Driver
+ #数据库地址(修改)
+ url: jdbc:mysql://10.0.0.220:30023/tensquare_user?characterEncoding=UTF8&useSSL=false
+ #数据库账户名(修改)
+ username: root
+ #数据库账户密码(修改)
+ password: mysql
+ jpa:
+ database: mysql
+ show-sql: true
+
+#Eureka配置
+eureka:
+ client:
+ service-url:
+ #defaultZone: http://192.168.66.103:10086/eureka,http://192.168.66.104:10086/eureka
+ ##tensquare_eureka_server地址和端口(修改)
+ defaultZone: http://10.0.0.220:30020/eureka
+ instance:
+ lease-renewal-interval-in-seconds: 5 # 每隔5秒发送一次心跳
+ lease-expiration-duration-in-seconds: 10 # 10秒不发送就过期
+ prefer-ip-address: true
+
+
+ # jwt参数
+jwt:
+ config:
+ key: itcast
+ ttl: 1800000
+```
+
+#### 5.gathering部署
+
+Dockerfile创建:
+
+```shell
+[root@nfs-harbor jdk]# cat Dockerfile
+FROM xingdian
+MAINTAINER "xingdian"
+ADD jdk-8u211-linux-x64.tar.gz /usr/local/
+RUN mv /usr/local/jdk1.8.0_211 /usr/local/java
+ENV JAVA_HOME /usr/local/java/
+ENV PATH $PATH:$JAVA_HOME/bin
+COPY tensquare_gathering-1.0-SNAPSHOT.jar /usr/local
+CMD java -jar /usr/local/tensquare_gathering-1.0-SNAPSHOT.jar
+```
+
+镜像构建:
+
+```shell
+[root@nfs-harbor jdk]# docker build -t gathering:v2022.1 .
+```
+
+镜像上传:
+
+```shell
+[root@nfs-harbor jdk]# docker tag gathering:v2022.1 10.0.0.230/xingdian/gathering:v2022.1
+[root@nfs-harbor jdk]# docker push 10.0.0.230/xingdian/gathering:v2022.1
+```
+
+仓库验证:
+
+
+
+注意:
+
+ 在构建之前使用vim修改源码jar包,修改的内容如下(文件:application.yml):
+
+```yml
+server:
+ port: 10020 # 端口
+
+# 基本服务信息
+spring:
+ application:
+ name: tensquare-zuul # 服务ID
+
+# Eureka配置
+eureka:
+ client:
+ service-url:
+ #defaultZone: http://192.168.66.103:10086/eureka,http://192.168.66.104:10086/eureka # Eureka访问地址
+ #tensquare_eureka_server地址和端口(修改)
+ defaultZone: http://10.0.0.220:30020/eureka
+ instance:
+ prefer-ip-address: true
+
+# 修改ribbon的超时时间
+ribbon:
+ ConnectTimeout: 1500 # 连接超时时间,默认500ms
+ ReadTimeout: 3000 # 请求超时时间,默认1000ms
+
+
+# 修改hystrix的熔断超时时间
+hystrix:
+ command:
+ default:
+ execution:
+ isolation:
+ thread:
+ timeoutInMillisecond: 2000 # 熔断超时时长,默认1000ms
+
+
+# 网关路由配置
+zuul:
+ routes:
+ admin:
+ path: /admin/**
+ serviceId: tensquare-admin-service
+ gathering:
+ path: /gathering/**
+ serviceId: tensquare-gathering
+
+ # jwt参数
+jwt:
+ config:
+ key: itcast
+ ttl: 1800000
+```
+
+#### 3.mysql部署
+
+镜像获取(使用官方镜像):
+
+```shell
+[root@nfs-harbor mysql]# docker pull mysql:5.7.38
+```
+
+镜像上传:
+
+```shell
+[root@nfs-harbor mysql]# docker tag mysql:5.7.38 10.0.0.230/xingdian/mysql:v1
+[root@nfs-harbor mysql]# docker push 10.0.0.230/xingdian/mysql:v1
+```
+
+#### 4.admin_service部署
+
+Dockerfile创建:
+
+```shell
+[root@nfs-harbor jdk]# cat Dockerfile
+FROM xingdian
+MAINTAINER "xingdian"
+ADD jdk-8u211-linux-x64.tar.gz /usr/local/
+RUN mv /usr/local/jdk1.8.0_211 /usr/local/java
+ENV JAVA_HOME /usr/local/java/
+ENV PATH $PATH:$JAVA_HOME/bin
+COPY tensquare_admin_service-1.0-SNAPSHOT.jar /usr/local
+EXPOSE 9001
+CMD java -jar /usr/local/tensquare_admin_service-1.0-SNAPSHOT.jar
+```
+
+镜像构建:
+
+```shell
+[root@nfs-harbor jdk]# docker build -t admin_service:v2022.1 .
+```
+
+镜像上传:
+
+```shell
+[root@nfs-harbor jdk]# docker tag admin_service:v2022.1 10.0.0.230/xingdian/admin_service:v2022.1
+[root@nfs-harbor jdk]# docker push 10.0.0.230/xingdian/admin_service:v2022.1
+```
+
+注意:
+
+ 在构建之前使用vim修改源码jar包,修改的内容如下(文件:application.yml):
+
+```yml
+spring:
+ application:
+ name: tensquare-admin-service #指定服务名
+ datasource:
+ driverClassName: com.mysql.jdbc.Driver
+ #数据库地址(修改)
+ url: jdbc:mysql://10.0.0.220:30023/tensquare_user?characterEncoding=UTF8&useSSL=false
+ #数据库账户名(修改)
+ username: root
+ #数据库账户密码(修改)
+ password: mysql
+ jpa:
+ database: mysql
+ show-sql: true
+
+#Eureka配置
+eureka:
+ client:
+ service-url:
+ #defaultZone: http://192.168.66.103:10086/eureka,http://192.168.66.104:10086/eureka
+ ##tensquare_eureka_server地址和端口(修改)
+ defaultZone: http://10.0.0.220:30020/eureka
+ instance:
+ lease-renewal-interval-in-seconds: 5 # 每隔5秒发送一次心跳
+ lease-expiration-duration-in-seconds: 10 # 10秒不发送就过期
+ prefer-ip-address: true
+
+
+ # jwt参数
+jwt:
+ config:
+ key: itcast
+ ttl: 1800000
+```
+
+#### 5.gathering部署
+
+Dockerfile创建:
+
+```shell
+[root@nfs-harbor jdk]# cat Dockerfile
+FROM xingdian
+MAINTAINER "xingdian"
+ADD jdk-8u211-linux-x64.tar.gz /usr/local/
+RUN mv /usr/local/jdk1.8.0_211 /usr/local/java
+ENV JAVA_HOME /usr/local/java/
+ENV PATH $PATH:$JAVA_HOME/bin
+COPY tensquare_gathering-1.0-SNAPSHOT.jar /usr/local
+CMD java -jar /usr/local/tensquare_gathering-1.0-SNAPSHOT.jar
+```
+
+镜像构建:
+
+```shell
+[root@nfs-harbor jdk]# docker build -t gathering:v2022.1 .
+```
+
+镜像上传:
+
+```shell
+[root@nfs-harbor jdk]# docker tag gathering:v2022.1 10.0.0.230/xingdian/gathering:v2022.1
+[root@nfs-harbor jdk]# docker push 10.0.0.230/xingdian/gathering:v2022.1
+```
+
+仓库验证:
+
+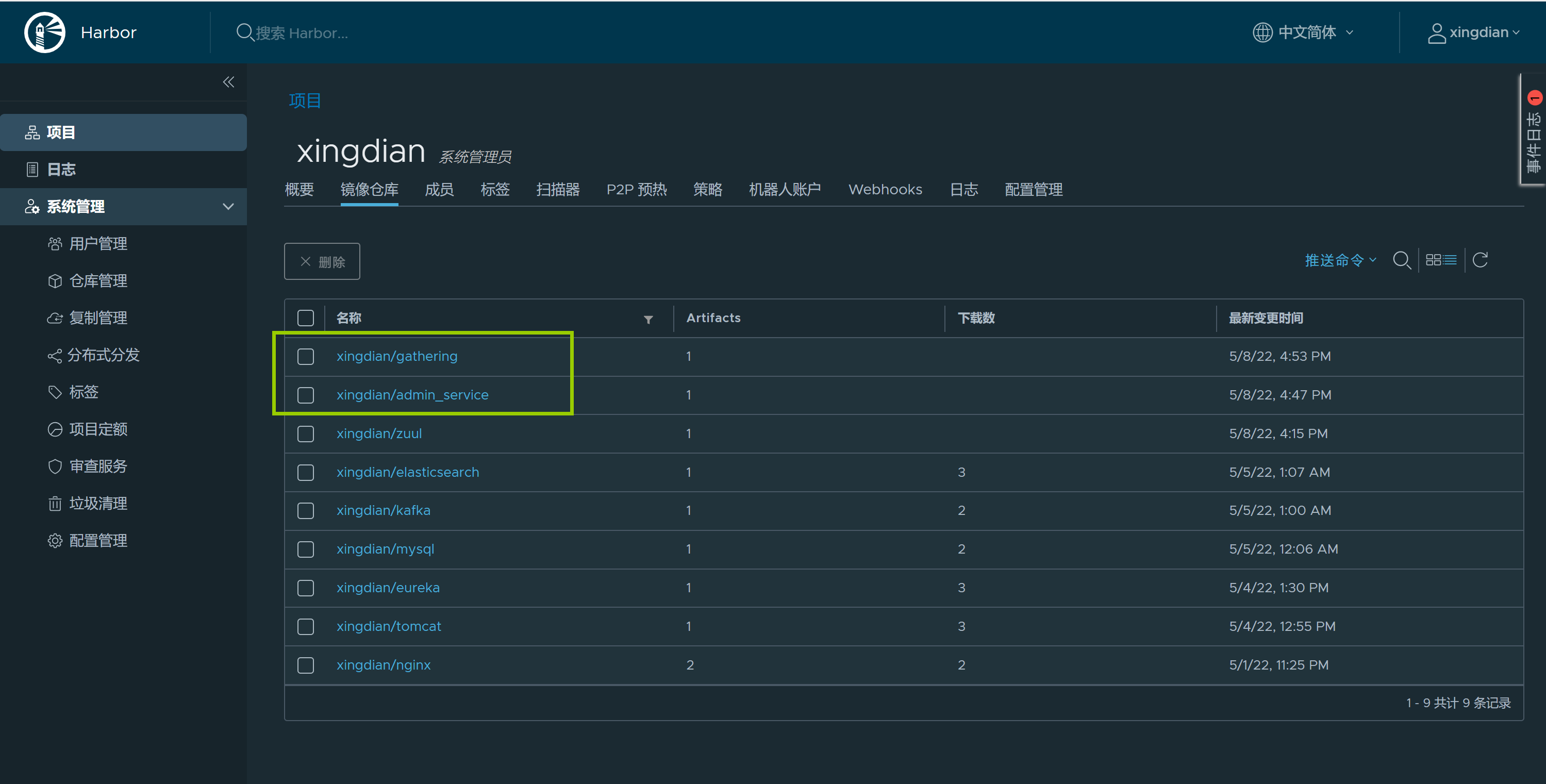 +
+注意:
+
+
+
+```yml
+server:
+ port: 9002
+spring:
+ application:
+ name: tensquare-gathering #指定服务名
+ datasource:
+ driverClassName: com.mysql.jdbc.Driver
+ #数据库地址(修改)
+ url: jdbc:mysql://10.0.0.220:30023/tensquare_gathering?characterEncoding=UTF8&useSSL=false
+ #数据库地址(修改)
+ username: root
+ #数据库账户密码(修改)
+ password: mysql
+ jpa:
+ database: mysql
+ show-sql: true
+#Eureka客户端配置
+eureka:
+ client:
+ service-url:
+ #defaultZone: http://192.168.66.103:10086/eureka,http://192.168.66.104:10086/eureka
+ #tensquare_eureka_server地址和端口(修改)
+ defaultZone: http://10.0.0.220:30020/eureka
+ instance:
+ lease-renewal-interval-in-seconds: 5 # 每隔5秒发送一次心跳
+ lease-expiration-duration-in-seconds: 10 # 10秒不发送就过期
+ prefer-ip-address: true
+```
+
+## 四:kubernetes集群部署
+
+#### 1.所有镜像验证
+
+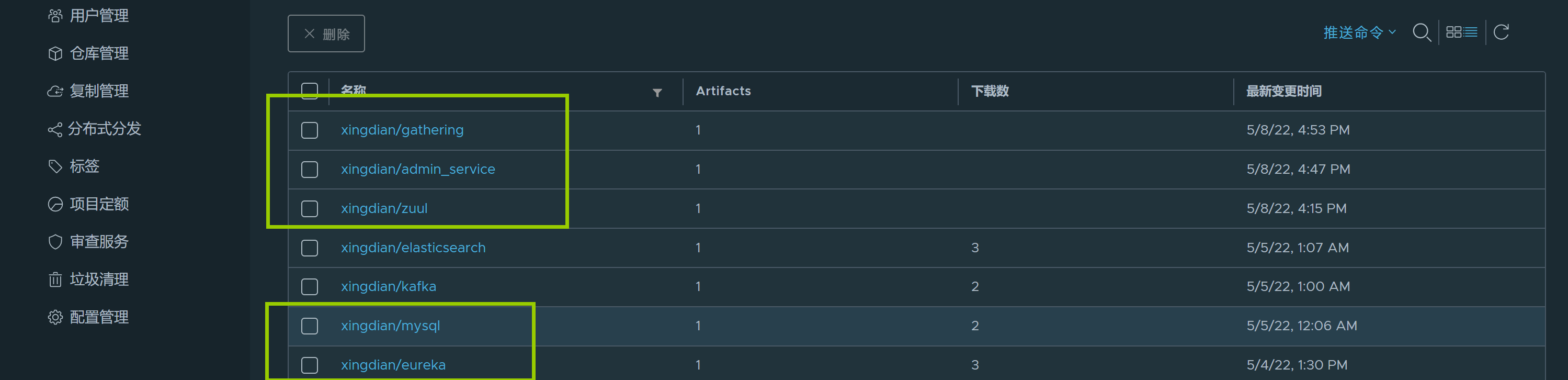
+#### 2.部署eureka
+
+Eureka之Deployment创建:
+
+```shell
+[root@master xingdian]# cat Eureka.yaml
+apiVersion: apps/v1
+kind: Deployment
+metadata:
+ name: eureka-deployment
+ labels:
+ app: eureka
+spec:
+ replicas: 1
+ selector:
+ matchLabels:
+ app: eureka
+ template:
+ metadata:
+ labels:
+ app: eureka
+ spec:
+ containers:
+ - name: nginx
+ image: 10.0.0.230/xingdian/eureka:v2022.1
+ ports:
+ - containerPort: 10086
+---
+apiVersion: v1
+kind: Service
+metadata:
+ name: eureka-service
+ labels:
+ app: eureka
+spec:
+ type: NodePort
+ ports:
+ - port: 10086
+ name: eureka
+ targetPort: 10086
+ nodePort: 30020
+ selector:
+ app: eureka
+```
+
+创建:
+
+```shell
+[root@master xingdian]# kubectl create -f Eureka.yaml
