80 KiB
云原生监控-Prometheus
作者:行癫(盗版必究)
一:Prometheus基础
1.简介
Prometheus是一个开源系统监控和警报工具,是云原生基金会中的毕业项目
2.特点
具有由指标名称和键/值对标识的时间序列数据的多维数据模型
支持 PromQL,一种灵活的查询语言
不依赖分布式存储;单个服务器节点是自主的
3.指标
用通俗的话来说,指标就是数值测量;时间序列是指随时间变化的记录;用户想要测量的内容因应用程序而异;对于 Web 服务器,它可能是请求时间;对于数据库,它可能是活动连接数或活动查询数等等
指标在了解应用程序为何以某种方式运行方面起着重要作用;假设正在运行一个 Web 应用程序并发现它运行缓慢;要了解应用程序发生了什么,您需要一些信息;例如,当请求数很高时,应用程序可能会变慢;如果您有请求数指标,则可以确定原因并增加服务器数量以处理负载
4.数据模型
Prometheus 从根本上将所有数据存储为时间序列:属于同一指标和同一组标记维度的带时间戳的值流
每个时间序列都由其指标名称和可选的键值对(称为标签)唯一标识
指标名称:
指定要测量的系统的一般特征(例如http_requests_total- 收到的 HTTP 请求总数)
指标名称可以包含 ASCII 字母、数字、下划线和冒号;它必须与正则表达式匹配
冒号是为用户定义的记录规则保留的;它们不能被直接使用
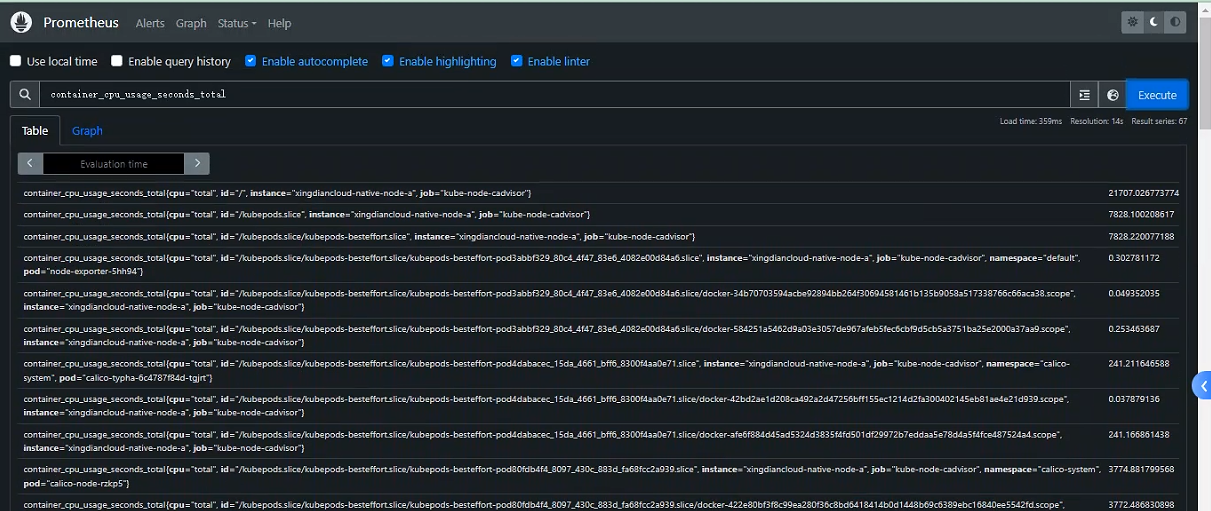
例如:具有指标名称api_http_requests_total和标签的时间序列method="POST"可以handler="/messages"写成这样
api_http_requests_total{method="POST", handler="/messages"}
二:Pormetheus部署
1.获取二进制安装包
2.解压安装
[root@prometheus ~]# tar xf prometheus-2.53.0.linux-amd64.tar.gz -C /usr/local/
[root@prometheus local]# mv prometheus-2.53.0.linux-amd64/ prometheus
3.配置
[root@prometheus prometheus]# cat prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
配置详解
配置块
global:global块控制 Prometheus 服务器的全局配置
rule_files:rule_files块指定了我们希望 Prometheus 服务器加载的任何规则
scrape_configs:scrape_configs控制 Prometheus 监控哪些资源
scrape_interval 控制 Prometheus 抓取目标的频率
evaluation_interval 控制 Prometheus 评估规则的频率
4.启动服务
[root@prometheus prometheus]# nohup ./prometheus --config.file=prometheus.yml &
5.访问测试
Table视图:路径+/graph
获得指标:路径+/metrics
6.调用案例
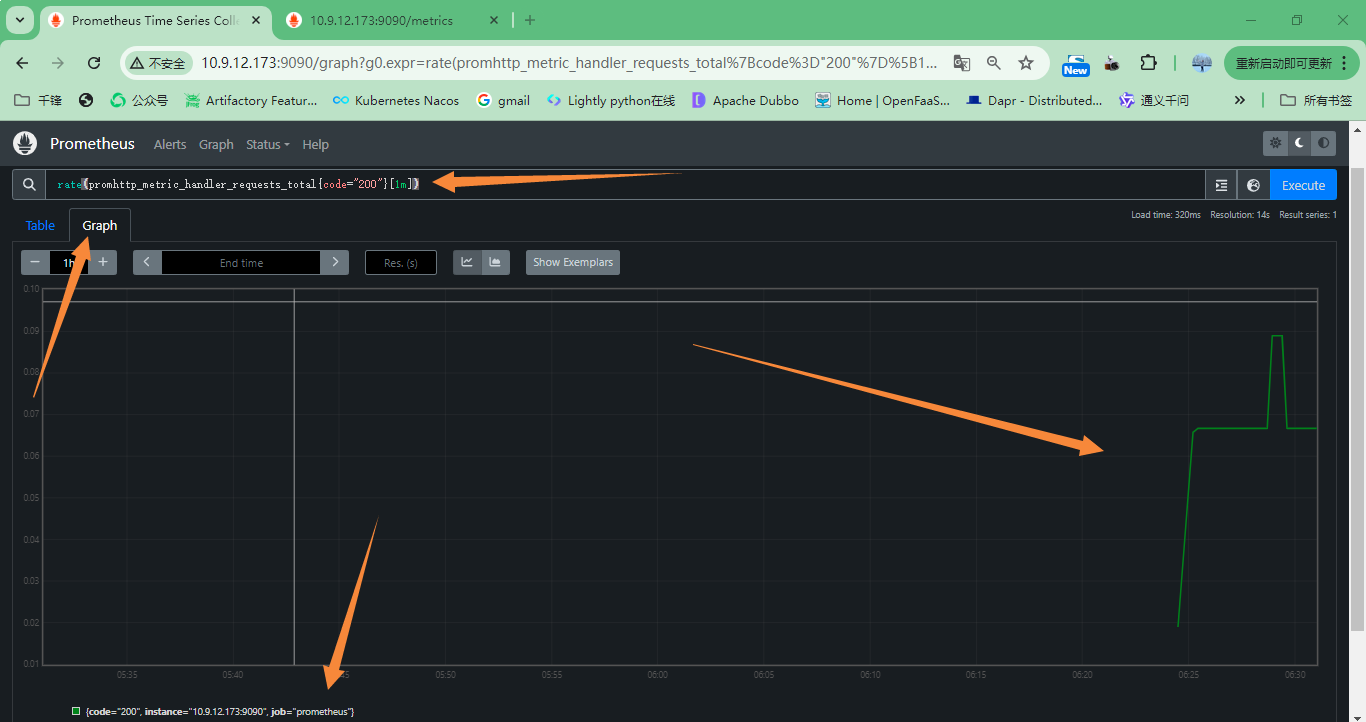
1.抓取的 Prometheus 中每秒返回状态代码 200 的 HTTP 请求率,参数图标如下:
rate(promhttp_metric_handler_requests_total{code="200"}[1m])
三:监控Kubernetes集群
1.创建命名空间
[root@xingdiancloud-native-master-a prometheus]# kubectl create namespace prometheus
2.Kubernetes创建服务账户
[root@xingdiancloud-native-master-a prometheus]# cat serviceaccount.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
namespace: prometheus
3.创建角色和角色绑定
[root@xingdiancloud-native-master-a prometheus]# cat role.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:
- apiGroups:
- ""
resources:
- nodes
- services
- endpoints
- pods
- nodes/proxy
verbs:
- get
- list
- watch
- apiGroups:
- "extensions"
resources:
- ingresses
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- configmaps
- nodes/metrics
verbs:
- get
- nonResourceURLs:
- /metrics
verbs:
- get
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: prometheus
namespace: prometheus
4.创建Secret
[root@xingdiancloud-native-master-a prometheus]# cat secret.yaml
apiVersion: v1
kind: Secret
metadata:
name: prometheus-token
namespace: prometheus
annotations:
kubernetes.io/service-account.name: prometheus
type: kubernetes.io/service-account-token
5.获取Token
[root@xingdiancloud-native-master-a prometheus]# kubectl -n prometheus describe secret prometheus-token
Name: prometheus-token
Namespace: prometheus
Labels: kubernetes.io/legacy-token-last-used=2024-07-01
Annotations: kubernetes.io/service-account.name: prometheus
kubernetes.io/service-account.uid: f0f6bda3-cd7a-4de4-982d-25c4e0810b84
Type: kubernetes.io/service-account-token
Data
====
ca.crt: 1310 bytes
namespace: 10 bytes
token: eyJhbGciOiJSUzI1NiIsImtpZCI6ImpzLWJHQXBELURyeUFXZU1Pb0NMYVFVRW40VHVrR3ZJaUR5VlNLajY1ZDAifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJwcm9tZXRoZXVzIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZWNyZXQubmFtZSI6InByb21ldGhldXMtdG9rZW4iLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoicHJvbWV0aGV1cyIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6ImYwZjZiZGEzLWNkN2EtNGRlNC05ODJkLTI1YzRlMDgxMGI4NCIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDpwcm9tZXRoZXVzOnByb21ldGhldXMifQ.g5QsgIfarQ4l5N_1-8j7oE9WJj5bHS27DSinLdGMBwTDjmHrKcrvH_DRnvm4VYQ4zDTNrauk0Yks1S4ZIEsrKv_Iob4VliVRoMCPw1l3BOBZe9T7oDc8sJAYk2fR-rIdYEfgwMtVrXuLHIs3tklTXimUD4_EnzoVBpFshXeXlpITDNMfkh2Uhc6C63cA9Cdt2Wxyjnb3Dz7P27H2pDO2AJ8A-q0JgVLpKNSKks4TaEBeAI6TSZpO1IJIia-OFJpeLJsLUK4xCOc5NIzeUp09O8kbDc0E1c0Jdx1sGQcsP-2Y5YXzeQ_vus0Z4MaqTxNARr95WTW1HfgILw0M5rijWg
6.安装采集器
[root@xingdiancloud-native-master-a prometheus]# cat node-exporte.yaml
kind: DaemonSet
apiVersion: apps/v1
metadata:
name: node-exporter
annotations:
prometheus.io/scrape: 'true'
spec:
selector:
matchLabels:
app: node-exporter
template:
metadata:
labels:
app: node-exporter
name: node-exporter
spec:
containers:
- image: quay.io/prometheus/node-exporter:latest
#- image: 10.9.12.201/prometheus/node-exporter:latest
name: node-exporter
ports:
- containerPort: 9100
hostPort: 9100
name: node-exporter
hostNetwork: true
hostPID: true
tolerations:
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule"
7.安装kube-state-metrics
官网地址:https://github.com/kubernetes/kube-state-metrics/tree/main/examples/standard
创建服务账户
[root@xingdiancloud-native-master-a metric]# cat service-account.yaml
apiVersion: v1
automountServiceAccountToken: false
kind: ServiceAccount
metadata:
labels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: 2.12.0
name: kube-state-metrics
namespace: kube-system
创建集群角色
[root@xingdiancloud-native-master-a metric]# cat cluster-role.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: 2.12.0
name: kube-state-metrics
rules:
- apiGroups:
- ""
resources:
- configmaps
- secrets
- nodes
- pods
- services
- serviceaccounts
- resourcequotas
- replicationcontrollers