+deployment.apps/eureka-deployment created
+service/eureka-service created
+```
+
+验证:
+
+```shell
+[root@master xingdian]# kubectl get pod
+NAME READY STATUS RESTARTS AGE
+eureka-deployment-69c575d95-hx8s6 1/1 Running 0 2m20s
+[root@master xingdian]# kubectl get svc
+NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
+eureka-service NodePort 10.107.243.240 10086:30020/TCP 2m22s
+```
+
+
+
+注意:
+
+
+
+```yml
+server:
+ port: 9002
+spring:
+ application:
+ name: tensquare-gathering #指定服务名
+ datasource:
+ driverClassName: com.mysql.jdbc.Driver
+ #数据库地址(修改)
+ url: jdbc:mysql://10.0.0.220:30023/tensquare_gathering?characterEncoding=UTF8&useSSL=false
+ #数据库地址(修改)
+ username: root
+ #数据库账户密码(修改)
+ password: mysql
+ jpa:
+ database: mysql
+ show-sql: true
+#Eureka客户端配置
+eureka:
+ client:
+ service-url:
+ #defaultZone: http://192.168.66.103:10086/eureka,http://192.168.66.104:10086/eureka
+ #tensquare_eureka_server地址和端口(修改)
+ defaultZone: http://10.0.0.220:30020/eureka
+ instance:
+ lease-renewal-interval-in-seconds: 5 # 每隔5秒发送一次心跳
+ lease-expiration-duration-in-seconds: 10 # 10秒不发送就过期
+ prefer-ip-address: true
+```
+
+## 四:kubernetes集群部署
+
+#### 1.所有镜像验证
+
+
+#### 2.部署eureka
+
+Eureka之Deployment创建:
+
+```shell
+[root@master xingdian]# cat Eureka.yaml
+apiVersion: apps/v1
+kind: Deployment
+metadata:
+ name: eureka-deployment
+ labels:
+ app: eureka
+spec:
+ replicas: 1
+ selector:
+ matchLabels:
+ app: eureka
+ template:
+ metadata:
+ labels:
+ app: eureka
+ spec:
+ containers:
+ - name: nginx
+ image: 10.0.0.230/xingdian/eureka:v2022.1
+ ports:
+ - containerPort: 10086
+---
+apiVersion: v1
+kind: Service
+metadata:
+ name: eureka-service
+ labels:
+ app: eureka
+spec:
+ type: NodePort
+ ports:
+ - port: 10086
+ name: eureka
+ targetPort: 10086
+ nodePort: 30020
+ selector:
+ app: eureka
+```
+
+创建:
+
+```shell
+[root@master xingdian]# kubectl create -f Eureka.yaml
+deployment.apps/eureka-deployment created
+service/eureka-service created
+```
+
+验证:
+
+```shell
+[root@master xingdian]# kubectl get pod
+NAME READY STATUS RESTARTS AGE
+eureka-deployment-69c575d95-hx8s6 1/1 Running 0 2m20s
+[root@master xingdian]# kubectl get svc
+NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
+eureka-service NodePort 10.107.243.240 10086:30020/TCP 2m22s
+```
+
+ +
+#### 3.部署zuul
+
+zuul之Deployment创建:
+
+```shell
+[root@master xingdian]# cat Zuul.yaml
+apiVersion: apps/v1
+kind: Deployment
+metadata:
+ name: zuul-deployment
+ labels:
+ app: zuul
+spec:
+ replicas: 1
+ selector:
+ matchLabels:
+ app: zuul
+ template:
+ metadata:
+ labels:
+ app: zuul
+ spec:
+ containers:
+ - name: zuul
+ image: 10.0.0.230/xingdian/zuul:v2022.1
+ ports:
+ - containerPort: 10020
+---
+apiVersion: v1
+kind: Service
+metadata:
+ name: zuul-service
+ labels:
+ app: zuul
+spec:
+ type: NodePort
+ ports:
+ - port: 10020
+ name: zuul
+ targetPort: 10086
+ nodePort: 30021
+ selector:
+ app: zuul
+```
+
+创建:
+
+```shell
+[root@master xingdian]# kubectl create -f Zuul.yaml
+```
+
+验证:
+
+```shell
+[root@master xingdian]# kubectl get pod
+NAME READY STATUS RESTARTS AGE
+eureka-deployment-69c575d95-hx8s6 1/1 Running 0 7m42s
+zuul-deployment-6d76647cf9-6rmdj 1/1 Running 0 10s
+[root@master xingdian]# kubectl get svc
+NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
+eureka-service NodePort 10.107.243.240 10086:30020/TCP 7m37s
+kubernetes ClusterIP 10.96.0.1 443/TCP 11d
+zuul-service NodePort 10.103.35.255 10020:30021/TCP 5s
+```
+
+验证是否加入注册中心:
+
+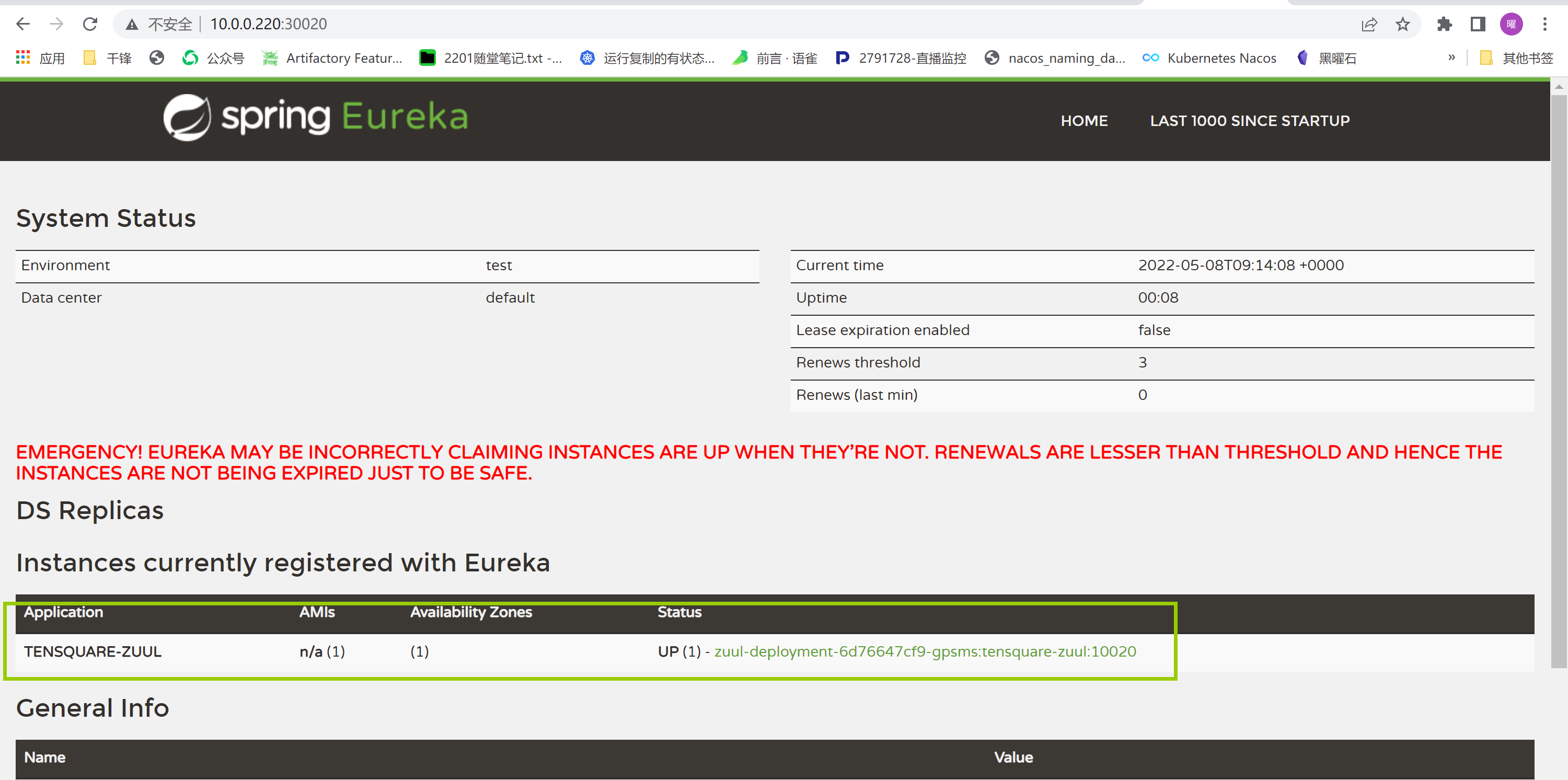
+
+#### 4.mysql部署
+
+mysql之rc和svc创建:
+
+```shell
+[root@master mysql]# cat mysql-svc.yaml
+apiVersion: v1
+kind: Service
+metadata:
+ name: mysql-svc
+ labels:
+ name: mysql-svc
+spec:
+ type: NodePort
+ ports:
+ - port: 3306
+ protocol: TCP
+ targetPort: 3306
+ name: http
+ nodePort: 30023
+ selector:
+ name: mysql-pod
+[root@master mysql]# cat mysql-rc.yaml
+apiVersion: v1
+kind: ReplicationController
+metadata:
+ name: mysql-rc
+ labels:
+ name: mysql-rc
+spec:
+ replicas: 1
+ selector:
+ name: mysql-pod
+ template:
+ metadata:
+ labels:
+ name: mysql-pod
+ spec:
+ containers:
+ - name: mysql
+ image: 10.0.0.230/xingdian/mysql:v1
+ imagePullPolicy: IfNotPresent
+ ports:
+ - containerPort: 3306
+ env:
+ - name: MYSQL_ROOT_PASSWORD
+ value: "mysql"
+```
+
+创建:
+
+```shell
+[root@master mysql]# kubectl create -f mysql-rc.yaml
+replicationcontroller/mysql-rc created
+[root@master mysql]# kubectl create -f mysql-svc.yaml
+service/mysql-svc created
+```
+
+验证:
+
+```shell
+[root@master mysql]# kubectl get pod
+NAME READY STATUS RESTARTS AGE
+eureka-deployment-69c575d95-hx8s6 1/1 Running 0 29m
+mysql-rc-sbdcl 1/1 Running 0 8m41s
+zuul-deployment-6d76647cf9-gpsms 1/1 Running 0 21m
+[root@master mysql]# kubectl get svc
+NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
+eureka-service NodePort 10.107.243.240 10086:30020/TCP 29m
+kubernetes ClusterIP 10.96.0.1 443/TCP 11d
+mysql-svc NodePort 10.98.4.62 3306:30023/TCP 9m1s
+zuul-service NodePort 10.103.35.255 10020:30021/TCP 22m
+```
+
+数据库创建:
+
+```shell
+[root@nfs-harbor ~]# mysql -u root -pmysql -h 10.0.0.220 -P 30023
+Welcome to the MariaDB monitor. Commands end with ; or \g.
+Your MySQL connection id is 2
+Server version: 5.7.38 MySQL Community Server (GPL)
+
+Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
+
+Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
+
+MySQL [(none)]> create database tensquare_user charset=utf8;
+Query OK, 1 row affected (0.00 sec)
+
+MySQL [(none)]> create database tensquare_gathering charset=utf8;
+Query OK, 1 row affected (0.01 sec)
+
+MySQL [(none)]> exit
+Bye
+```
+
+数据导入:
+
+```shell
+[root@nfs-harbor ~]# mysql -u root -pmysql -h 10.0.0.220 -P 30023
+Welcome to the MariaDB monitor. Commands end with ; or \g.
+Your MySQL connection id is 3
+Server version: 5.7.38 MySQL Community Server (GPL)
+
+Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
+
+Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
+
+MySQL [(none)]> source /var/ftp/share/tensquare_user.sql
+
+MySQL [tensquare_user]> source /var/ftp/share/tensquare_gathering.sql
+
+MySQL [tensquare_gathering]> exit
+Bye
+```
+
+验证:
+
+```shell
+[root@nfs-harbor ~]# mysql -u root -pmysql -h 10.0.0.220 -P 30023
+Welcome to the MariaDB monitor. Commands end with ; or \g.