- limitranges
- persistentvolumeclaims
- persistentvolumes
- namespaces
- endpoints
verbs:
- list
- watch
- apiGroups:
- apps
resources:
- statefulsets
- daemonsets
- deployments
- replicasets
verbs:
- list
- watch
- apiGroups:
- batch
resources:
- cronjobs
- jobs
verbs:
- list
- watch
- apiGroups:
- autoscaling
resources:
- horizontalpodautoscalers
verbs:
- list
- watch
- apiGroups:
- authentication.k8s.io
resources:
- tokenreviews
verbs:
- create
- apiGroups:
- authorization.k8s.io
resources:
- subjectaccessreviews
verbs:
- create
- apiGroups:
- policy
resources:
- poddisruptionbudgets
verbs:
- list
- watch
- apiGroups:
- certificates.k8s.io
resources:
- certificatesigningrequests
verbs:
- list
- watch
- apiGroups:
- discovery.k8s.io
resources:
- endpointslices
verbs:
- list
- watch
- apiGroups:
- storage.k8s.io
resources:
- storageclasses
- volumeattachments
verbs:
- list
- watch
- apiGroups:
- admissionregistration.k8s.io
resources:
- mutatingwebhookconfigurations
- validatingwebhookconfigurations
verbs:
- list
- watch
- apiGroups:
- networking.k8s.io
resources:
- networkpolicies
- ingressclasses
- ingresses
verbs:
- list
- watch
- apiGroups:
- coordination.k8s.io
resources:
- leases
verbs:
- list
- watch
- apiGroups:
- rbac.authorization.k8s.io
resources:
- clusterrolebindings
- clusterroles
- rolebindings
- roles
verbs:
- list
- watch
创建角色绑定
[root@xingdiancloud-native-master-a metric]# cat cluster-role-binding.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: 2.12.0
name: kube-state-metrics
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: kube-state-metrics
subjects:
- kind: ServiceAccount
name: kube-state-metrics
namespace: kube-system
创建kube-state-metrics
[root@xingdiancloud-native-master-a metric]# cat deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: 2.12.0
name: kube-state-metrics
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/name: kube-state-metrics
template:
metadata:
labels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: 2.12.0
spec:
automountServiceAccountToken: true
containers:
- image: registry.k8s.io/kube-state-metrics/kube-state-metrics:v2.12.0
#- image: 10.9.12.201/prometheus/kube-state-metrics:v2.12.0
livenessProbe:
httpGet:
path: /livez
port: 8080
initialDelaySeconds: 5
timeoutSeconds: 5
name: kube-state-metrics
ports:
- containerPort: 8080
name: http-metrics
- containerPort: 8081
name: telemetry
readinessProbe:
httpGet:
path: /metrics
port: 8081
initialDelaySeconds: 5
timeoutSeconds: 5
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop:
- ALL
readOnlyRootFilesystem: true
runAsNonRoot: true
runAsUser: 65534
seccompProfile:
type: RuntimeDefault
nodeSelector:
kubernetes.io/os: linux
serviceAccountName: kube-state-metrics
创建服务
[root@xingdiancloud-native-master-a metric]# cat service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: 2.12.0
name: kube-state-metrics
namespace: kube-system
spec:
clusterIP: None
ports:
- name: http-metrics
port: 8080
targetPort: http-metrics
- name: telemetry
port: 8081
targetPort: telemetry
selector:
app.kubernetes.io/name: kube-state-metrics
8.配置Prometheus
[root@prometheus prometheus]# cat prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
- job_name: 'xingdiancloud-kubernetes-nodes'
static_configs:
- targets: ['10.9.12.205:9100','10.9.12.204:9100','10.9.12.203:9100']
metrics_path: /metrics
scheme: http
honor_labels: true
- job_name: "kube-state-metrics"
scheme: https
tls_config:
insecure_skip_verify: true
bearer_token: 'eyJhbGciOiJSUzI1NiIsImtpZCI6ImpzLWJHQXBELURyeUFXZU1Pb0NMYVFVRW40VHVrR3ZJaUR5VlNLajY1ZDAifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJwcm9tZXRoZXVzIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZWNyZXQubmFtZSI6InByb21ldGhldXMtdG9rZW4iLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoicHJvbWV0aGV1cyIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6ImYwZjZiZGEzLWNkN2EtNGRlNC05ODJkLTI1YzRlMDgxMGI4NCIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDpwcm9tZXRoZXVzOnByb21ldGhldXMifQ.g5QsgIfarQ4l5N_1-8j7oE9WJj5bHS27DSinLdGMBwTDjmHrKcrvH_DRnvm4VYQ4zDTNrauk0Yks1S4ZIEsrKv_Iob4VliVRoMCPw1l3BOBZe9T7oDc8sJAYk2fR-rIdYEfgwMtVrXuLHIs3tklTXimUD4_EnzoVBpFshXeXlpITDNMfkh2Uhc6C63cA9Cdt2Wxyjnb3Dz7P27H2pDO2AJ8A-q0JgVLpKNSKks4TaEBeAI6TSZpO1IJIia-OFJpeLJsLUK4xCOc5NIzeUp09O8kbDc0E1c0Jdx1sGQcsP-2Y5YXzeQ_vus0Z4MaqTxNARr95WTW1HfgILw0M5rijWg'
kubernetes_sd_configs:
- role: endpoints
api_server: "https://10.9.12.100:6443"
tls_config:
insecure_skip_verify: true
bearer_token: 'eyJhbGciOiJSUzI1NiIsImtpZCI6ImpzLWJHQXBELURyeUFXZU1Pb0NMYVFVRW40VHVrR3ZJaUR5VlNLajY1ZDAifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJwcm9tZXRoZXVzIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZWNyZXQubmFtZSI6InByb21ldGhldXMtdG9rZW4iLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoicHJvbWV0aGV1cyIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6ImYwZjZiZGEzLWNkN2EtNGRlNC05ODJkLTI1YzRlMDgxMGI4NCIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDpwcm9tZXRoZXVzOnByb21ldGhldXMifQ.g5QsgIfarQ4l5N_1-8j7oE9WJj5bHS27DSinLdGMBwTDjmHrKcrvH_DRnvm4VYQ4zDTNrauk0Yks1S4ZIEsrKv_Iob4VliVRoMCPw1l3BOBZe9T7oDc8sJAYk2fR-rIdYEfgwMtVrXuLHIs3tklTXimUD4_EnzoVBpFshXeXlpITDNMfkh2Uhc6C63cA9Cdt2Wxyjnb3Dz7P27H2pDO2AJ8A-q0JgVLpKNSKks4TaEBeAI6TSZpO1IJIia-OFJpeLJsLUK4xCOc5NIzeUp09O8kbDc0E1c0Jdx1sGQcsP-2Y5YXzeQ_vus0Z4MaqTxNARr95WTW1HfgILw0M5rijWg'