+Your MySQL connection id is 3
+Server version: 5.7.38 MySQL Community Server (GPL)
+
+Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
+
+Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
+
+MySQL [(none)]> show databases;
++---------------------+
+| Database |
++---------------------+
+| information_schema |
+| mysql |
+| performance_schema |
+| sys |
+| tensquare_gathering |
+| tensquare_user |
++---------------------+
+6 rows in set (0.00 sec)
+
+MySQL [(none)]> use tensquare_gathering
+Reading table information for completion of table and column names
+You can turn off this feature to get a quicker startup with -A
+
+Database changed
+MySQL [tensquare_gathering]> show tables;
++-------------------------------+
+| Tables_in_tensquare_gathering |
++-------------------------------+
+| tb_city |
+| tb_gathering |
++-------------------------------+
+2 rows in set (0.00 sec)
+
+MySQL [tensquare_gathering]> use tensquare_user
+Reading table information for completion of table and column names
+You can turn off this feature to get a quicker startup with -A
+
+Database changed
+MySQL [tensquare_user]> show tables;
++--------------------------+
+| Tables_in_tensquare_user |
++--------------------------+
+| tb_admin |
++--------------------------+
+1 row in set (0.01 sec)
+```
+
+#### 5.admin_service部署
+
+admin_service之Deployment创建:
+
+```shell
+[root@master xingdian]# cat Admin-service.yaml
+apiVersion: apps/v1
+kind: Deployment
+metadata:
+ name: admin-deployment
+ labels:
+ app: admin
+spec:
+ replicas: 1
+ selector:
+ matchLabels:
+ app: admin
+ template:
+ metadata:
+ labels:
+ app: admin
+ spec:
+ containers:
+ - name: admin
+ image: 10.0.0.230/xingdian/admin_service:v2022.1
+ ports:
+ - containerPort: 9001
+---
+apiVersion: v1
+kind: Service
+metadata:
+ name: admin-service
+ labels:
+ app: admin
+spec:
+ type: NodePort
+ ports:
+ - port: 9001
+ name: admin
+ targetPort: 9001
+ nodePort: 30024
+ selector:
+ app: admin
+```
+
+创建:
+
+```shell
+[root@master xingdian]# kubectl create -f Admin-service.yaml
+deployment.apps/admin-deployment created
+service/admin-service created
+```
+
+验证:
+
+```shell
+[root@master xingdian]# kubectl get pod
+NAME READY STATUS RESTARTS AGE
+admin-deployment-54c5664d69-l2lbc 1/1 Running 0 23s
+eureka-deployment-69c575d95-mrj66 1/1 Running 0 47m
+mysql-rc-zgxk4 1/1 Running 0 7m23s
+zuul-deployment-6d76647cf9-gpsms 1/1 Running 0 39m
+[root@master xingdian]# kubectl get svc
+NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
+admin-service NodePort 10.101.251.47 9001:30024/TCP 6s
+eureka-service NodePort 10.107.243.240 10086:30020/TCP 47m
+kubernetes ClusterIP 10.96.0.1 443/TCP 11d
+mysql-svc NodePort 10.98.4.62 3306:30023/TCP 26m
+zuul-service NodePort 10.103.35.255 10020:30021/TCP 39m
+```
+
+注册中心验证:
+
+
+
+#### 3.部署zuul
+
+zuul之Deployment创建:
+
+```shell
+[root@master xingdian]# cat Zuul.yaml
+apiVersion: apps/v1
+kind: Deployment
+metadata:
+ name: zuul-deployment
+ labels:
+ app: zuul
+spec:
+ replicas: 1
+ selector:
+ matchLabels:
+ app: zuul
+ template:
+ metadata:
+ labels:
+ app: zuul
+ spec:
+ containers:
+ - name: zuul
+ image: 10.0.0.230/xingdian/zuul:v2022.1
+ ports:
+ - containerPort: 10020
+---
+apiVersion: v1
+kind: Service
+metadata:
+ name: zuul-service
+ labels:
+ app: zuul
+spec:
+ type: NodePort
+ ports:
+ - port: 10020
+ name: zuul
+ targetPort: 10086
+ nodePort: 30021
+ selector:
+ app: zuul
+```
+
+创建:
+
+```shell
+[root@master xingdian]# kubectl create -f Zuul.yaml
+```
+
+验证:
+
+```shell
+[root@master xingdian]# kubectl get pod
+NAME READY STATUS RESTARTS AGE
+eureka-deployment-69c575d95-hx8s6 1/1 Running 0 7m42s
+zuul-deployment-6d76647cf9-6rmdj 1/1 Running 0 10s
+[root@master xingdian]# kubectl get svc
+NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
+eureka-service NodePort 10.107.243.240 10086:30020/TCP 7m37s
+kubernetes ClusterIP 10.96.0.1 443/TCP 11d
+zuul-service NodePort 10.103.35.255 10020:30021/TCP 5s
+```
+
+验证是否加入注册中心:
+
+
+
+#### 4.mysql部署
+
+mysql之rc和svc创建:
+
+```shell
+[root@master mysql]# cat mysql-svc.yaml
+apiVersion: v1
+kind: Service
+metadata:
+ name: mysql-svc
+ labels:
+ name: mysql-svc
+spec:
+ type: NodePort
+ ports:
+ - port: 3306
+ protocol: TCP
+ targetPort: 3306
+ name: http
+ nodePort: 30023
+ selector:
+ name: mysql-pod
+[root@master mysql]# cat mysql-rc.yaml
+apiVersion: v1
+kind: ReplicationController
+metadata:
+ name: mysql-rc
+ labels:
+ name: mysql-rc
+spec:
+ replicas: 1
+ selector:
+ name: mysql-pod
+ template:
+ metadata:
+ labels:
+ name: mysql-pod
+ spec:
+ containers:
+ - name: mysql
+ image: 10.0.0.230/xingdian/mysql:v1
+ imagePullPolicy: IfNotPresent
+ ports:
+ - containerPort: 3306
+ env:
+ - name: MYSQL_ROOT_PASSWORD
+ value: "mysql"
+```
+
+创建:
+
+```shell
+[root@master mysql]# kubectl create -f mysql-rc.yaml
+replicationcontroller/mysql-rc created
+[root@master mysql]# kubectl create -f mysql-svc.yaml
+service/mysql-svc created
+```
+
+验证:
+
+```shell
+[root@master mysql]# kubectl get pod
+NAME READY STATUS RESTARTS AGE
+eureka-deployment-69c575d95-hx8s6 1/1 Running 0 29m
+mysql-rc-sbdcl 1/1 Running 0 8m41s
+zuul-deployment-6d76647cf9-gpsms 1/1 Running 0 21m
+[root@master mysql]# kubectl get svc
+NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
+eureka-service NodePort 10.107.243.240 10086:30020/TCP 29m
+kubernetes ClusterIP 10.96.0.1 443/TCP 11d
+mysql-svc NodePort 10.98.4.62 3306:30023/TCP 9m1s
+zuul-service NodePort 10.103.35.255 10020:30021/TCP 22m
+```
+
+数据库创建:
+
+```shell
+[root@nfs-harbor ~]# mysql -u root -pmysql -h 10.0.0.220 -P 30023
+Welcome to the MariaDB monitor. Commands end with ; or \g.
+Your MySQL connection id is 2
+Server version: 5.7.38 MySQL Community Server (GPL)
+
+Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
+
+Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
+
+MySQL [(none)]> create database tensquare_user charset=utf8;
+Query OK, 1 row affected (0.00 sec)
+
+MySQL [(none)]> create database tensquare_gathering charset=utf8;
+Query OK, 1 row affected (0.01 sec)
+
+MySQL [(none)]> exit
+Bye
+```
+
+数据导入:
+
+```shell
+[root@nfs-harbor ~]# mysql -u root -pmysql -h 10.0.0.220 -P 30023
+Welcome to the MariaDB monitor. Commands end with ; or \g.
+Your MySQL connection id is 3
+Server version: 5.7.38 MySQL Community Server (GPL)
+
+Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
+
+Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
+
+MySQL [(none)]> source /var/ftp/share/tensquare_user.sql
+
+MySQL [tensquare_user]> source /var/ftp/share/tensquare_gathering.sql
+
+MySQL [tensquare_gathering]> exit
+Bye
+```
+
+验证:
+
+```shell
+[root@nfs-harbor ~]# mysql -u root -pmysql -h 10.0.0.220 -P 30023
+Welcome to the MariaDB monitor. Commands end with ; or \g.
+Your MySQL connection id is 3
+Server version: 5.7.38 MySQL Community Server (GPL)
+
+Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
+
+Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
+
+MySQL [(none)]> show databases;
++---------------------+
+| Database |
++---------------------+
+| information_schema |
+| mysql |
+| performance_schema |
+| sys |
+| tensquare_gathering |
+| tensquare_user |
++---------------------+
+6 rows in set (0.00 sec)
+
+MySQL [(none)]> use tensquare_gathering
+Reading table information for completion of table and column names
+You can turn off this feature to get a quicker startup with -A
+
+Database changed
+MySQL [tensquare_gathering]> show tables;
++-------------------------------+
+| Tables_in_tensquare_gathering |
++-------------------------------+
+| tb_city |
+| tb_gathering |
++-------------------------------+
+2 rows in set (0.00 sec)
+
+MySQL [tensquare_gathering]> use tensquare_user
+Reading table information for completion of table and column names
+You can turn off this feature to get a quicker startup with -A
+
+Database changed
+MySQL [tensquare_user]> show tables;
++--------------------------+
+| Tables_in_tensquare_user |
++--------------------------+
+| tb_admin |
++--------------------------+
+1 row in set (0.01 sec)
+```
+
+#### 5.admin_service部署
+
+admin_service之Deployment创建:
+
+```shell
+[root@master xingdian]# cat Admin-service.yaml
+apiVersion: apps/v1
+kind: Deployment
+metadata:
+ name: admin-deployment
+ labels:
+ app: admin
+spec:
+ replicas: 1
+ selector:
+ matchLabels:
+ app: admin
+ template:
+ metadata:
+ labels:
+ app: admin
+ spec:
+ containers:
+ - name: admin
+ image: 10.0.0.230/xingdian/admin_service:v2022.1
+ ports:
+ - containerPort: 9001
+---
+apiVersion: v1
+kind: Service
+metadata:
+ name: admin-service
+ labels:
+ app: admin
+spec:
+ type: NodePort
+ ports:
+ - port: 9001
+ name: admin
+ targetPort: 9001
+ nodePort: 30024
+ selector:
+ app: admin
+```
+
+创建:
+
+```shell
+[root@master xingdian]# kubectl create -f Admin-service.yaml
+deployment.apps/admin-deployment created
+service/admin-service created
+```
+
+验证:
+
+```shell
+[root@master xingdian]# kubectl get pod
+NAME READY STATUS RESTARTS AGE
+admin-deployment-54c5664d69-l2lbc 1/1 Running 0 23s
+eureka-deployment-69c575d95-mrj66 1/1 Running 0 47m
+mysql-rc-zgxk4 1/1 Running 0 7m23s
+zuul-deployment-6d76647cf9-gpsms 1/1 Running 0 39m
+[root@master xingdian]# kubectl get svc
+NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
+admin-service NodePort 10.101.251.47 9001:30024/TCP 6s
+eureka-service NodePort 10.107.243.240 10086:30020/TCP 47m
+kubernetes ClusterIP 10.96.0.1 443/TCP 11d
+mysql-svc NodePort 10.98.4.62 3306:30023/TCP 26m
+zuul-service NodePort 10.103.35.255 10020:30021/TCP 39m
+```
+
+注册中心验证:
+
+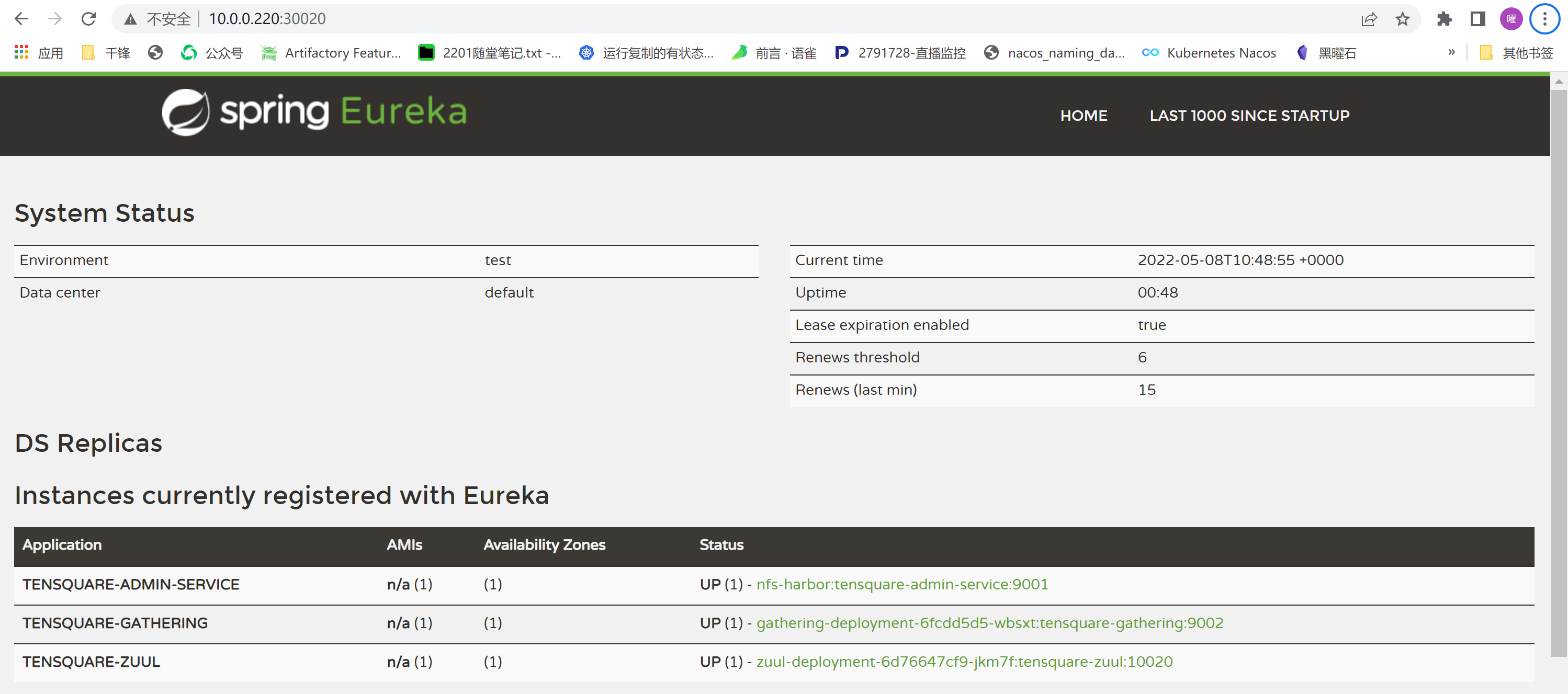 +
+#### 6.gathering部署
+
+gathering之Deployment创建:
+
+```shell
+[root@master xingdian]# cat Gathering.yaml
+apiVersion: apps/v1
+kind: Deployment
+metadata:
+ name: gathering-deployment
+ labels:
+ app: gathering
+spec:
+ replicas: 1
+ selector:
+ matchLabels:
+ app: gathering
+ template:
+ metadata:
+ labels:
+ app: gathering
+ spec:
+ containers:
+ - name: nginx
+ image: 10.0.0.230/xingdian/gathering:v2022.1
+ ports:
+ - containerPort: 9002
+---
+apiVersion: v1
+kind: Service
+metadata:
+ name: gathering-service
+ labels:
+ app: gathering
+spec:
+ type: NodePort
+ ports:
+ - port: 9002
+ name: gathering
+ targetPort: 9002
+ nodePort: 30022
+ selector:
+ app: gathering
+```
+
+创建:
+
+```shell
+[root@master xingdian]# kubectl create -f Gathering.yaml
+deployment.apps/gathering-deployment created
+service/gathering-service created
+```
+
+验证:
+
+```shell
+[root@master xingdian]# kubectl get pod
+NAME READY STATUS RESTARTS AGE
+admin-deployment-54c5664d69-2tqlw 1/1 Running 0 33s
+eureka-deployment-69c575d95-xzx9t 1/1 Running 0 13m