relabel_configs:
- source_labels: [__meta_kubernetes_service_name]
action: keep
regex: '^(kube-state-metrics)$'
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__address__]
action: replace
target_label: instance
- target_label: __address__
replacement: 10.9.12.100:6443
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_pod_name, __meta_kubernetes_pod_container_port_number]
regex: ([^;]+);([^;]+);([^;]+)
target_label: __metrics_path__
replacement: /api/v1/namespaces/${1}/pods/http:${2}:${3}/proxy/metrics
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: service_name
- job_name: "kube-node-kubelet"
scheme: https
tls_config:
insecure_skip_verify: true
bearer_token: 'eyJhbGciOiJSUzI1NiIsImtpZCI6ImpzLWJHQXBELURyeUFXZU1Pb0NMYVFVRW40VHVrR3ZJaUR5VlNLajY1ZDAifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJwcm9tZXRoZXVzIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZWNyZXQubmFtZSI6InByb21ldGhldXMtdG9rZW4iLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoicHJvbWV0aGV1cyIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6ImYwZjZiZGEzLWNkN2EtNGRlNC05ODJkLTI1YzRlMDgxMGI4NCIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDpwcm9tZXRoZXVzOnByb21ldGhldXMifQ.g5QsgIfarQ4l5N_1-8j7oE9WJj5bHS27DSinLdGMBwTDjmHrKcrvH_DRnvm4VYQ4zDTNrauk0Yks1S4ZIEsrKv_Iob4VliVRoMCPw1l3BOBZe9T7oDc8sJAYk2fR-rIdYEfgwMtVrXuLHIs3tklTXimUD4_EnzoVBpFshXeXlpITDNMfkh2Uhc6C63cA9Cdt2Wxyjnb3Dz7P27H2pDO2AJ8A-q0JgVLpKNSKks4TaEBeAI6TSZpO1IJIia-OFJpeLJsLUK4xCOc5NIzeUp09O8kbDc0E1c0Jdx1sGQcsP-2Y5YXzeQ_vus0Z4MaqTxNARr95WTW1HfgILw0M5rijWg'
kubernetes_sd_configs:
- role: node
api_server: "https://10.9.12.100:6443"
tls_config:
insecure_skip_verify: true
bearer_token: 'eyJhbGciOiJSUzI1NiIsImtpZCI6ImpzLWJHQXBELURyeUFXZU1Pb0NMYVFVRW40VHVrR3ZJaUR5VlNLajY1ZDAifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJwcm9tZXRoZXVzIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZWNyZXQubmFtZSI6InByb21ldGhldXMtdG9rZW4iLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoicHJvbWV0aGV1cyIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6ImYwZjZiZGEzLWNkN2EtNGRlNC05ODJkLTI1YzRlMDgxMGI4NCIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDpwcm9tZXRoZXVzOnByb21ldGhldXMifQ.g5QsgIfarQ4l5N_1-8j7oE9WJj5bHS27DSinLdGMBwTDjmHrKcrvH_DRnvm4VYQ4zDTNrauk0Yks1S4ZIEsrKv_Iob4VliVRoMCPw1l3BOBZe9T7oDc8sJAYk2fR-rIdYEfgwMtVrXuLHIs3tklTXimUD4_EnzoVBpFshXeXlpITDNMfkh2Uhc6C63cA9Cdt2Wxyjnb3Dz7P27H2pDO2AJ8A-q0JgVLpKNSKks4TaEBeAI6TSZpO1IJIia-OFJpeLJsLUK4xCOc5NIzeUp09O8kbDc0E1c0Jdx1sGQcsP-2Y5YXzeQ_vus0Z4MaqTxNARr95WTW1HfgILw0M5rijWg'
relabel_configs:
- target_label: __address__
replacement: 10.9.12.100:6443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}:10250/proxy/metrics
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: service_name
- job_name: "kube-node-cadvisor"
scheme: https
tls_config:
insecure_skip_verify: true
bearer_token: 'eyJhbGciOiJSUzI1NiIsImtpZCI6ImpzLWJHQXBELURyeUFXZU1Pb0NMYVFVRW40VHVrR3ZJaUR5VlNLajY1ZDAifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJwcm9tZXRoZXVzIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZWNyZXQubmFtZSI6InByb21ldGhldXMtdG9rZW4iLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoicHJvbWV0aGV1cyIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6ImYwZjZiZGEzLWNkN2EtNGRlNC05ODJkLTI1YzRlMDgxMGI4NCIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDpwcm9tZXRoZXVzOnByb21ldGhldXMifQ.g5QsgIfarQ4l5N_1-8j7oE9WJj5bHS27DSinLdGMBwTDjmHrKcrvH_DRnvm4VYQ4zDTNrauk0Yks1S4ZIEsrKv_Iob4VliVRoMCPw1l3BOBZe9T7oDc8sJAYk2fR-rIdYEfgwMtVrXuLHIs3tklTXimUD4_EnzoVBpFshXeXlpITDNMfkh2Uhc6C63cA9Cdt2Wxyjnb3Dz7P27H2pDO2AJ8A-q0JgVLpKNSKks4TaEBeAI6TSZpO1IJIia-OFJpeLJsLUK4xCOc5NIzeUp09O8kbDc0E1c0Jdx1sGQcsP-2Y5YXzeQ_vus0Z4MaqTxNARr95WTW1HfgILw0M5rijWg'
kubernetes_sd_configs:
- role: node
api_server: "https://10.9.12.100:6443"
tls_config:
insecure_skip_verify: true
bearer_token: 'eyJhbGciOiJSUzI1NiIsImtpZCI6ImpzLWJHQXBELURyeUFXZU1Pb0NMYVFVRW40VHVrR3ZJaUR5VlNLajY1ZDAifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJwcm9tZXRoZXVzIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZWNyZXQubmFtZSI6InByb21ldGhldXMtdG9rZW4iLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoicHJvbWV0aGV1cyIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6ImYwZjZiZGEzLWNkN2EtNGRlNC05ODJkLTI1YzRlMDgxMGI4NCIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDpwcm9tZXRoZXVzOnByb21ldGhldXMifQ.g5QsgIfarQ4l5N_1-8j7oE9WJj5bHS27DSinLdGMBwTDjmHrKcrvH_DRnvm4VYQ4zDTNrauk0Yks1S4ZIEsrKv_Iob4VliVRoMCPw1l3BOBZe9T7oDc8sJAYk2fR-rIdYEfgwMtVrXuLHIs3tklTXimUD4_EnzoVBpFshXeXlpITDNMfkh2Uhc6C63cA9Cdt2Wxyjnb3Dz7P27H2pDO2AJ8A-q0JgVLpKNSKks4TaEBeAI6TSZpO1IJIia-OFJpeLJsLUK4xCOc5NIzeUp09O8kbDc0E1c0Jdx1sGQcsP-2Y5YXzeQ_vus0Z4MaqTxNARr95WTW1HfgILw0M5rijWg'
relabel_configs:
- target_label: __address__
replacement: 10.9.12.100:6443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}:10250/proxy/metrics/cadvisor
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: service_name
static_configs:
- targets: ["10.9.12.173:9090"]
9.启动Prometheus
[root@prometheus prometheus]# nohup ./prometheus --config.file=prometheus.yml &
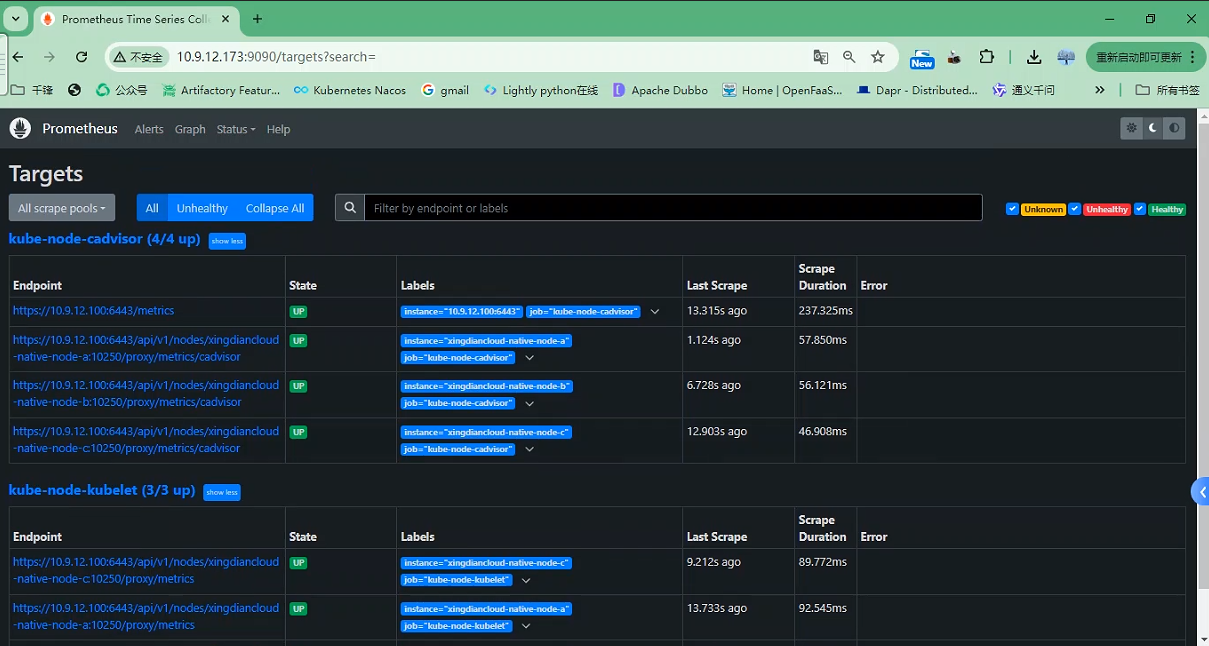
10.浏览器访问验证
11.参数解释
scrape_configs:
- job_name: "prometheus"
# 默认的 `metrics_path` 是 `/metrics`
# 默认的 `scheme` 是 `http`
job_name: 用于标识该作业的名称,并作为标签 job=<job_name> 添加到从该配置抓取的任何时间序列。
metrics_path: 定义 Prometheus 将要抓取的路径,默认为 /metrics。
scheme: 定义抓取时使用的协议,默认为 http。我们使用https
kube-state-metrics 配置
scheme: 使用 https 协议。
tls_config: 配置 TLS,insecure_skip_verify: true 意味着忽略证书验证。
bearer_token: 使用 Bearer Token 进行认证。
kubernetes_sd_configs: 使用 Kubernetes 服务发现配置。
role: endpoints: 指定角色为 endpoints,表示抓取 Kubernetes 服务的端点信息。
api_server: Kubernetes API 服务器的地址。
relabel_configs: 重新标签配置,用于动态生成指标标签。
source_labels: [__meta_kubernetes_service_name]: 仅保留 kube-state-metrics 服务。
source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]: 仅保留被标记为 true 的服务。
source_labels: [address]: 将原地址替换为 instance 标签。
target_label: address: 将所有地址替换为 10.9.12.100:6443。
source_labels: 将命名空间、pod 名称和端口号组合成新的 metrics_path。
labelmap: 将所有 Kubernetes 服务标签映射到 Prometheus 标签。
source_labels: [__meta_kubernetes_namespace]: 替换命名空间标签。
source_labels: [__meta_kubernetes_service_name]: 替换服务名称标签。
kube-node-kubelet 配置
role: node: 指定角色为 node,表示抓取节点信息。
relabel_configs: 重新标签配置。
target_label: address: 将所有地址替换为 10.9.12.100:6443。
source_labels: [__meta_kubernetes_node_name]: 使用节点名称构造新的 metrics_path。
kube-node-cadvisor 配置
role: node: 指定角色为 node,表示抓取节点信息。
relabel_configs: 重新标签配置。
target_label: address: 将所有地址替换为 10.9.12.100:6443。
source_labels: [__meta_kubernetes_node_name]: 使用节点名称构造新的 metrics_path。
static_configs: 定义静态配置目标。
targets: 定义静态目标地址。
通过以上配置,Prometheus 将能够正确地抓取 Kubernetes 集群中的各类指标数据。你需要根据实际情况更新 bearer_token 和 api_server 地址。
四:Grafana展示分析
1.Grafana简介
Grafana 是一个广泛使用的开源数据可视化和监控工具
版本
Grafana OSS
Grafana Enterprise
Grafana OSS (Open Source Software)
Grafana OSS 是 Grafana 的开源版本,免费提供,并且包含了大多数用户所需的基本功能
数据源支持:支持多种数据源,包括 Prometheus、Graphite、Elasticsearch、MySQL、PostgreSQL 等
仪表盘和可视化:提供丰富的可视化组件,可以创建各种图表、仪表盘和告警
插件生态系统:支持社区和官方开发的插件,可以扩展 Grafana 的功能
用户管理:提供基本的用户和组织管理功能
告警:支持基本的告警功能,可以通过电子邮件、Slack 等方式发送告警通知
Grafana Enterprise
Grafana Enterprise 是 Grafana 的商业版本,基于 Grafana OSS 构建,并增加了许多企业级功能
高级数据源:除了支持 OSS 中的数据源外,还提供企业级数据源支持,比如ServiceNow、Datadog等
企业插件:提供专有的企业插件和增强功能
团队和角色管理:提供更细粒度的权限管理,可以针对不同的团队和角色设置不同的权限
审计日志:记录用户操作日志,方便审计和合规管理
报表和导出:支持生成报表和数据导出功能
企业支持:提供专业的技术支持和咨询服务
2.安装部署
注意
安装Grafana OSS 版本
本次采用基于二进制方式安装,基于Docker Image或者Kubernetes集群或者Helm Charts 见其他文档
安装方式
基于YUM方式安装
基于二进制方式安装
基于Docker Image 部署
基于Kubernetes集群部署
基于Helm Charts 部署
获取二进制包
[root@grafana ~]# wget https://dl.grafana.com/oss/release/grafana-11.1.0.linux-amd64.tar.gz
安装
[root@grafana ~]# tar xf grafana-11.1.0.linux-amd64.tar.gz -C /usr/local/
[root@grafana ~]# mv /usr/local/grafana-v11.1.0/ /usr/local/grafana
安装数据库
注意:
Grafana会产生数据,并使用数据库存储,默认使用主数据库,我们也可以自己配置数据库
本案例中以Mysql为例,安装略
如果使用,需要按照要求完成对数据库的配置
安装Redis
注意:
Grafana可以配置缓存服务器,来提升Grafana的性能
本案例中以Redis为例,安装略
如果使用,需要按照要求完成对Redis的配置
配置Grafana
配置文件官方地址:https://grafana.com/docs/grafana/latest/setup-grafana/configure-grafana/
Grafana 实例的默认设置存储在该$WORKING_DIR/conf/defaults.ini文件中
自定义配置文件可以是文件$WORKING_DIR/conf/custom.ini或/usr/local/etc/grafana/grafana.ini
参数解释
服务端配置:
[server]
# Protocol (http, https, h2, socket)
protocol = http
# Minimum TLS version allowed. By default, this value is empty. Accepted values are: TLS1.2, TLS1.3. If nothing is set TLS1.2 would be taken
min_tls_version = ""
# The ip address to bind to, empty will bind to all interfaces
http_addr = 10.9.12.172
# The http port to use
http_port = 3000
# The public facing domain name used to access grafana from a browser
domain = localhost
# Redirect to correct domain if host header does not match domain
# Prevents DNS rebinding attacks
enforce_domain = false
# The full public facing url
root_url = %(protocol)s://%(domain)s:%(http_port)s/
# Serve Grafana from subpath specified in `root_url` setting. By default it is set to `false` for compatibility reasons.
serve_from_sub_path = false
protocol:设置为 http 以使用 HTTP 协议
min_tls_version:此参数在 HTTP 协议下不需要配置,可以留空
http_addr:绑定的 IP 地址,设置为 10.9.12.172
http_port:HTTP 端口,设置为 3000
domain:域名,设置为 localhost
enforce_domain:设置为 false 以禁用域名重定向检查
root_url:设置为 http://localhost:3000/,包含协议、域名和端口
serve_from_sub_path:如果你不需要从子路径提供服务,设置为 false
连接数据库配置:
[database]
# You can configure the database connection by specifying type, host, name, user and password
# as separate properties or as a url in the following format:
# url = postgres://grafana:grafana@localhost:5432/grafana
# Either "mysql", "postgres" or "sqlite3", it's your choice
type = mysql
host = 127.0.0.1:3306
name = grafana
user = root
password = your_password
# Use either URL or the previous fields to configure the database
# url = mysql://root:your_password@127.0.0.1:3306/grafana
# For "postgres" only, either "disable", "require" or "verify-full"
ssl_mode = disable
# For "sqlite3" only, path relative to data_path setting
# file = grafana.db
type:设置为 mysql 以使用 MySQL 数据库
host:设置为 MySQL 数据库的地址和端口
name:数据库名称
user:数据库用户
password:数据库用户的密码
连接Redis配置:
# Cache configuration section
[cache]
# Cache type: Either "redis", "memcached" or "database" (default is "database")
type = redis
# Cache connection string options
# database: will use Grafana primary database.
# redis: config like redis server e.g. `addr=127.0.0.1:6379,pool_size=100,db=0,ssl=false`. Only addr is required. ssl may be 'true', 'false', or 'insecure'.