+gathering-deployment-6fcdd5d5-wbsxt 1/1 Running 0 27s
+mysql-rc-zgxk4 1/1 Running 0 28m
+zuul-deployment-6d76647cf9-jkm7f 1/1 Running 0 12m
+```
+
+注册中心验证:
+
+
+
+#### 6.gathering部署
+
+gathering之Deployment创建:
+
+```shell
+[root@master xingdian]# cat Gathering.yaml
+apiVersion: apps/v1
+kind: Deployment
+metadata:
+ name: gathering-deployment
+ labels:
+ app: gathering
+spec:
+ replicas: 1
+ selector:
+ matchLabels:
+ app: gathering
+ template:
+ metadata:
+ labels:
+ app: gathering
+ spec:
+ containers:
+ - name: nginx
+ image: 10.0.0.230/xingdian/gathering:v2022.1
+ ports:
+ - containerPort: 9002
+---
+apiVersion: v1
+kind: Service
+metadata:
+ name: gathering-service
+ labels:
+ app: gathering
+spec:
+ type: NodePort
+ ports:
+ - port: 9002
+ name: gathering
+ targetPort: 9002
+ nodePort: 30022
+ selector:
+ app: gathering
+```
+
+创建:
+
+```shell
+[root@master xingdian]# kubectl create -f Gathering.yaml
+deployment.apps/gathering-deployment created
+service/gathering-service created
+```
+
+验证:
+
+```shell
+[root@master xingdian]# kubectl get pod
+NAME READY STATUS RESTARTS AGE
+admin-deployment-54c5664d69-2tqlw 1/1 Running 0 33s
+eureka-deployment-69c575d95-xzx9t 1/1 Running 0 13m
+gathering-deployment-6fcdd5d5-wbsxt 1/1 Running 0 27s
+mysql-rc-zgxk4 1/1 Running 0 28m
+zuul-deployment-6d76647cf9-jkm7f 1/1 Running 0 12m
+```
+
+注册中心验证:
+
+ +
+#### 7.浏览器测试API接口
+
+
+
+
+
diff --git a/NEW/利用kubernetes部署网站项目.md b/NEW/利用kubernetes部署网站项目.md
new file mode 100644
index 0000000..162a431
--- /dev/null
+++ b/NEW/利用kubernetes部署网站项目.md
@@ -0,0 +1,335 @@
+
+
+#### 7.浏览器测试API接口
+
+
+
+
+
diff --git a/NEW/利用kubernetes部署网站项目.md b/NEW/利用kubernetes部署网站项目.md
new file mode 100644
index 0000000..162a431
--- /dev/null
+++ b/NEW/利用kubernetes部署网站项目.md
@@ -0,0 +1,335 @@
+利用kubernetes部署网站项目
+
+著作:行癫 <盗版必究>
+
+------
+
+## 一:环境准备
+
+#### 1.kubernetes集群
+
+集群正常运行,例如使用以下命令检查
+
+```shell
+[root@master ~]# kubectl get node
+NAME STATUS ROLES AGE VERSION
+master Ready control-plane,master 5d19h v1.23.1
+node-1 Ready 5d19h v1.23.1
+node-2 Ready 5d19h v1.23.1
+node-3 Ready 5d19h v1.23.1
+```
+
+#### 2.harbor私有仓库
+
+主要给kubernetes集群提供镜像服务
+
+ +## 二:项目部署
+
+#### 1.镜像构建
+
+软件下载地址:
+
+```shell
+wget https://nginx.org/download/nginx-1.20.2.tar.gz
+```
+
+项目包下载地址:
+
+```shell
+git clone https://github.com/blackmed/xingdian-project.git
+```
+
+构建centos基础镜像Dockerfile文件:
+
+```shell
+root@nfs-harbor ~]# cat Dockerfile
+FROM daocloud.io/centos:7
+MAINTAINER "xingdianvip@gmail.com"
+ENV container docker
+RUN yum -y swap -- remove fakesystemd -- install systemd systemd-libs
+RUN yum -y update; yum clean all; \
+(cd /lib/systemd/system/sysinit.target.wants/; for i in *; do [ $i == systemd-tmpfiles-setup.service ] || rm -f $i; done); \
+rm -f /lib/systemd/system/multi-user.target.wants/*;\
+rm -f /etc/systemd/system/*.wants/*;\
+rm -f /lib/systemd/system/local-fs.target.wants/*; \
+rm -f /lib/systemd/system/sockets.target.wants/*udev*; \
+rm -f /lib/systemd/system/sockets.target.wants/*initctl*; \
+rm -f /lib/systemd/system/basic.target.wants/*;\
+rm -f /lib/systemd/system/anaconda.target.wants/*;
+VOLUME [ "/sys/fs/cgroup" ]
+CMD ["/usr/sbin/init"]
+root@nfs-harbor ~]# docker bulid -t xingdian .
+```
+
+构建项目镜像:
+
+```shell
+[root@nfs-harbor nginx]# cat Dockerfile
+FROM xingdian
+ADD nginx-1.20.2.tar.gz /usr/local
+RUN rm -rf /etc/yum.repos.d/*
+COPY CentOS-Base.repo /etc/yum.repos.d/
+COPY epel.repo /etc/yum.repos.d/
+RUN yum clean all && yum makecache fast
+RUN yum -y install gcc gcc-c++ openssl openssl-devel pcre-devel zlib-devel make
+WORKDIR /usr/local/nginx-1.20.2
+RUN ./configure --prefix=/usr/local/nginx
+RUN make && make install
+WORKDIR /usr/local/nginx
+ENV PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/local/nginx/sbin
+EXPOSE 80
+RUN rm -rf /usr/local/nginx/conf/nginx.conf
+COPY nginx.conf /usr/local/nginx/conf/
+RUN mkdir /dist
+CMD ["nginx", "-g", "daemon off;"]
+[root@nfs-harbor nginx]# docker build -t nginx:v2 .
+```
+
+注意:
+
+ 需要事先准备好Centos的Base仓库和epel仓库
+
+#### 2.上传项目到harbor
+
+修改镜像tag:
+
+```shell
+[root@nfs-harbor ~]# docker tag nginx:v2 10.0.0.230/xingdian/nginx:v2
+```
+
+登录私有仓库:
+
+```shell
+[root@nfs-harbor ~]# docker login 10.0.0.230
+Username: xingdian
+Password:
+```
+
+上传镜像:
+
+```shell
+[root@nfs-harbor ~]# docker push 10.0.0.230/xingdian/nginx:v2
+```
+
+注意:
+
+ 默认上传时采用https,因为我们部署的harbor使用的是http,所以再上传之前按照3-1进行修改
+
+#### 3.kubernetes集群连接harbor
+
+修改所有kubernetes集群能够访问http仓库,默认访问的是https
+
+```shell
+[root@master ~]# vim /etc/systemd/system/multi-user.target.wants/docker.service
+ExecStart=/usr/bin/dockerd -H fd:// --insecure-registry 10.0.1.13 --containerd=/run/containerd/containerd.sock
+[root@master ~]# systemctl daemon-reload
+[root@master ~]# systemctl restart docker
+```
+
+kubernetes集群创建secret用于连接harbor
+
+```shell
+[root@master ~]# kubectl create secret docker-registry regcred --docker-server=10.0.0.230 --docker-username=diange --docker-password=QianFeng@123
+[root@master ~]# kubectl get secret
+NAME TYPE DATA AGE
+regcred kubernetes.io/dockerconfigjson 1 19h
+```
+
+注意:
+
+ regcred:secret的名字
+
+ --docker-server:指定服务器的地址
+
+ --docker-username:指定harbor的用户
+
+ --docker-password:指定harbor的密码
+
+#### 4.部署NFS
+
+部署NFS目的是为了给kubernetes集群提供持久化存储,kubernetes集群也要安装nfs-utils目的是为了支持nfs文件系统
+
+```shell
+[root@nfs-harbor ~]# yum -y install nfs-utils
+[root@nfs-harbor ~]# systemctl start nfs
+[root@nfs-harbor ~]# systemctl enable nfs
+```
+
+创建共享目录并对外共享
+
+```shell
+[root@nfs-harbor ~]# mkdir /kubernetes-1
+[root@nfs-harbor ~]# cat /etc/exports
+/kubernetes-1 *(rw,no_root_squash,sync)
+[root@nfs-harbor ~]# exportfs -rv
+```
+
+项目放入共享目录下
+
+```shell
+[root@nfs-harbor ~]# git clone https://github.com/blackmed/xingdian-project.git
+[root@nfs-harbor ~]# unzip dist.zip
+[root@nfs-harbor ~]# cp -r dist/* /kubernetes-1
+```
+
+#### 5.创建statefulset部署项目
+
+该yaml文件中除了statefulset以外还有service、PersistentVolume、StorageClass
+
+```shell
+[root@master xingdian]# cat Statefulset.yaml
+apiVersion: v1
+kind: Service
+metadata:
+ name: nginx
+ labels:
+ app: nginx
+spec:
+ type: NodePort
+ ports:
+ - port: 80
+ name: web
+ targetPort: 80
+ nodePort: 30010
+ selector:
+ app: nginx
+---
+apiVersion: storage.k8s.io/v1
+kind: StorageClass
+metadata:
+ name: xingdian
+provisioner: example.com/external-nfs
+parameters:
+ server: 10.0.0.230
+ path: /kubernetes-1
+ readOnly: "false"
+---
+apiVersion: v1
+kind: PersistentVolume
+metadata:
+ name: xingdian-1
+spec:
+ capacity:
+ storage: 1Gi
+ volumeMode: Filesystem
+ accessModes:
+ - ReadWriteOnce
+ storageClassName: xingdian
+ nfs:
+ path: /kubernetes-1
+ server: 10.0.0.230
+---
+apiVersion: v1
+kind: PersistentVolume
+metadata:
+ name: xingdian-2
+spec:
+ capacity:
+ storage: 1Gi
+ volumeMode: Filesystem
+ accessModes:
+ - ReadWriteOnce
+ storageClassName: xingdian
+ nfs:
+ path: /kubernetes-1
+ server: 10.0.0.230
+---
+apiVersion: apps/v1
+kind: StatefulSet
+metadata:
+ name: web
+spec:
+ selector:
+ matchLabels:
+ app: nginx
+ serviceName: "nginx"
+ replicas: 2
+ template:
+ metadata:
+ labels:
+ app: nginx
+ spec:
+ terminationGracePeriodSeconds: 10
+ containers:
+ - name: nginx
+ image: 10.0.0.230/xingdian/nginx:v2
+ ports:
+ - containerPort: 80
+ name: web
+ volumeMounts:
+ - name: www
+ mountPath: /dist
+ volumeClaimTemplates:
+ - metadata:
+ name: www
+ spec:
+ accessModes: [ "ReadWriteOnce" ]
+ storageClassName: "xingdian"
+ resources:
+ requests:
+ storage: 1Gi
+```
+
+#### 6.运行
+
+```shell
+[root@master xingdian]# kubectl create -f Statefulset.yaml
+service/nginx created
+storageclass.storage.k8s.io/xingdian created
+persistentvolume/xingdian-1 created
+persistentvolume/xingdian-2 created
+statefulset.apps/web created
+```
+
+## 三:项目验证
+
+#### 1.pv验证
+
+```shell
+[root@master xingdian]# kubectl get pv
+NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
+xingdian-1 1Gi RWO Retain Bound default/www-web-1 xingdian 9m59s
+xingdian-2 1Gi RWO Retain Bound default/www-web-0 xingdian 9m59s
+```
+
+#### 2.pvc验证
+
+```shell
+[root@master xingdian]# kubectl get pvc
+NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
+www-web-0 Bound xingdian-2 1Gi RWO xingdian 10m
+www-web-1 Bound xingdian-1 1Gi RWO xingdian 10m
+```
+
+#### 3.storageClass验证
+
+```shell
+[root@master xingdian]# kubectl get storageclass
+NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
+xingdian example.com/external-nfs Delete Immediate false 10m
+```
+
+#### 4.statefulset验证
+
+```shell
+[root@master xingdian]# kubectl get statefulset
+NAME READY AGE
+web 2/2 13m
+[root@master xingdian]# kubectl get pod
+NAME READY STATUS RESTARTS AGE
+web-0 1/1 Running 0 13m
+web-1 1/1 Running 0 13m
+```
+
+#### 5.service验证
+
+```shell
+[root@master xingdian]# kubectl get svc
+NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
+nginx NodePort 10.111.189.32 80:30010/TCP 13m
+```
+
+#### 6.浏览器访问
+
+
+## 二:项目部署
+
+#### 1.镜像构建
+
+软件下载地址:
+
+```shell
+wget https://nginx.org/download/nginx-1.20.2.tar.gz
+```
+
+项目包下载地址:
+
+```shell
+git clone https://github.com/blackmed/xingdian-project.git
+```
+
+构建centos基础镜像Dockerfile文件:
+
+```shell
+root@nfs-harbor ~]# cat Dockerfile
+FROM daocloud.io/centos:7
+MAINTAINER "xingdianvip@gmail.com"
+ENV container docker
+RUN yum -y swap -- remove fakesystemd -- install systemd systemd-libs
+RUN yum -y update; yum clean all; \
+(cd /lib/systemd/system/sysinit.target.wants/; for i in *; do [ $i == systemd-tmpfiles-setup.service ] || rm -f $i; done); \
+rm -f /lib/systemd/system/multi-user.target.wants/*;\
+rm -f /etc/systemd/system/*.wants/*;\
+rm -f /lib/systemd/system/local-fs.target.wants/*; \
+rm -f /lib/systemd/system/sockets.target.wants/*udev*; \
+rm -f /lib/systemd/system/sockets.target.wants/*initctl*; \
+rm -f /lib/systemd/system/basic.target.wants/*;\
+rm -f /lib/systemd/system/anaconda.target.wants/*;
+VOLUME [ "/sys/fs/cgroup" ]
+CMD ["/usr/sbin/init"]
+root@nfs-harbor ~]# docker bulid -t xingdian .
+```
+
+构建项目镜像:
+
+```shell
+[root@nfs-harbor nginx]# cat Dockerfile
+FROM xingdian
+ADD nginx-1.20.2.tar.gz /usr/local
+RUN rm -rf /etc/yum.repos.d/*
+COPY CentOS-Base.repo /etc/yum.repos.d/
+COPY epel.repo /etc/yum.repos.d/
+RUN yum clean all && yum makecache fast
+RUN yum -y install gcc gcc-c++ openssl openssl-devel pcre-devel zlib-devel make
+WORKDIR /usr/local/nginx-1.20.2
+RUN ./configure --prefix=/usr/local/nginx
+RUN make && make install
+WORKDIR /usr/local/nginx
+ENV PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/local/nginx/sbin
+EXPOSE 80
+RUN rm -rf /usr/local/nginx/conf/nginx.conf
+COPY nginx.conf /usr/local/nginx/conf/
+RUN mkdir /dist
+CMD ["nginx", "-g", "daemon off;"]
+[root@nfs-harbor nginx]# docker build -t nginx:v2 .