# memcache: 127.0.0.1:11211
connstr = addr=10.9.12.206:6379,pool_size=100,db=0,ssl=false
# Prefix prepended to all the keys in the remote cache
prefix = grafana_
# This enables encryption of values stored in the remote cache
encryption = true
type:缓存类型,可以是 redis、memcached 或 database。默认是 database,即使用 Grafana 的主数据库进行缓存
connstr:缓存连接字符串,根据缓存类型不同而不同
database:无需配置连接字符串,会自动使用 Grafana 的主数据库redis:配置类似addr=127.0.0.1:6379,pool_size=100,db=0,ssl=false。其中addr是必需的,ssl可以是true、false或insecurememcache:配置类似127.0.0.1:11211
prefix:在所有缓存键前添加的前缀,用于区分不同应用的数据
encryption:启用存储在远程缓存中的值的加密
运行Grafana
[root@grafana ~]# nohup ./bin/grafana-server --config ./conf/defaults.ini &
注意:在Grafana的安装目录下执行
安装目录
bin:存放 Grafana 的可执行文件,通常包含 grafana-server 和 grafana-cli 等
data:存放运行时数据,如 SQLite 数据库文件、日志文件和临时文件等
docs:存放项目的文档,包括用户手册、开发者文档等
npm-artifacts:存放由 npm 构建生成的文件和包
plugins-bundled:包含预打包的插件,默认插件通常都放在这里
README.md:项目的 README 文件,包含项目的介绍、安装使用说明等信息
tools:存放开发和维护 Grafana 的工具脚本或程序
conf:存放 Grafana 的配置文件,如 grafana.ini 等
Dockerfile:用于构建 Grafana Docker 镜像的文件,定义了如何在 Docker 中安装和配置 Grafana
LICENSE:项目的许可证文件,说明了 Grafana 的使用和分发许可
NOTICE.md:包含版权和许可声明的文件,通常用于第三方组件的声明
packaging:包含用于构建和分发 Grafana 的打包脚本和配置文件
public:包含前端静态资源,如 HTML、CSS、JavaScript 文件等,用于 Grafana 的 Web 界面
storybook:用于存放 Storybook 配置和故事文件,Storybook 是一个用于开发和测试 UI 组件的工具
VERSION:包含当前 Grafana 版本号的文件,通常是一个文本文件
3.使用案例
案例一:监控Kubernetes集群中某个Node节点的POD数量
添加数据源
数据源不需要额外重复添加
添加数据源:本实验数据源来自Prometheus,也可以是其他的数据源,例如:InfluxDB,Zabbix等
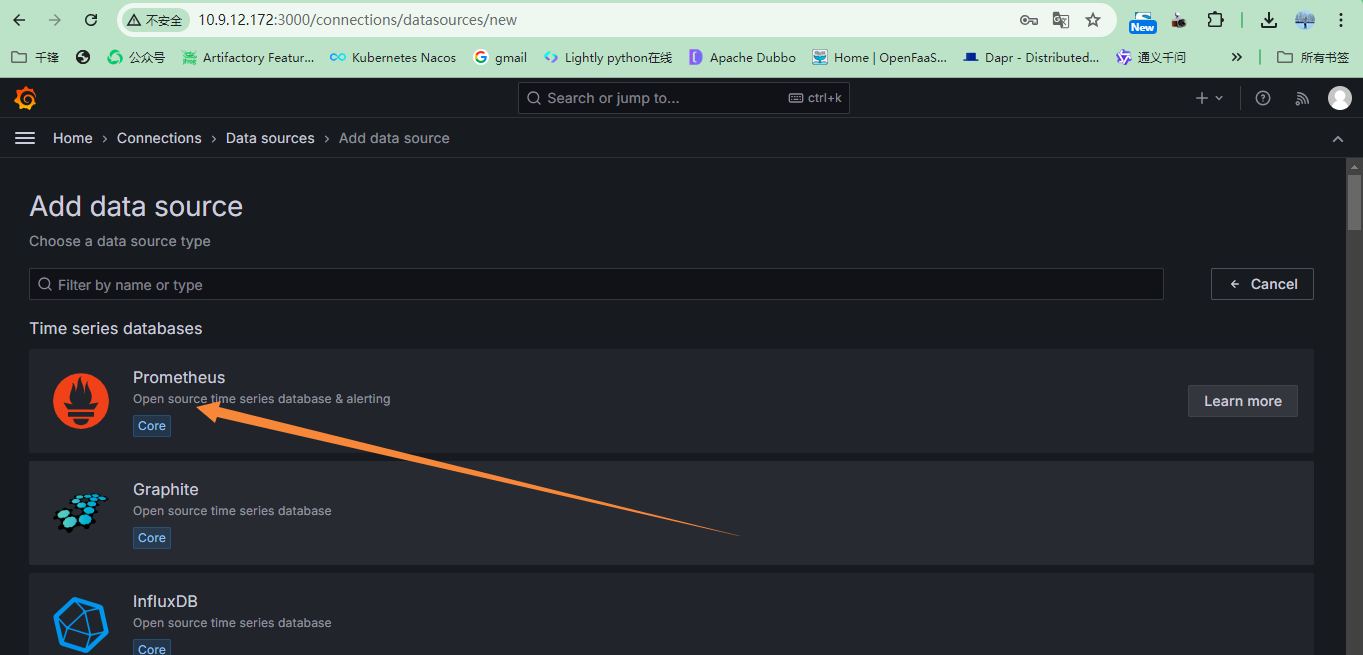
指定数据源的名字,名字自定义,有意义就可以
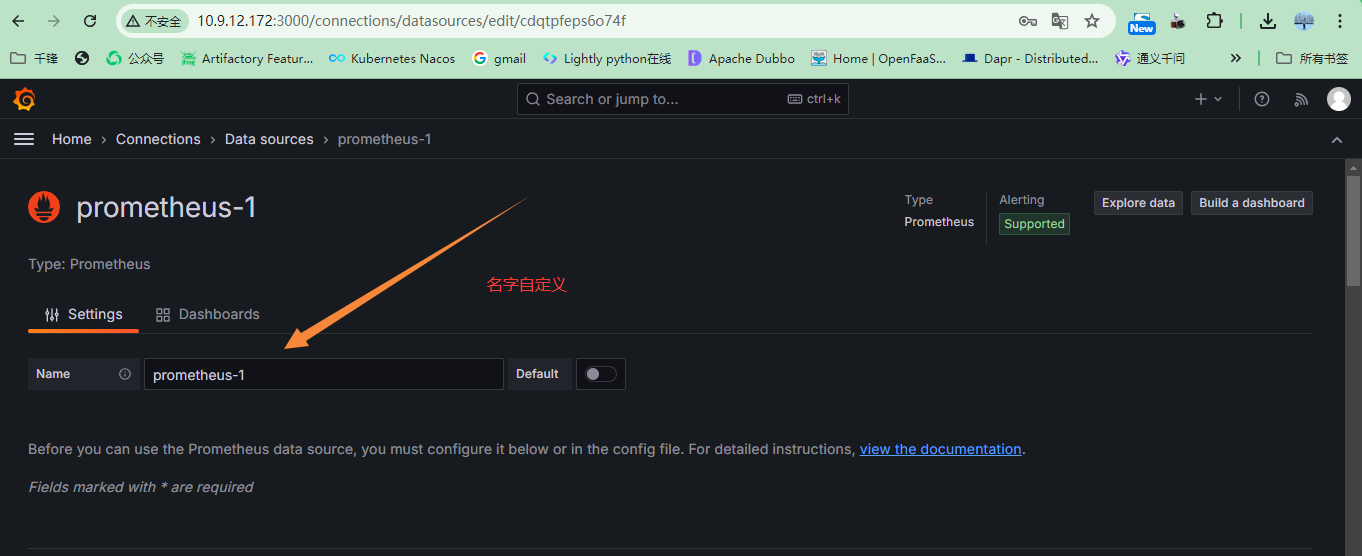
指定数据源的地址,本案例是Prometheus的地址
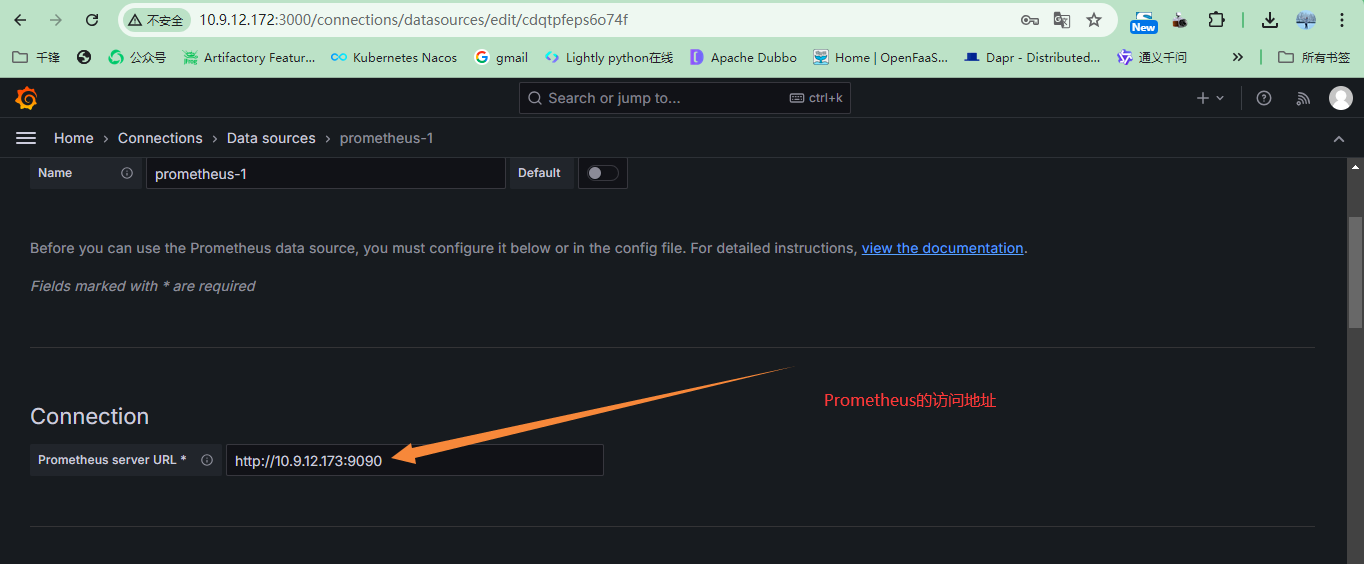
保存及测试
创建仪表盘
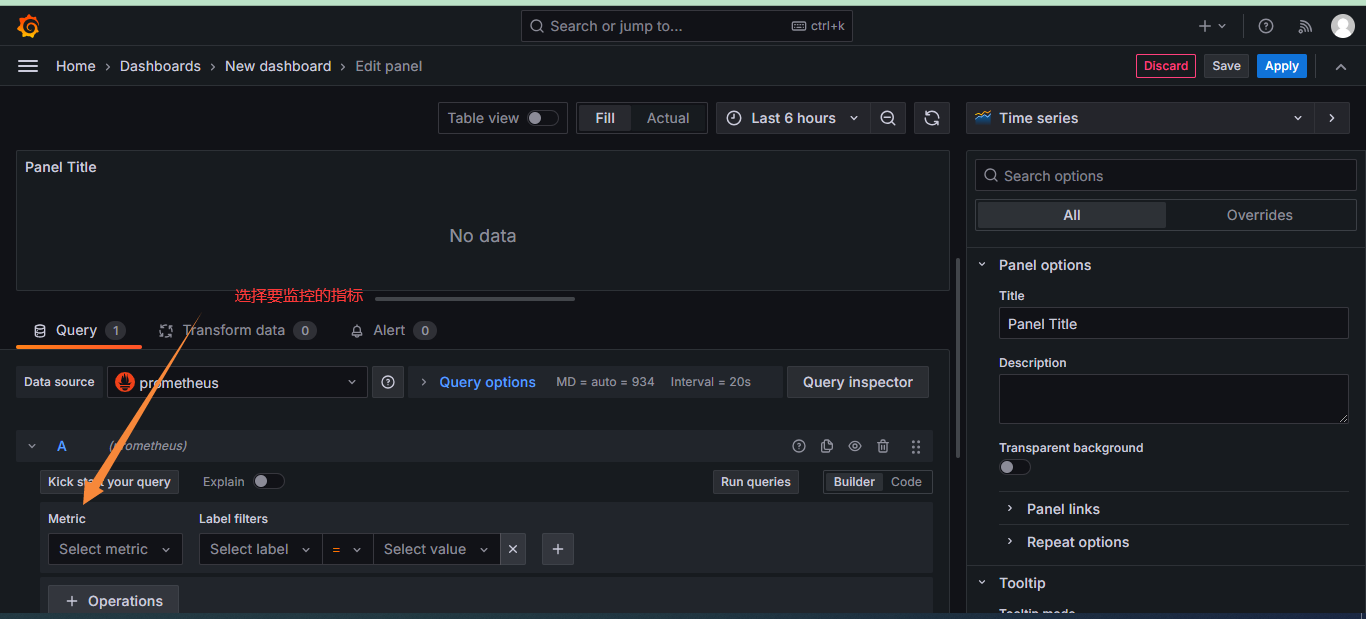
添加指标:这些指标都来自于Prometheus
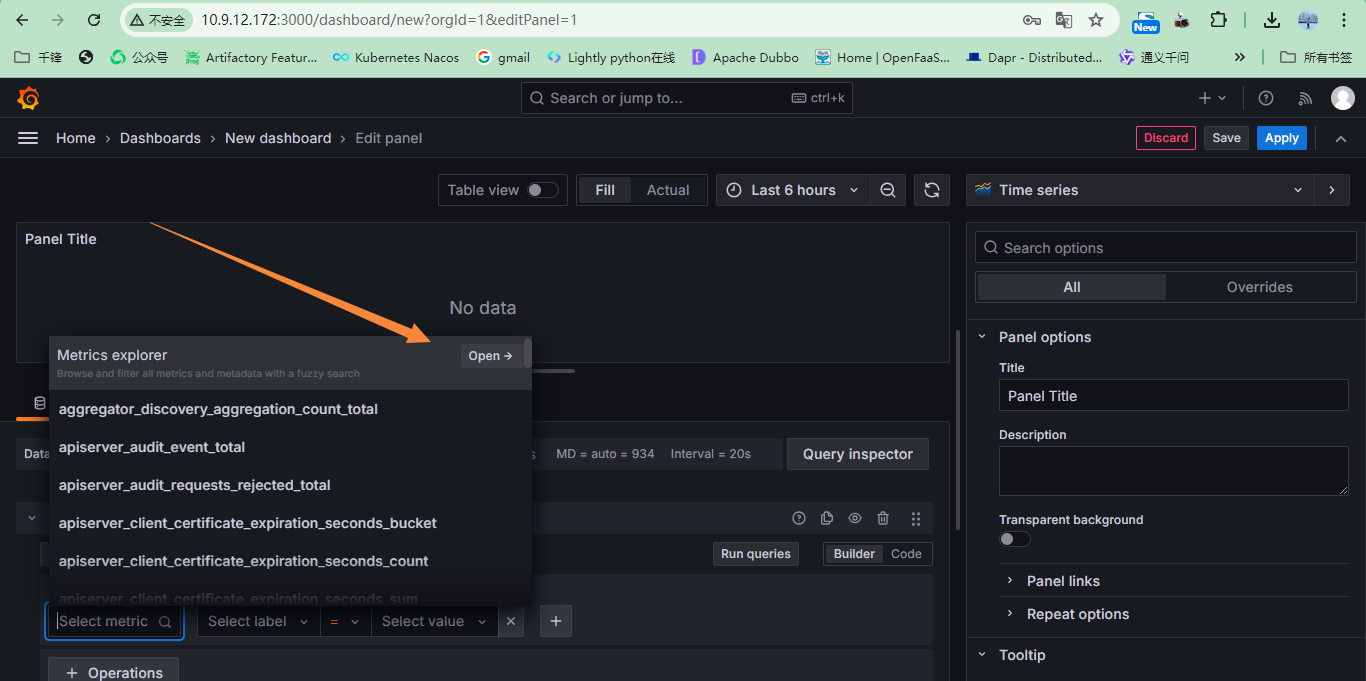

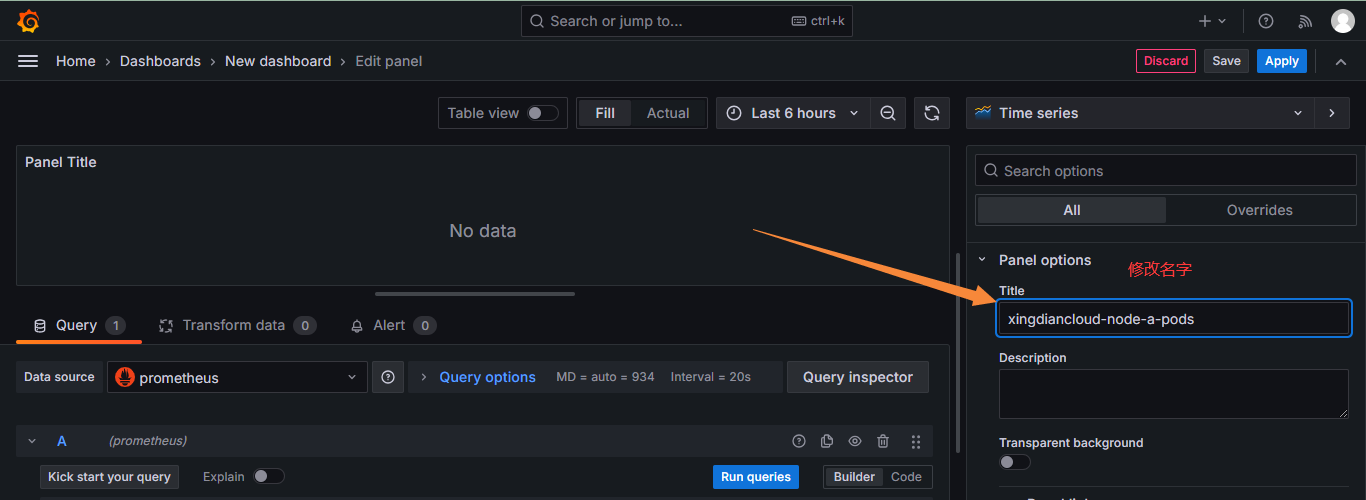