+```
+
+注意:
+
+ 需要事先准备好Centos的Base仓库和epel仓库
+
+#### 2.上传项目到harbor
+
+修改镜像tag:
+
+```shell
+[root@nfs-harbor ~]# docker tag nginx:v2 10.0.0.230/xingdian/nginx:v2
+```
+
+登录私有仓库:
+
+```shell
+[root@nfs-harbor ~]# docker login 10.0.0.230
+Username: xingdian
+Password:
+```
+
+上传镜像:
+
+```shell
+[root@nfs-harbor ~]# docker push 10.0.0.230/xingdian/nginx:v2
+```
+
+注意:
+
+ 默认上传时采用https,因为我们部署的harbor使用的是http,所以再上传之前按照3-1进行修改
+
+#### 3.kubernetes集群连接harbor
+
+修改所有kubernetes集群能够访问http仓库,默认访问的是https
+
+```shell
+[root@master ~]# vim /etc/systemd/system/multi-user.target.wants/docker.service
+ExecStart=/usr/bin/dockerd -H fd:// --insecure-registry 10.0.1.13 --containerd=/run/containerd/containerd.sock
+[root@master ~]# systemctl daemon-reload
+[root@master ~]# systemctl restart docker
+```
+
+kubernetes集群创建secret用于连接harbor
+
+```shell
+[root@master ~]# kubectl create secret docker-registry regcred --docker-server=10.0.0.230 --docker-username=diange --docker-password=QianFeng@123
+[root@master ~]# kubectl get secret
+NAME TYPE DATA AGE
+regcred kubernetes.io/dockerconfigjson 1 19h
+```
+
+注意:
+
+ regcred:secret的名字
+
+ --docker-server:指定服务器的地址
+
+ --docker-username:指定harbor的用户
+
+ --docker-password:指定harbor的密码
+
+#### 4.部署NFS
+
+部署NFS目的是为了给kubernetes集群提供持久化存储,kubernetes集群也要安装nfs-utils目的是为了支持nfs文件系统
+
+```shell
+[root@nfs-harbor ~]# yum -y install nfs-utils
+[root@nfs-harbor ~]# systemctl start nfs
+[root@nfs-harbor ~]# systemctl enable nfs
+```
+
+创建共享目录并对外共享
+
+```shell
+[root@nfs-harbor ~]# mkdir /kubernetes-1
+[root@nfs-harbor ~]# cat /etc/exports
+/kubernetes-1 *(rw,no_root_squash,sync)
+[root@nfs-harbor ~]# exportfs -rv
+```
+
+项目放入共享目录下
+
+```shell
+[root@nfs-harbor ~]# git clone https://github.com/blackmed/xingdian-project.git
+[root@nfs-harbor ~]# unzip dist.zip
+[root@nfs-harbor ~]# cp -r dist/* /kubernetes-1
+```
+
+#### 5.创建statefulset部署项目
+
+该yaml文件中除了statefulset以外还有service、PersistentVolume、StorageClass
+
+```shell
+[root@master xingdian]# cat Statefulset.yaml
+apiVersion: v1
+kind: Service
+metadata:
+ name: nginx
+ labels:
+ app: nginx
+spec:
+ type: NodePort
+ ports:
+ - port: 80
+ name: web
+ targetPort: 80
+ nodePort: 30010
+ selector:
+ app: nginx
+---
+apiVersion: storage.k8s.io/v1
+kind: StorageClass
+metadata:
+ name: xingdian
+provisioner: example.com/external-nfs
+parameters:
+ server: 10.0.0.230
+ path: /kubernetes-1
+ readOnly: "false"
+---
+apiVersion: v1
+kind: PersistentVolume
+metadata:
+ name: xingdian-1
+spec:
+ capacity:
+ storage: 1Gi
+ volumeMode: Filesystem
+ accessModes:
+ - ReadWriteOnce
+ storageClassName: xingdian
+ nfs:
+ path: /kubernetes-1
+ server: 10.0.0.230
+---
+apiVersion: v1
+kind: PersistentVolume
+metadata:
+ name: xingdian-2
+spec:
+ capacity:
+ storage: 1Gi
+ volumeMode: Filesystem
+ accessModes:
+ - ReadWriteOnce
+ storageClassName: xingdian
+ nfs:
+ path: /kubernetes-1
+ server: 10.0.0.230
+---
+apiVersion: apps/v1
+kind: StatefulSet
+metadata:
+ name: web
+spec:
+ selector:
+ matchLabels:
+ app: nginx
+ serviceName: "nginx"
+ replicas: 2
+ template:
+ metadata:
+ labels:
+ app: nginx
+ spec:
+ terminationGracePeriodSeconds: 10
+ containers:
+ - name: nginx
+ image: 10.0.0.230/xingdian/nginx:v2
+ ports:
+ - containerPort: 80
+ name: web
+ volumeMounts:
+ - name: www
+ mountPath: /dist
+ volumeClaimTemplates:
+ - metadata:
+ name: www
+ spec:
+ accessModes: [ "ReadWriteOnce" ]
+ storageClassName: "xingdian"
+ resources:
+ requests:
+ storage: 1Gi
+```
+
+#### 6.运行
+
+```shell
+[root@master xingdian]# kubectl create -f Statefulset.yaml
+service/nginx created
+storageclass.storage.k8s.io/xingdian created
+persistentvolume/xingdian-1 created
+persistentvolume/xingdian-2 created
+statefulset.apps/web created
+```
+
+## 三:项目验证
+
+#### 1.pv验证
+
+```shell
+[root@master xingdian]# kubectl get pv
+NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
+xingdian-1 1Gi RWO Retain Bound default/www-web-1 xingdian 9m59s
+xingdian-2 1Gi RWO Retain Bound default/www-web-0 xingdian 9m59s
+```
+
+#### 2.pvc验证
+
+```shell
+[root@master xingdian]# kubectl get pvc
+NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
+www-web-0 Bound xingdian-2 1Gi RWO xingdian 10m
+www-web-1 Bound xingdian-1 1Gi RWO xingdian 10m
+```
+
+#### 3.storageClass验证
+
+```shell
+[root@master xingdian]# kubectl get storageclass
+NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
+xingdian example.com/external-nfs Delete Immediate false 10m
+```
+
+#### 4.statefulset验证
+
+```shell
+[root@master xingdian]# kubectl get statefulset
+NAME READY AGE
+web 2/2 13m
+[root@master xingdian]# kubectl get pod
+NAME READY STATUS RESTARTS AGE
+web-0 1/1 Running 0 13m
+web-1 1/1 Running 0 13m
+```
+
+#### 5.service验证
+
+```shell
+[root@master xingdian]# kubectl get svc
+NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
+nginx NodePort 10.111.189.32 80:30010/TCP 13m
+```
+
+#### 6.浏览器访问
+
+ diff --git a/NEW/基于Kubernetes构建ES集群.md b/NEW/基于Kubernetes构建ES集群.md
new file mode 100644
index 0000000..7a91dce
--- /dev/null
+++ b/NEW/基于Kubernetes构建ES集群.md
@@ -0,0 +1,314 @@
+
diff --git a/NEW/基于Kubernetes构建ES集群.md b/NEW/基于Kubernetes构建ES集群.md
new file mode 100644
index 0000000..7a91dce
--- /dev/null
+++ b/NEW/基于Kubernetes构建ES集群.md
@@ -0,0 +1,314 @@
+基于Kubernetes集群构建ES集群
+
+作者:行癫(盗版必究)
+
+------
+
+## 一:环境准备
+
+#### 1.Kubernetes集群环境
+
+| 节点 | 地址 |
+| :---------------: | :---------: |
+| Kubernetes-Master | 10.9.12.206 |
+| Kubernetes-Node-1 | 10.9.12.205 |
+| Kubernetes-Node-2 | 10.9.12.204 |
+| Kubernetes-Node-3 | 10.9.12.203 |
+| DNS服务器 | 10.9.12.210 |
+| 代理服务器 | 10.9.12.209 |
+| NFS存储 | 10.9.12.250 |
+
+#### 2.Kuboard集群管理
+
+
+
+## 二:构建ES集群
+
+#### 1.持久化存储构建
+
+1.NFS服务器部署
+
+ 略
+
+2.创建共享目录
+
+ 本次采用脚本创建,脚本如下
+
+```shell
+[root@xingdiancloud-1 ~]# cat nfs.sh
+#!/bin/bash
+read -p "请输入您要创建的共享目录:" dir
+if [ -d $dir ];then
+ echo "请重新输入共享目录: "
+ read again_dir
+ mkdir $again_dir -p
+ echo "共享目录创建成功"
+ read -p "请输入共享对象:" ips
+ echo "$again_dir ${ips}(rw,sync,no_root_squash)" >> /etc/exports
+ xingdian=`cat /etc/exports |grep "$again_dir" |wc -l`
+ if [ $xingdian -eq 1 ];then
+ echo "成功配置共享"
+ exportfs -rv >/dev/null
+ exit
+ else
+ exit
+ fi
+else
+ mkdir $dir -p
+ echo "共享目录创建成功"
+ read -p "请输入共享对象:" ips
+ echo "$dir ${ips}(rw,sync,no_root_squash)" >> /etc/exports
+ xingdian=`cat /etc/exports |grep "$dir" |wc -l`
+ if [ $xingdian -eq 1 ];then
+ echo "成功配置共享"
+ exportfs -rv >/dev/null
+ exit
+ else
+ exit
+ fi
+fi
+```
+
+3.创建存储类
+
+```yaml
+[root@xingdiancloud-master ~]# vim namespace.yaml
+apiVersion: v1
+kind: Namespace
+metadata:
+ name: logging
+[root@xingdiancloud-master ~]# vim storageclass.yaml
+apiVersion: storage.k8s.io/v1
+kind: StorageClass
+metadata:
+ annotations:
+ k8s.kuboard.cn/storageNamespace: logging
+ k8s.kuboard.cn/storageType: nfs_client_provisioner
+ name: data-es
+parameters:
+ archiveOnDelete: 'false'
+provisioner: nfs-data-es
+reclaimPolicy: Retain
+volumeBindingMode: Immediate
+```
+
+4.创建存储卷
+
+```yaml
+[root@xingdiancloud-master ~]# vim persistenVolume.yaml
+apiVersion: v1
+kind: PersistentVolume
+metadata:
+ annotations:
+ pv.kubernetes.io/bound-by-controller: 'yes'
+ finalizers:
+ - kubernetes.io/pv-protection
+ name: nfs-pv-data-es
+spec:
+ accessModes:
+ - ReadWriteMany
+ capacity:
+ storage: 100Gi
+ claimRef:
+ apiVersion: v1
+ kind: PersistentVolumeClaim
+ name: nfs-pvc-data-es
+ namespace: kube-system
+ nfs:
+ path: /data/es-data
+ server: 10.9.12.250
+ persistentVolumeReclaimPolicy: Retain
+ storageClassName: nfs-storageclass-provisioner
+ volumeMode: Filesystem
+```
+
+注意:存储类和存储卷也可以使用Kuboard界面创建
+
+#### 2.设定节点标签
+
+```shell
+[root@xingdiancloud-master ~]# kubectl label nodes xingdiancloud-node-1 es=log
+```
+
+注意:
+
+ 所有运行ES的节点需要进行标签的设定
+
+ 目的配合接下来的StatefulSet部署ES集群
+
+#### 3.ES集群部署
+
+ 注意:由于ES集群每个节点需要唯一的网络标识,并需要持久化存储,Deployment不能实现该特点只能进行无状态应用的部署,故本次将采用StatefulSet进行部署。
+
+```yaml
+apiVersion: apps/v1
+kind: StatefulSet
+metadata:
+ name: es
+ namespace: logging
+spec:
+ serviceName: elasticsearch
+ replicas: 3
+ selector:
+ matchLabels:
+ app: elasticsearch
+ template:
+ metadata:
+ labels:
+ app: elasticsearch
+ spec:
+ nodeSelector:
+ es: log
+ initContainers:
+ - name: increase-vm-max-map
+ image: busybox
+ command: ["sysctl", "-w", "vm.max_map_count=262144"]
+ securityContext:
+ privileged: true
+ - name: increase-fd-ulimit
+ image: busybox
+ command: ["sh", "-c", "ulimit -n 65536"]
+ securityContext:
+ privileged: true
+ containers:
+ - name: elasticsearch
+ image: docker.elastic.co/elasticsearch/elasticsearch:7.6.2
+ ports:
+ - name: rest
+ containerPort: 9200
+ - name: inter
+ containerPort: 9300
+ resources:
+ limits:
+ cpu: 500m
+ memory: 4000Mi
+ requests:
+ cpu: 500m
+ memory: 3000Mi
+ volumeMounts:
+ - name: data
+ mountPath: /usr/share/elasticsearch/data
+ env:
+ - name: cluster.name
+ value: k8s-logs
+ - name: node.name
+ valueFrom:
+ fieldRef:
+ fieldPath: metadata.name
+ - name: cluster.initial_master_nodes
+ value: "es-0,es-1,es-2"
+ - name: discovery.zen.minimum_master_nodes
+ value: "2"
+ - name: discovery.seed_hosts
+ value: "elasticsearch"
+ - name: ESJAVAOPTS
+ value: "-Xms512m -Xmx512m"
+ - name: network.host
+ value: "0.0.0.0"
+ - name: node.max_local_storage_nodes
+ value: "3"
+ volumeClaimTemplates:
+ - metadata:
+ name: data
+ labels:
+ app: elasticsearch
+ spec:
+ accessModes: [ "ReadWriteMany" ]
+ storageClassName: data-es
+ resources:
+ requests:
+ storage: 25Gi
+```
+
+#### 4.创建Services发布ES集群
+
+```yaml
+[root@xingdiancloud-master ~]# vim elasticsearch-svc.yaml
+kind: Service
+apiVersion: v1
+metadata:
+ name: elasticsearch
+ namespace: logging
+ labels:
+ app: elasticsearch
+spec:
+ selector:
+ app: elasticsearch
+ type: NodePort
+ ports:
+ - port: 9200
+ targetPort: 9200
+ nodePort: 30010
+ name: rest
+ - port: 9300
+ name: inter-node
+```
+
+#### 5.访问测试
+
+注意:
+
+ 使用elasticVUE插件访问集群
+
+ 集群状态正常
+
+ 集群所有节点正常
+
+
+
+## 三:代理及DNS配置
+
+#### 1.代理配置
+
+注意:
+
+ 部署略
+
+ 在此使用Nginx作为代理
+
+ 基于用户的访问控制用户和密码自行创建(htpasswd)
+
+ 配置文件如下
+
+```shell
+[root@proxy ~]# cat /etc/nginx/conf.d/elasticsearch.conf
+server {
+ listen 80;
+ server_name es.xingdian.com;
+ location / {
+ auth_basic "xingdiancloud kibana";
+ auth_basic_user_file /etc/nginx/pass;
+ proxy_pass http://地址+端口;
+
+ }
+
+
+}
+```
+
+#### 2.域名解析配置
+
+注意:
+
+ 部署略
+
+ 配置如下
+
+```shell
+[root@www ~]# cat /var/named/xingdian.com.zone
+$TTL 1D
+@ IN SOA @ rname.invalid. (
+ 0 ; serial
+ 1D ; refresh
+ 1H ; retry
+ 1W ; expire
+ 3H ) ; minimum
+ NS @
+ A DNS地址
+es A 代理地址