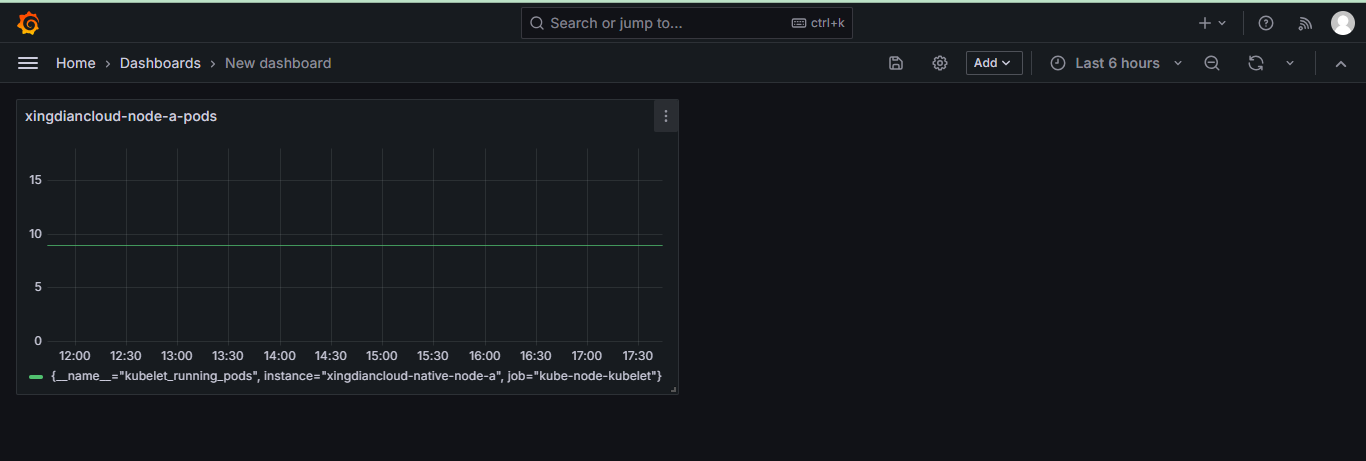
查看图形
4.Variables使用
初识变量
变量(Variables)一般包含一个或多个可选择的值
使用变量我们可以创建出交互式的动态仪表盘
类似于Zabbix中的模板
使用原因
当用户只想关注其中某些主机时,基于当前我们已经学习到的知识只有两种方式,要么每次手动修改Panel中的PromQL表达式,要么直接为这些主机创建单独的Panel;主机有很多时,需要新建无数的仪表盘来展示不同的主机状态,好在Grafana中有Variables,可以动态修改仪表盘中的参数,这样仪表盘的内容也会随参数的值改变而改变
如何定义
通过Dashboard页面的Settings选项,可以进入Dashboard的配置页面并且选择Variables子菜单
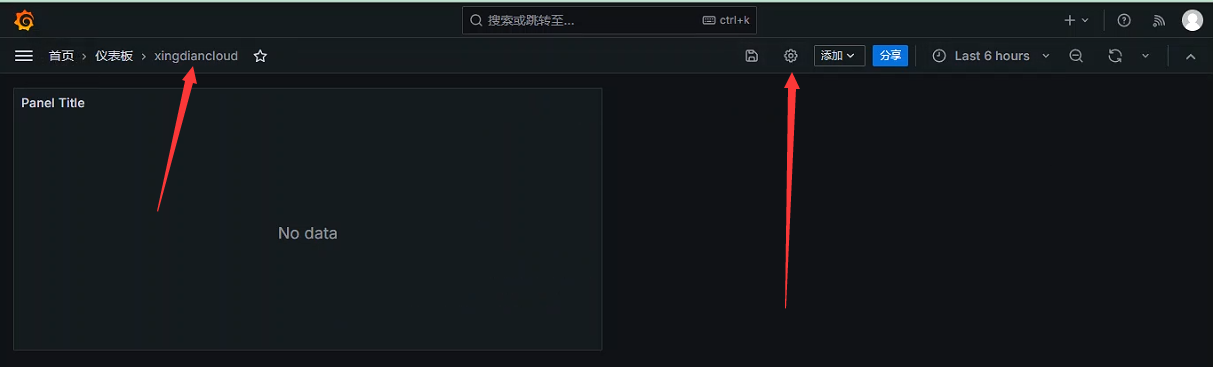
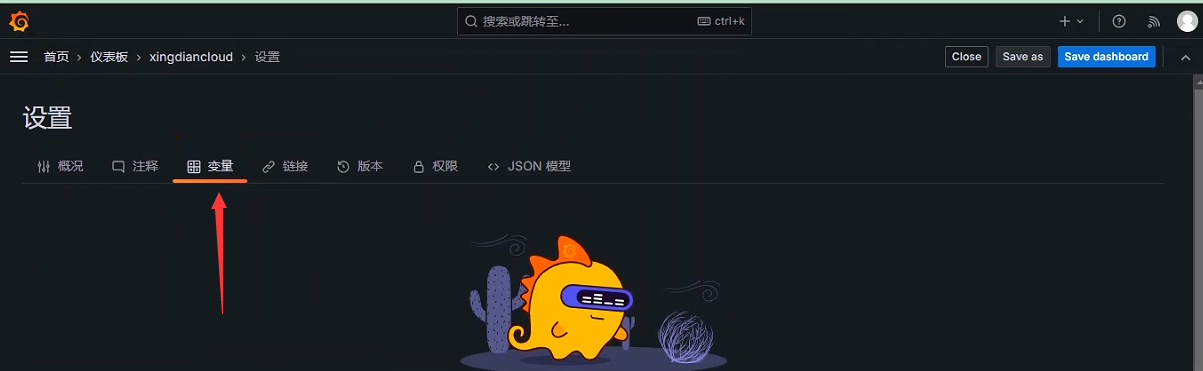
变量类型
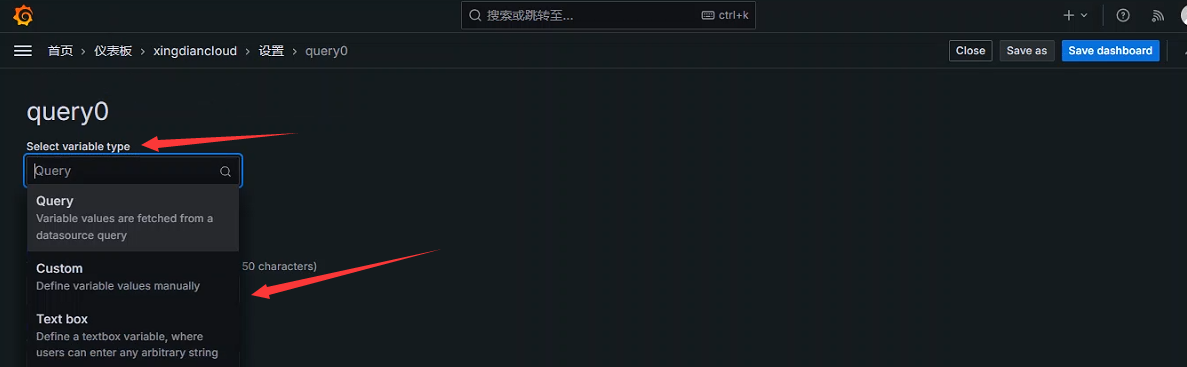
Interval(间隔)此变量可以表示查询的时间跨度,使用interval变量来定义时间间隔
Query(查询)此变量用于编写数据源查询,与Query Options中的设置配合使用,通常返回度量名称,标签值等。例如,返回主机或主机组的名称
Datasource(数据源)次变量 用于指定数据源,例如有多个zabbix源时,就可以使用此类变量,方便在Dashboard中交互切换数据源,快速显示不同数据源中的数据
Custom(自定义)用户自定义设置的变量
Constant(常量)定义可以隐藏的常量。对于要共享的仪表盘中包括路径或者前缀很有用。在仪表盘导入过程中。常量变量将成为导入时的选项
Ad hoc filters(Ad hoc过滤器)这是一种非常特殊的变量、目前只适用于某些数据源、如InfluxDB、Prometheus、Elasticsearch。使用指定数据源时将自动添加所有度量查询出的键/值