+ AAAA ::1
+```
+
+#### 3.访问测试
+
+ 略
\ No newline at end of file
diff --git a/NEW/基于kubernetes部署Prometheus和Grafana.md b/NEW/基于kubernetes部署Prometheus和Grafana.md
new file mode 100644
index 0000000..16e4811
--- /dev/null
+++ b/NEW/基于kubernetes部署Prometheus和Grafana.md
@@ -0,0 +1,684 @@
+基于kubernetes部署Prometheus和Grafana
+
+著作:行癫 <盗版必究>
+
+------
+
+## 一:环境准备
+
+#### 1.kubernetes集群正常
+
+```shell
+[root@master ~]# kubectl get node
+NAME STATUS ROLES AGE VERSION
+master Ready control-plane,master 36d v1.23.1
+node-1 Ready 36d v1.23.1
+node-2 Ready 36d v1.23.1
+node-3 Ready 36d v1.23.1
+```
+
+#### 2.harbor仓库正常
+
+
+
+## 二:Prometheus部署
+
+#### 1.node-exporter部署
+
+ node-exporter可以采集机器(物理机、虚拟机、云主机等)的监控指标数据,能够采集到的指标包括CPU, 内存,磁盘,网络,文件数等信息
+
+创建监控namespace:
+
+```shell
+[root@master ~]# kubectl create ns monitor-sa
+```
+
+创建node-export.yaml:
+
+```shell
+[root@master ~]# vim node-export.yaml
+apiVersion: apps/v1
+kind: DaemonSet # 可以保证k8s集群的每个节点都运行完全一样的pod
+metadata:
+ name: node-exporter
+ namespace: monitor-sa
+ labels:
+ name: node-exporter
+spec:
+ selector:
+ matchLabels:
+ name: node-exporter
+ template:
+ metadata:
+ labels:
+ name: node-exporter
+ spec:
+ hostPID: true
+ hostIPC: true
+ hostNetwork: true
+ containers:
+ - name: node-exporter
+ image: prom/node-exporter:v0.16.0
+ #image: 10.0.0.230/xingdian/node-exporter:v0.16.0
+ ports:
+ - containerPort: 9100
+ resources:
+ requests:
+ cpu: 0.15 # 这个容器运行至少需要0.15核cpu
+ securityContext:
+ privileged: true # 开启特权模式
+ args:
+ - --path.procfs
+ - /host/proc
+ - --path.sysfs
+ - /host/sys
+ - --collector.filesystem.ignored-mount-points
+ - '"^/(sys|proc|dev|host|etc)($|/)"'
+ volumeMounts:
+ - name: dev
+ mountPath: /host/dev
+ - name: proc
+ mountPath: /host/proc
+ - name: sys
+ mountPath: /host/sys
+ - name: rootfs
+ mountPath: /rootfs
+ tolerations:
+ - key: "node-role.kubernetes.io/master"
+ operator: "Exists"
+ effect: "NoSchedule"
+ volumes:
+ - name: proc
+ hostPath:
+ path: /proc
+ - name: dev
+ hostPath:
+ path: /dev
+ - name: sys
+ hostPath:
+ path: /sys
+ - name: rootfs
+ hostPath:
+ path: /
+```
+
+注意:
+
+ hostNetwork、hostIPC、hostPID都为True时,表示这个Pod里的所有容器,会直接使用宿主机的网络,直接与宿主机进行IPC(进程间通信)通信,可以看到宿主机里正在运行的所有进程。加入了hostNetwork:true会直接将我们的宿主机的9100端口映射出来,从而不需要创建service 在我们的宿主机上就会有一个9100的端口
+
+创建:
+
+```shell
+[root@master ~]# kubectl apply -f node-export.yaml
+```
+
+查看node-exporter是否部署成功:
+
+```shell
+[root@master ~]# kubectl get pods -n monitor-sa -o wide
+NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
+node-exporter-2cbrg 1/1 Running 0 34m 10.0.0.220 master
+node-exporter-7rrbh 1/1 Running 0 34m 10.0.0.222 node-2
+node-exporter-96v29 1/1 Running 0 34m 10.0.0.221 node-1
+node-exporter-bf2j8 1/1 Running 0 34m 10.0.0.223 node-3
+```
+
+注意:
+
+ node-export默认的监听端口是9100,可以看到当前主机获取到的所有监控数据
+
+```shell
+[root@master ~]# curl http://10.0.0.220:9100/metrics | grep node_cpu_seconds
+ % Total % Received % Xferd Average Speed Time Time Time Current
+ Dload Upload Total Spent Left Speed
+ 0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0# HELP node_cpu_seconds_total Seconds the cpus spent in each mode.
+# TYPE node_cpu_seconds_total counter
+node_cpu_seconds_total{cpu="0",mode="idle"} 8398.49
+node_cpu_seconds_total{cpu="0",mode="iowait"} 1.54
+node_cpu_seconds_total{cpu="0",mode="irq"} 0
+node_cpu_seconds_total{cpu="0",mode="nice"} 0
+node_cpu_seconds_total{cpu="0",mode="softirq"} 17.2
+node_cpu_seconds_total{cpu="0",mode="steal"} 0
+node_cpu_seconds_total{cpu="0",mode="system"} 70.61
+node_cpu_seconds_total{cpu="0",mode="user"} 187.04
+node_cpu_seconds_total{cpu="1",mode="idle"} 8403.82
+node_cpu_seconds_total{cpu="1",mode="iowait"} 4.95
+node_cpu_seconds_total{cpu="1",mode="irq"} 0
+node_cpu_seconds_total{cpu="1",mode="nice"} 0
+node_cpu_seconds_total{cpu="1",mode="softirq"} 16.75
+node_cpu_seconds_total{cpu="1",mode="steal"} 0
+node_cpu_seconds_total{cpu="1",mode="system"} 71.26
+node_cpu_seconds_total{cpu="1",mode="user"} 190.27
+100 74016 100 74016 0 0 5878k 0 --:--:-- --:--:-- --:--:-- 6023k
+
+[root@master ~]# curl http://10.0.0.220:9100/metrics | grep node_load
+ % Total % Received % Xferd Average Speed Time Time Time Current
+ Dload Upload Total Spent Left Speed
+ 0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0# HELP node_loa
+1 1m load average.
+# TYPE node_load1 gauge
+node_load1 0.2
+# HELP node_load15 15m load average.
+# TYPE node_load15 gauge
+node_load15 0.22
+# HELP node_load5 5m load average.
+# TYPE node_load5 gauge
+node_load5 0.2
+100 74044 100 74044 0 0 8604k 0 --:--:-- --:--:-- --:--:-- 9038k
+```
+
+#### 2.Prometheus安装
+
+创建sa账号,对sa做rbac授权:
+
+```shell
+# 创建一个sa账号monitor
+[root@master ~]# kubectl create serviceaccount monitor -n monitor-sa
+
+# 把sa账号monitor通过clusterrolebing绑定到clusterrole上
+[root@master ~]# kubectl create clusterrolebinding monitor-clusterrolebinding -n monitor-sa --clusterrole=cluster-admin --serviceaccount=monitor-sa:monitor
+```
+
+创建prometheus数据存储目录:
+
+```shell
+# 将prometheus调度到node-1节点
+[root@node-1 ~]# mkdir /data && chmod 777 /data
+```
+
+创建一个configmap存储卷,用来存放prometheus配置信息:
+
+```shell
+[root@master ~]# vim prometheus-cfg.yaml
+---
+kind: ConfigMap
+apiVersion: v1
+metadata:
+ labels:
+ app: prometheus
+ name: prometheus-config
+ namespace: monitor-sa
+data:
+ prometheus.yml: |
+ global:
+ scrape_interval: 15s
+ scrape_timeout: 10s
+ evaluation_interval: 1m
+ scrape_configs:
+ - job_name: 'kubernetes-node'
+ kubernetes_sd_configs:
+ - role: node
+ relabel_configs:
+ - source_labels: [__address__]
+ regex: '(.*):10250'
+ replacement: '${1}:9100'
+ target_label: __address__
+ action: replace
+ - action: labelmap
+ regex: __meta_kubernetes_node_label_(.+)
+ - job_name: 'kubernetes-node-cadvisor'
+ kubernetes_sd_configs:
+ - role: node
+ scheme: https
+ tls_config:
+ ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
+ bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
+ relabel_configs:
+ - action: labelmap
+ regex: __meta_kubernetes_node_label_(.+)
+ - target_label: __address__
+ replacement: kubernetes.default.svc:443
+ - source_labels: [__meta_kubernetes_node_name]
+ regex: (.+)
+ target_label: __metrics_path__
+ replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
+ - job_name: 'kubernetes-apiserver'
+ kubernetes_sd_configs:
+ - role: endpoints
+ scheme: https
+ tls_config:
+ ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
+ bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
+ relabel_configs:
+ - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
+ action: keep
+ regex: default;kubernetes;https
+ - job_name: 'kubernetes-service-endpoints'
+ kubernetes_sd_configs:
+ - role: endpoints
+ relabel_configs:
+ - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
+ action: keep
+ regex: true
+ - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
+ action: replace
+ target_label: __scheme__
+ regex: (https?)
+ - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
+ action: replace
+ target_label: __metrics_path__
+ regex: (.+)
+ - source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
+ action: replace
+ target_label: __address__
+ regex: ([^:]+)(?::\d+)?;(\d+)
+ replacement: $1:$2
+ - action: labelmap
+ regex: __meta_kubernetes_service_label_(.+)
+ - source_labels: [__meta_kubernetes_namespace]
+ action: replace
+ target_label: kubernetes_namespace
+ - source_labels: [__meta_kubernetes_service_name]
+ action: replace
+ target_label: kubernetes_name
+```
+
+创建:
+
+```shell
+[root@master ~]# kubectl apply -f prometheus-cfg.yaml
+configmap/prometheus-config created
+```
+
+配置详解:
+
+```shell
+---
+kind: ConfigMap
+apiVersion: v1
+metadata:
+ labels:
+ app: prometheus
+ name: prometheus-config
+ namespace: monitor-sa
+data:
+ prometheus.yml: |
+ global:
+ scrape_interval: 15s #采集目标主机监控据的时间间隔
+ scrape_timeout: 10s # 数据采集超时时间,默认10s
+ evaluation_interval: 1m #触发告警检测的时间,默认是1m
+ scrape_configs: # 配置数据源,称为target,每个target用job_name命名。又分为静态配置和服务发现
+ - job_name: 'kubernetes-node'
+ kubernetes_sd_configs: # 使用的是k8s的服务发现
+ - role: node # 使用node角色,它使用默认的kubelet提供的http端口来发现集群中每个node节点
+ relabel_configs: # 重新标记
+ - source_labels: [__address__] # 配置的原始标签,匹配地址
+ regex: '(.*):10250' #匹配带有10250端口的url
+ replacement: '${1}:9100' #把匹配到的ip:10250的ip保留
+ target_label: __address__ #新生成的url是${1}获取到的ip:9100
+ action: replace # 动作替换
+ - action: labelmap
+ regex: __meta_kubernetes_node_label_(.+) #匹配到下面正则表达式的标签会被保留,如果不做regex正则的话,默认只是会显示instance标签
+ - job_name: 'kubernetes-node-cadvisor' # 抓取cAdvisor数据,是获取kubelet上/metrics/cadvisor接口数据来获取容器的资源使用情况
+ kubernetes_sd_configs:
+ - role: node
+ scheme: https
+ tls_config:
+ ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
+ bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
+ relabel_configs:
+ - action: labelmap # 把匹配到的标签保留
+ regex: __meta_kubernetes_node_label_(.+) #保留匹配到的具有__meta_kubernetes_node_label的标签
+ - target_label: __address__ # 获取到的地址:__address__="192.168.40.180:10250"
+ replacement: kubernetes.default.svc:443 # 把获取到的地址替换成新的地址kubernetes.default.svc:443
+ - source_labels: [__meta_kubernetes_node_name]
+ regex: (.+) # 把原始标签中__meta_kubernetes_node_name值匹配到
+ target_label: __metrics_path__ #获取__metrics_path__对应的值
+ replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
+ # 把metrics替换成新的值api/v1/nodes/k8s-master1/proxy/metrics/cadvisor
+ # ${1}是__meta_kubernetes_node_name获取到的值
+ # 新的url就是https://kubernetes.default.svc:443/api/v1/nodes/k8s-master1/proxy/metrics/cadvisor
+ - job_name: 'kubernetes-apiserver'
+ kubernetes_sd_configs:
+ - role: endpoints # 使用k8s中的endpoint服务发现,采集apiserver 6443端口获取到的数据
+ scheme: https
+ tls_config:
+ ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
+ bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
+ relabel_configs:
+ - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
+ # endpoint这个对象的名称空间,endpoint对象的服务名,exnpoint的端口名称
+ action: keep # 采集满足条件的实例,其他实例不采集
+ regex: default;kubernetes;https #正则匹配到的默认空间下的service名字是kubernetes,协议是https的endpoint类型保留下来
+ - job_name: 'kubernetes-service-endpoints'
+ kubernetes_sd_configs:
+ - role: endpoints
+ relabel_configs:
+ - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
+ action: keep
+ regex: true
+ # 重新打标仅抓取到的具有 "prometheus.io/scrape: true" 的annotation的端点,意思是说如果某个service具有prometheus.io/scrape = true annotation声明则抓取,annotation本身也是键值结构,所以这里的源标签设置为键,而regex设置值true,当值匹配到regex设定的内容时则执行keep动作也就是保留,其余则丢弃。
+ - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
+ action: replace
+ target_label: __scheme__
+ regex: (https?)
+ # 重新设置scheme,匹配源标签__meta_kubernetes_service_annotation_prometheus_io_scheme也就是prometheus.io/scheme annotation,如果源标签的值匹配到regex,则把值替换为__scheme__对应的值。
+ - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
+ action: replace
+ target_label: __metrics_path__
+ regex: (.+)
+ # 应用中自定义暴露的指标,也许你暴露的API接口不是/metrics这个路径,那么你可以在这个POD对应的service中做一个"prometheus.io/path = /mymetrics" 声明,上面的意思就是把你声明的这个路径赋值给__metrics_path__,其实就是让prometheus来获取自定义应用暴露的metrices的具体路径,不过这里写的要和service中做好约定,如果service中这样写 prometheus.io/app-metrics-path: '/metrics' 那么你这里就要__meta_kubernetes_service_annotation_prometheus_io_app_metrics_path这样写。
+ - source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
+ action: replace
+ target_label: __address__
+ regex: ([^:]+)(?::\d+)?;(\d+)
+ replacement: $1:$2
+ # 暴露自定义的应用的端口,就是把地址和你在service中定义的 "prometheus.io/port = " 声明做一个拼接,然后赋值给__address__,这样prometheus就能获取自定义应用的端口,然后通过这个端口再结合__metrics_path__来获取指标,如果__metrics_path__值不是默认的/metrics那么就要使用上面的标签替换来获取真正暴露的具体路径。
+ - action: labelmap #保留下面匹配到的标签
+ regex: __meta_kubernetes_service_label_(.+)
+ - source_labels: [__meta_kubernetes_namespace]
+ action: replace # 替换__meta_kubernetes_namespace变成kubernetes_namespace
+ target_label: kubernetes_namespace
+ - source_labels: [__meta_kubernetes_service_name]
+ action: replace
+ target_label: kubernetes_name
+```
+
+通过deployment部署prometheus:
+
+```shell
+[root@master ~]# cat prometheus-deploy.yaml
+---
+apiVersion: apps/v1
+kind: Deployment
+metadata:
+ name: prometheus-server
+ namespace: monitor-sa
+ labels:
+ app: prometheus
+spec:
+ replicas: 1
+ selector:
+ matchLabels:
+ app: prometheus
+ component: server
+ #matchExpressions:
+ #- {key: app, operator: In, values: [prometheus]}
+ #- {key: component, operator: In, values: [server]}
+ template:
+ metadata:
+ labels:
+ app: prometheus
+ component: server
+ annotations:
+ prometheus.io/scrape: 'false'
+ spec:
+ nodeName: node-1 # 指定pod调度到哪个节点上
+ serviceAccountName: monitor
+ containers:
+ - name: prometheus
+ image: prom/prometheus:v2.2.1
+ #image: 10.0.0.230/xingdian/prometheus:v2.2.1
+ imagePullPolicy: IfNotPresent
+ command:
+ - prometheus
+ - --config.file=/etc/prometheus/prometheus.yml
+ - --storage.tsdb.path=/prometheus # 数据存储目录
+ - --storage.tsdb.retention=720h # 数据保存时长
+ - --web.enable-lifecycle # 开启热加载
+ ports:
+ - containerPort: 9090
+ protocol: TCP
+ volumeMounts:
+ - mountPath: /etc/prometheus/prometheus.yml
+ name: prometheus-config
+ subPath: prometheus.yml
+ - mountPath: /prometheus/
+ name: prometheus-storage-volume
+ volumes:
+ - name: prometheus-config
+ configMap:
+ name: prometheus-config
+ items:
+ - key: prometheus.yml
+ path: prometheus.yml
+ mode: 0644
+ - name: prometheus-storage-volume
+ hostPath:
+ path: /data
+ type: Directory
+```
+
+创建:
+
+```shell
+[root@master ~]# kubectl apply -f prometheus-deploy.yaml
+deployment.apps/prometheus-server created
+```
+
+查看:
+
+```shell
+[root@master ~]# kubectl get pods -o wide -n monitor-sa
+NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
+prometheus-server-59cb5d648-bxwrb 1/1 Running 0 14m 10.244.2.100 node-1
+```
+
+#### 3.prometheus pod创建service
+
+```shell
+[root@master ~]# cat prometheus-svc.yaml
+apiVersion: v1
+kind: Service
+metadata:
+ name: prometheus
+ namespace: monitor-sa
+ labels:
+ app: prometheus
+spec:
+ type: NodePort
+ ports:
+ - port: 9090
+ targetPort: 9090
+ protocol: TCP
+ selector:
+ app: prometheus
+ component: server
+```
+
+创建:
+
+```shell
+[root@master ~]# kubectl apply -f prometheus-svc.yaml
+service/prometheus created
+```
+
+查看service在物理机映射的端口:
+
+```shell
+[root@master ~]# kubectl get svc -n monitor-sa
+NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
+prometheus NodePort 10.106.61.80 9090:32169/TCP 32m
+```
+
+#### 4.web界面查看
+
+
+
+
+
+#### 5.Prometheus热加载
+
+```shell
+# 为了每次修改配置文件可以热加载prometheus,也就是不停止prometheus,就可以使配置生效,想要使配置生效可用如下热加载命令:
+[root@master ~]# kubectl get pods -n monitor-sa -o wide -l app=prometheus
+NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
+prometheus-server-689fb8cdbc-kcsw2 1/1 Running 0 5m39s 10.244.36.70 k8s-node1
+
+# 想要使配置生效可用如下命令热加载:
+[root@master ~]# curl -X POST http://10.244.36.70:9090/-/reload
+
+# 查看log
+[root@master ~]# kubectl logs -n monitor-sa prometheus-server-689fb8cdbc-kcsw2
+```
+
+注意:
+
+```shell
+# 热加载速度比较慢,可以暴力重启prometheus,如修改上面的prometheus-cfg.yaml文件之后,可执行如下强制删除:
+[root@master ~]# kubectl delete -f prometheus-cfg.yaml
+[root@master ~]# kubectl delete -f prometheus-deploy.yaml
+# 然后再通过apply更新:
+[root@master ~]# kubectl apply -f prometheus-cfg.yaml
+[root@master ~]# kubectl apply -f prometheus-deploy.yaml
+#注意:线上最好热加载,暴力删除可能造成监控数据的丢失
+```
+
+## 三:Grafana的部署
+
+#### 1.Grafana介绍
+
+Grafana是一个跨平台的开源的度量分析和可视化工具,可以将采集的数据可视化的展示,并及时通知给告警接收方
+
+它主要有以下六大特点:
+
+1)展示方式:快速灵活的客户端图表,面板插件有许多不同方式的可视化指标和日志,官方库中具有丰富的仪表盘插件,比如热图、折线图、图表等多种展示方式
+
+2)数据源:Graphite,InfluxDB,OpenTSDB,Prometheus,Elasticsearch,CloudWatch和KairosDB等
+
+3)通知提醒:以可视方式定义最重要指标的警报规则,Grafana将不断计算并发送通知,在数据达到阈值时通过Slack、PagerDuty等获得通知
+
+4)混合展示:在同一图表中混合使用不同的数据源,可以基于每个查询指定数据源,甚至自定义数据源
+
+5)注释:使用来自不同数据源的丰富事件注释图表,将鼠标悬停在事件上会显示完整的事件元数据和标记
+
+#### 2.Grafana安装
+
+```shell
+[root@master prome]# cat grafana.yaml
+apiVersion: apps/v1
+kind: Deployment
+metadata:
+ name: monitoring-grafana
+ namespace: kube-system
+spec:
+ replicas: 1
+ selector:
+ matchLabels:
+ task: monitoring
+ k8s-app: grafana
+ template:
+ metadata:
+ labels:
+ task: monitoring
+ k8s-app: grafana
+ spec:
+ containers:
+ - name: grafana
+ image: 10.0.0.230/xingdian/heapster-grafana-amd64:v5.0.4
+ #heleicool/heapster-grafana-amd64:v5.0.4
+ ports:
+ - containerPort: 3000
+ protocol: TCP
+ volumeMounts:
+ - mountPath: /etc/ssl/certs
+ name: ca-certificates
+ readOnly: true
+ - mountPath: /var
+ name: grafana-storage
+ env:
+ - name: INFLUXDB_HOST
+ value: monitoring-influxdb
+ - name: GF_SERVER_HTTP_PORT
+ value: "3000"
+ # The following env variables are required to make Grafana accessible via
+ # the kubernetes api-server proxy. On production clusters, we recommend
+ # removing these env variables, setup auth for grafana, and expose the grafana
+ # service using a LoadBalancer or a public IP.
+ - name: GF_AUTH_BASIC_ENABLED
+ value: "false"
+ - name: GF_AUTH_ANONYMOUS_ENABLED
+ value: "true"
+ - name: GF_AUTH_ANONYMOUS_ORG_ROLE
+ value: Admin
+ - name: GF_SERVER_ROOT_URL
+ # If you're only using the API Server proxy, set this value instead:
+ # value: /api/v1/namespaces/kube-system/services/monitoring-grafana/proxy
+ value: /
+ volumes:
+ - name: ca-certificates
+ hostPath:
+ path: /etc/ssl/certs
+ - name: grafana-storage
+ emptyDir: {}
+---
+apiVersion: v1
+kind: Service
+metadata:
+ labels:
+ # For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons)
+ # If you are NOT using this as an addon, you should comment out this line.
+ kubernetes.io/cluster-service: 'true'
+ kubernetes.io/name: monitoring-grafana
+ name: monitoring-grafana
+ namespace: kube-system
+spec:
+ # In a production setup, we recommend accessing Grafana through an external Loadbalancer
+ # or through a public IP.
+ # type: LoadBalancer
+ # You could also use NodePort to expose the service at a randomly-generated port
+ # type: NodePort
+ ports:
+ - port: 80
+ targetPort: 3000
+ selector:
+ k8s-app: grafana
+ type: NodePort
+```
+
+创建:
+
+```shell
+[root@master prome]# kubectl apply -f grafana.yaml
+deployment.apps/monitoring-grafana created
+service/monitoring-grafana created
+```
+
+查看:
+
+```shell
+[root@master prome]# kubectl get pods -n kube-system -l task=monitoring -o wide
+NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
+monitoring-grafana-7c5c6c7486-rbt62 1/1 Running 0 9s 10.244.1.83 node-3
+```
+
+```shell
+[root@master prome]# kubectl get svc -n kube-system | grep grafana
+monitoring-grafana NodePort 10.101.77.194 80:30919/TCP 76s
+```
+
+## 四:配置Grafana
+
+浏览器访问:
+
+
+
+添加数据源:
+
+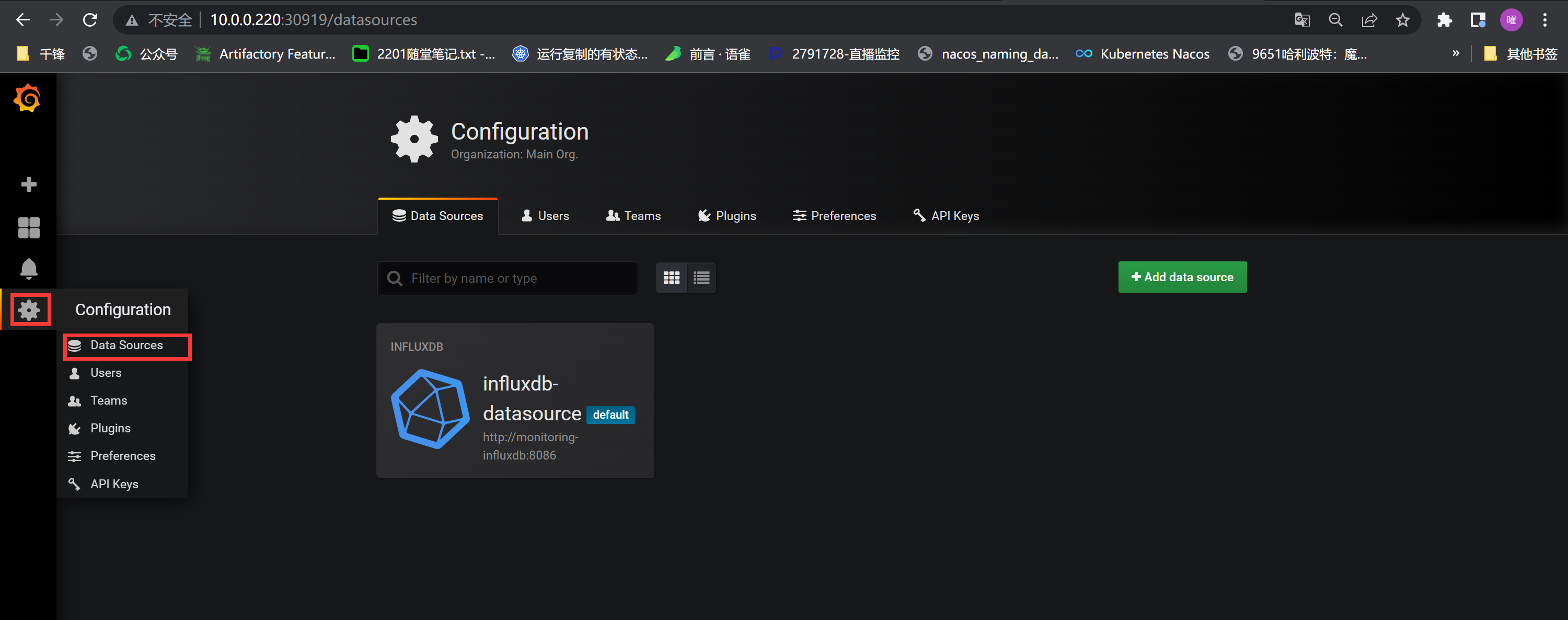
+
+指定Prometheus地址:
+
+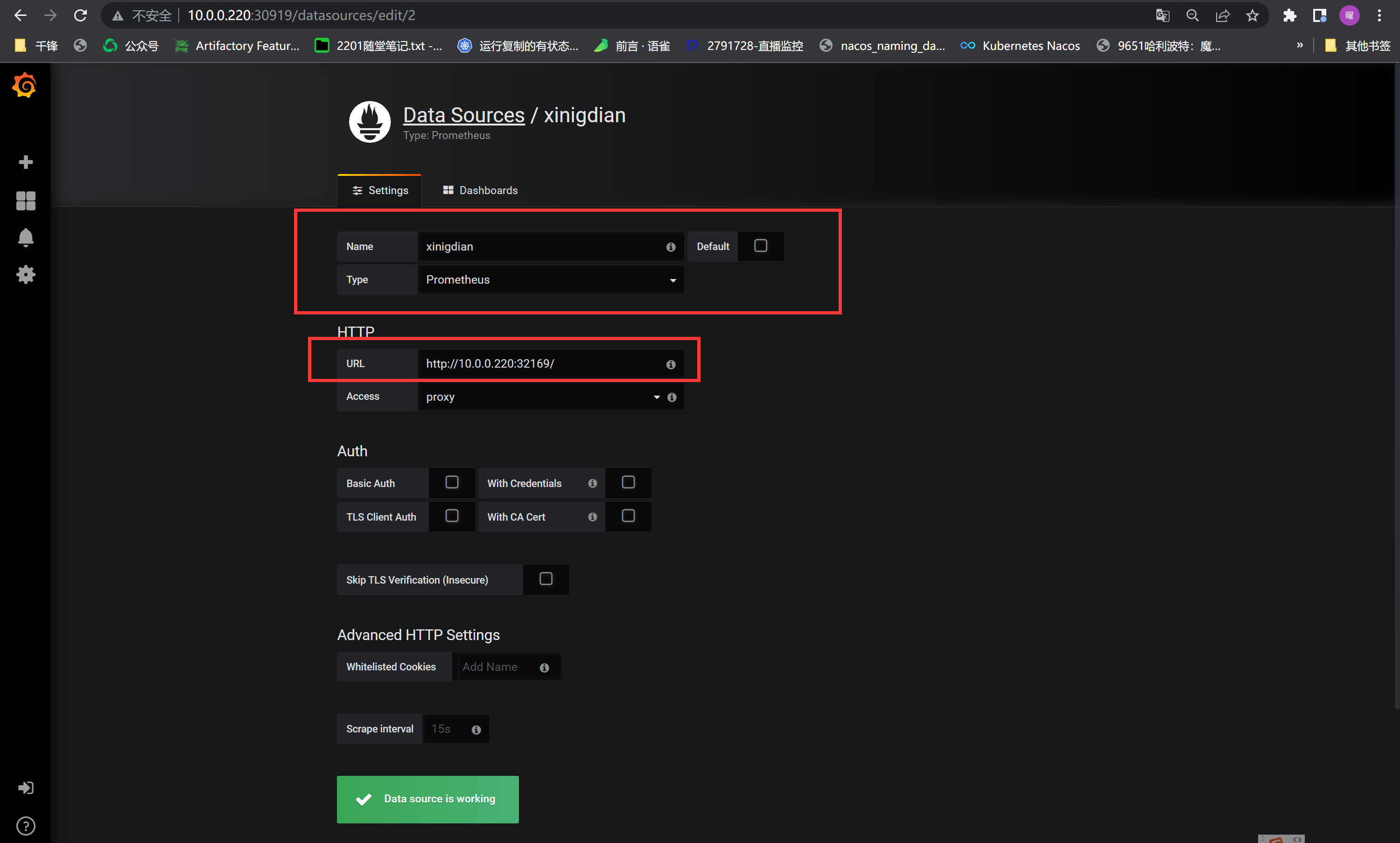
+
+导入监控模板:
+
+
+
+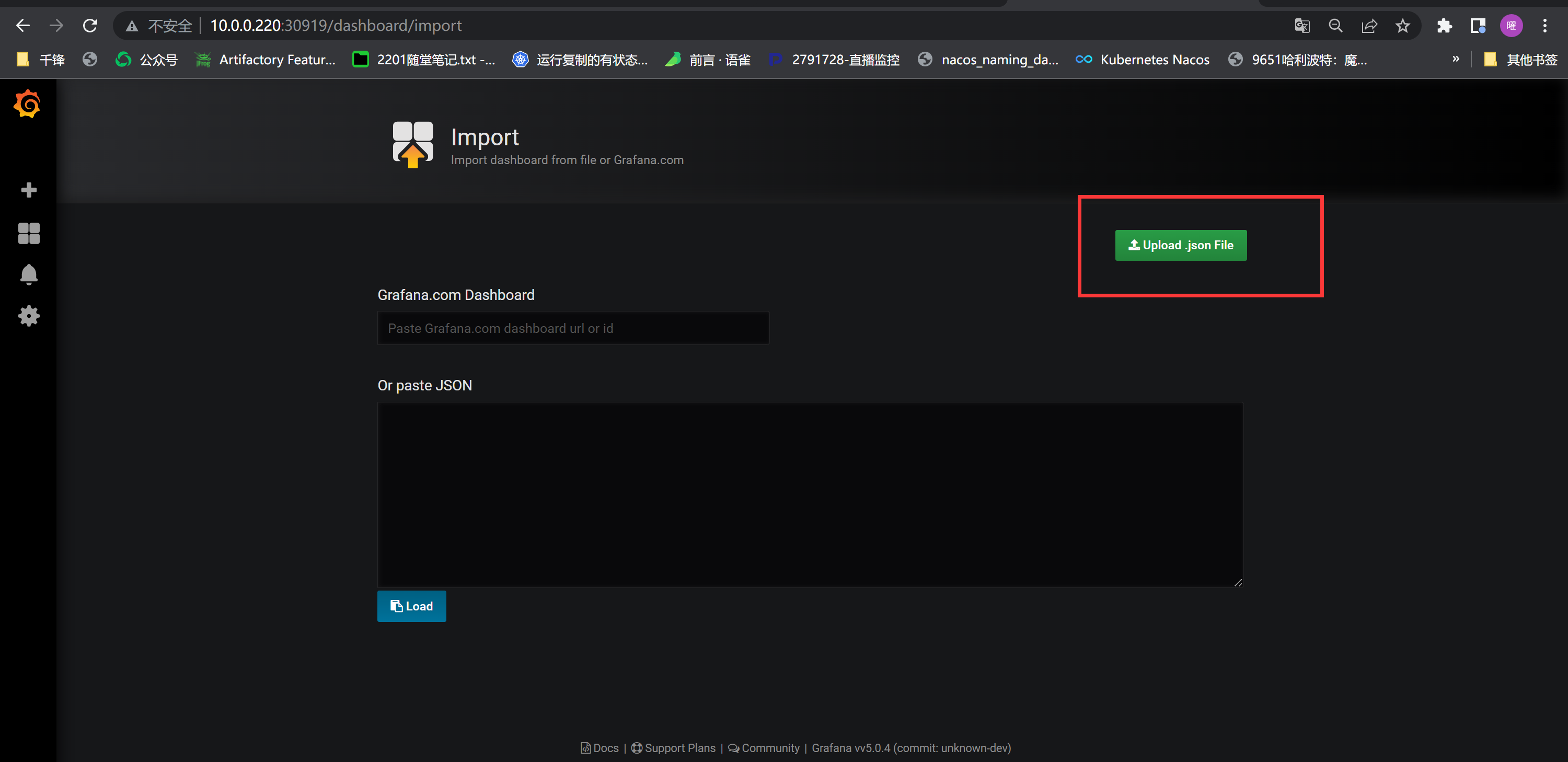
+
+注意:
+
+官方下载监控模板:https://grafana.com/dashboards?dataSource=prometheus&search=kubernetes
+
+
+
+
+
+展示:
+
+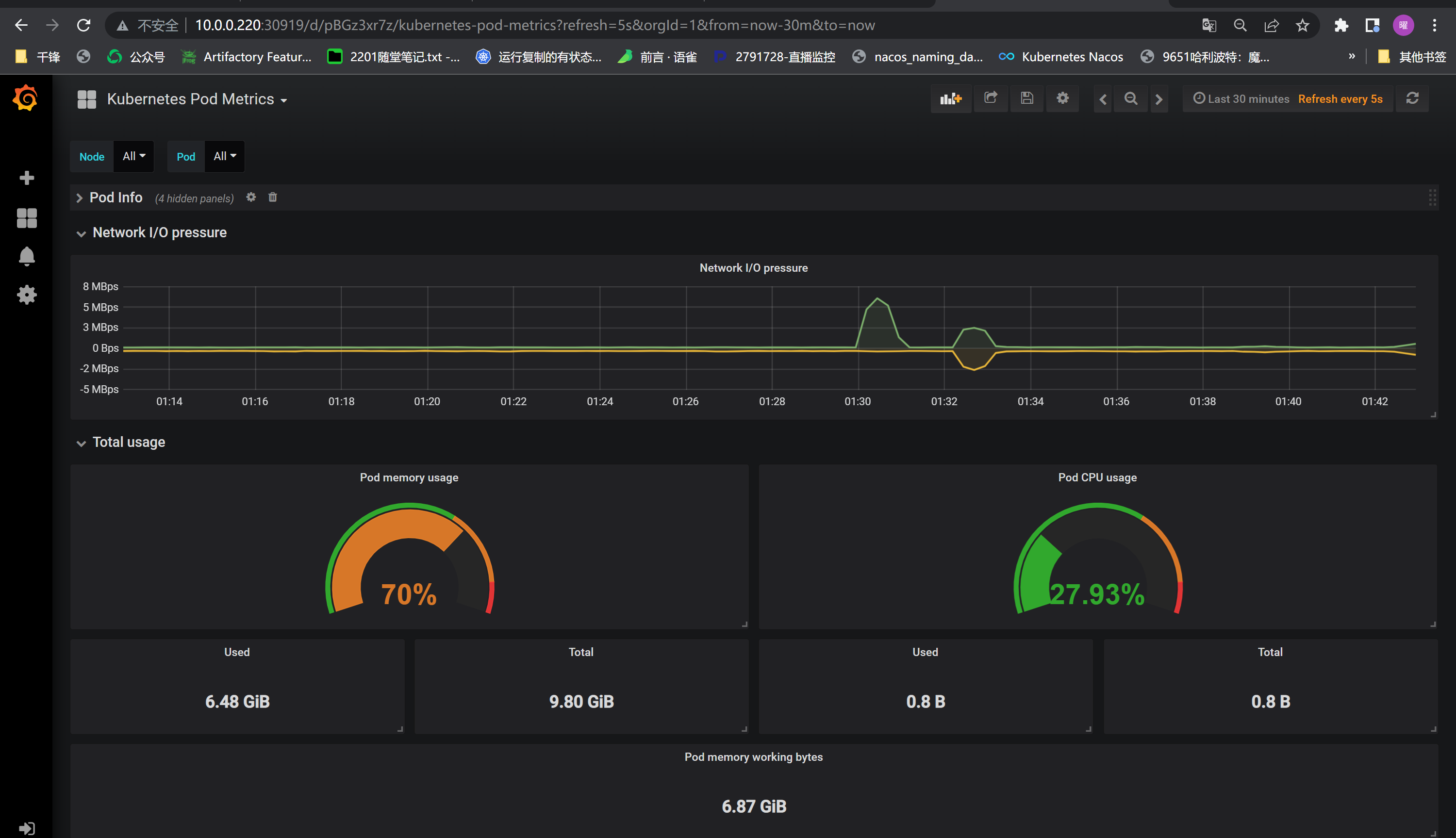
+
+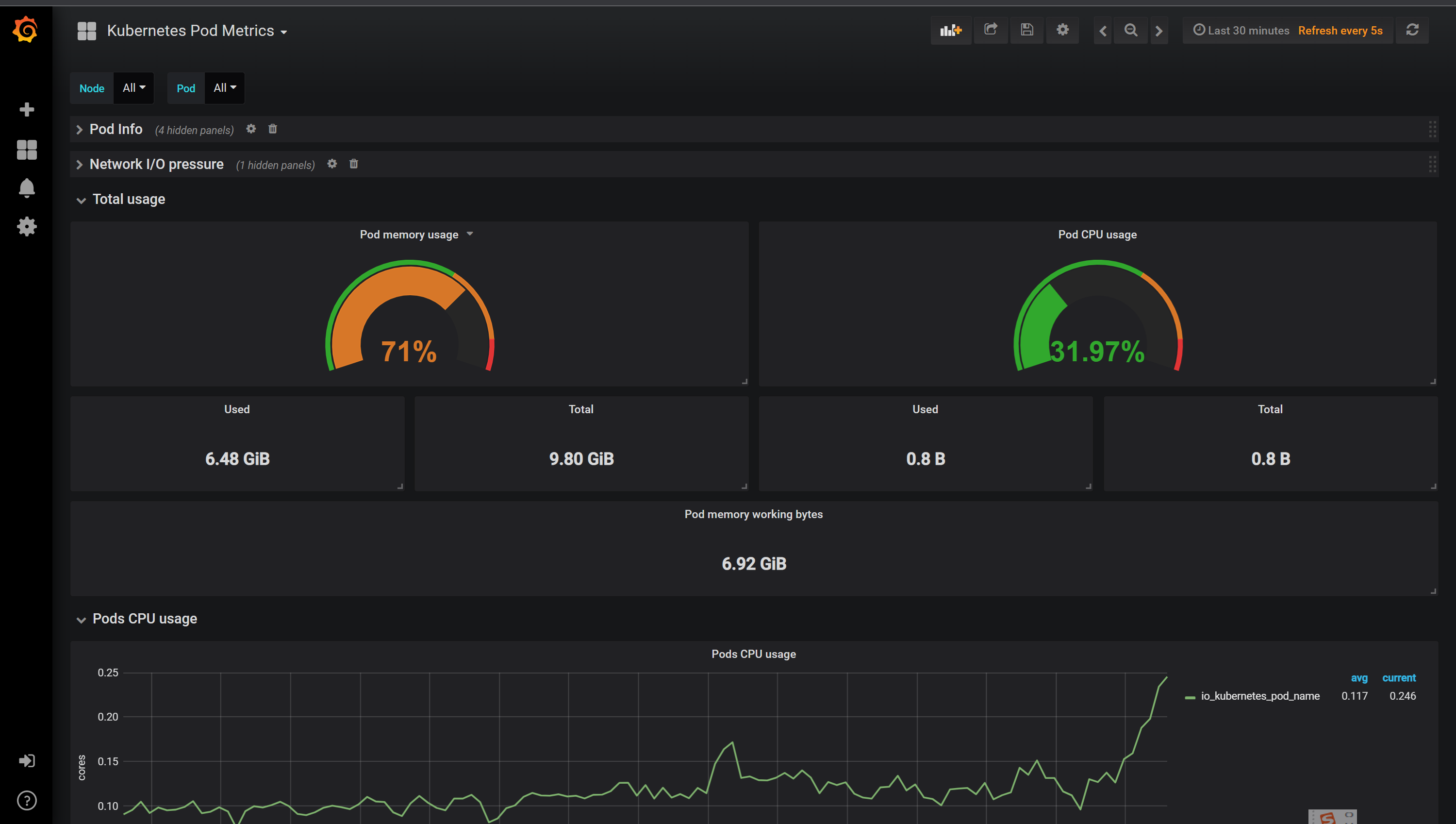
+
+
\ No newline at end of file