Text Box(文本框)次变量用于提供一个可以自由输入的文本框
General配置
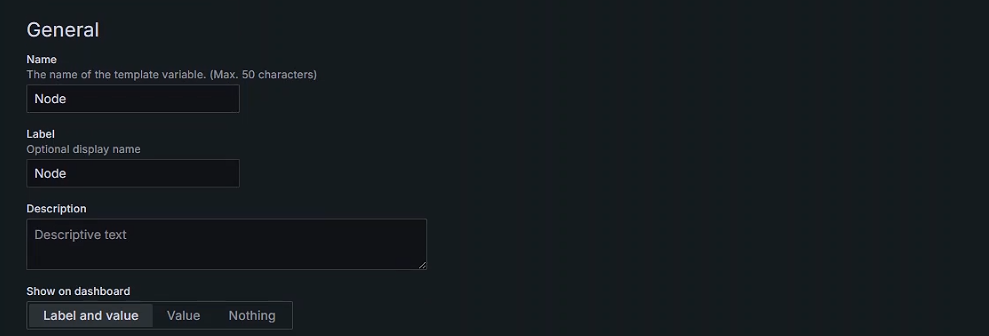
- Name(定义变量名称)
- Label(标签),在仪表盘上显示标签的名字
- Description (描述),类似于说明书可以省略
- Show on dashboard (展示在仪表盘)默认展示标签和值
Query options 配置
Data source(可以指定数据源)
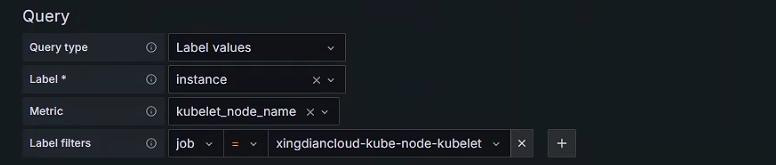
Refresh 配置

Selection options 配置

Multi-value:Enables multiple values to be selected at the same time 允许选择多个值
Apply
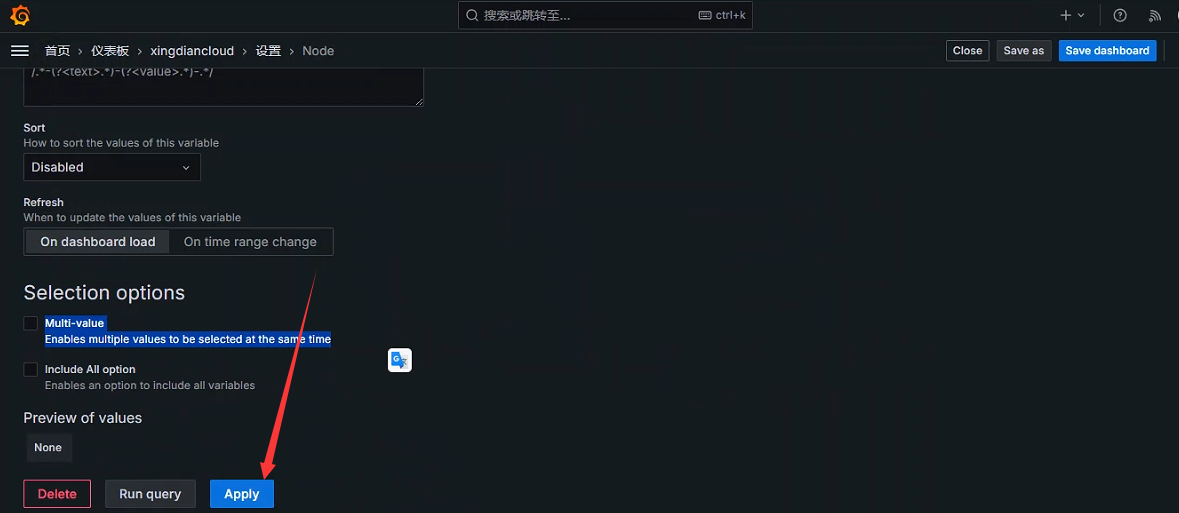
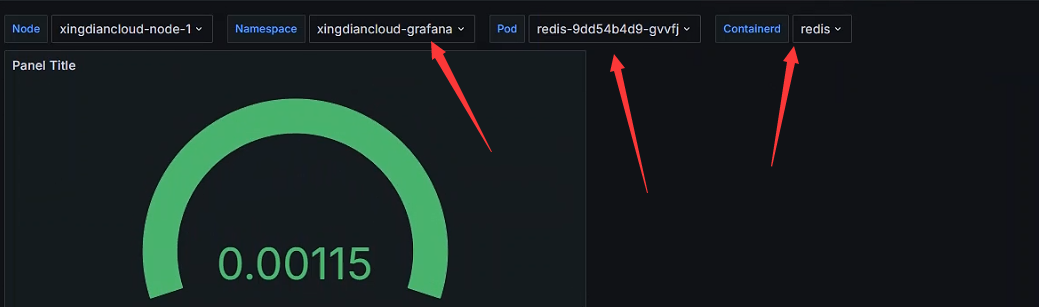
Kubernetes应用案例

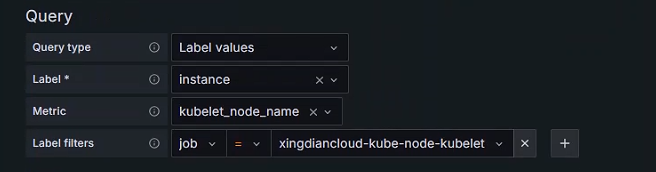
Node变量
Namespace变量
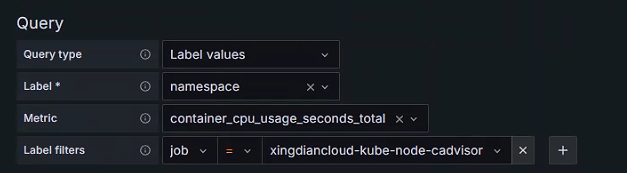
Pod变量
注意:Pod变量的上级是Namespace

Containerd变量
注意:Containerd变量的上一级是Pod,Pod的上一级是Namespace

变量在Dashboard中展示

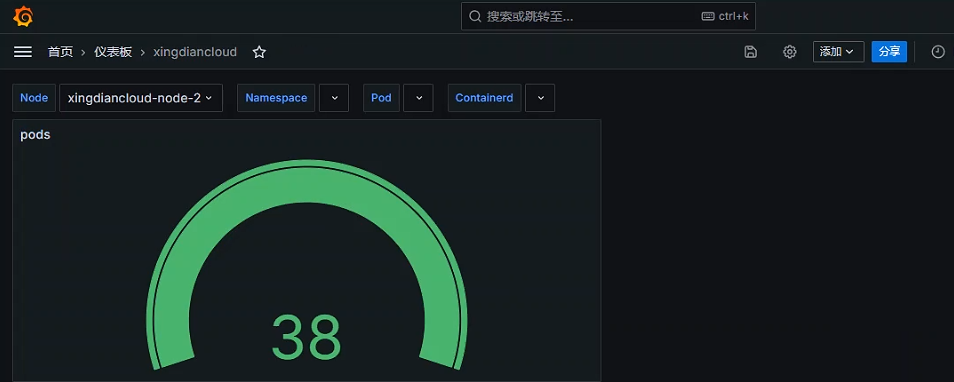
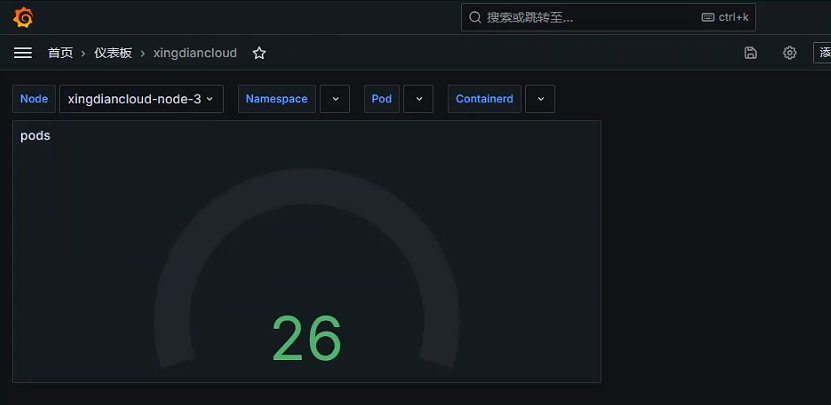
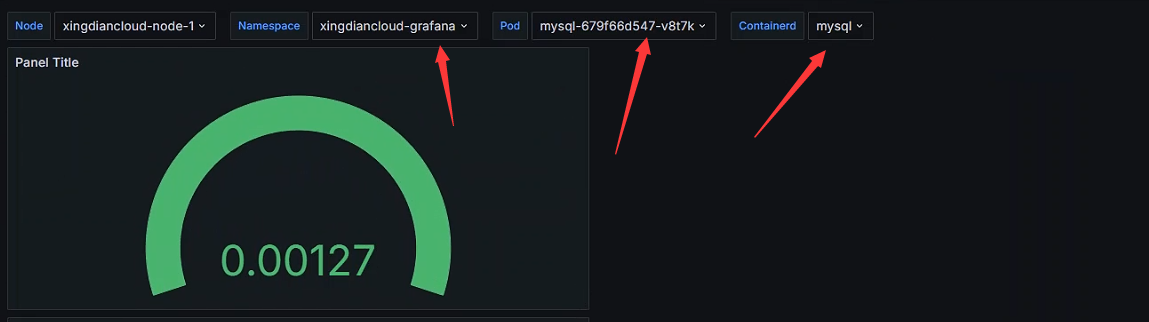
获取每个节点POD的数量
指标中调用变量
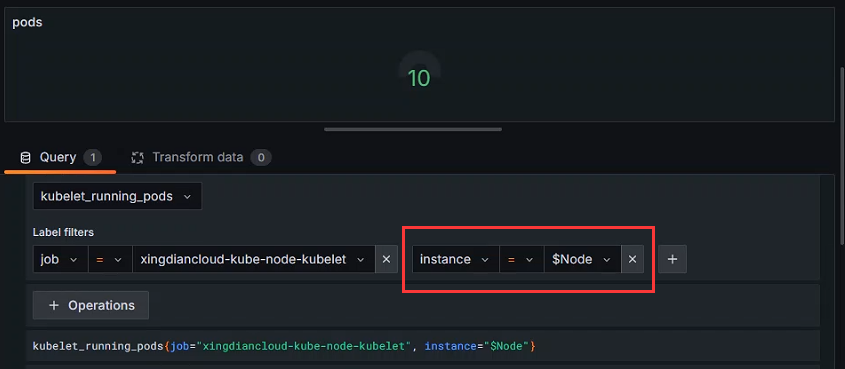
数据展示
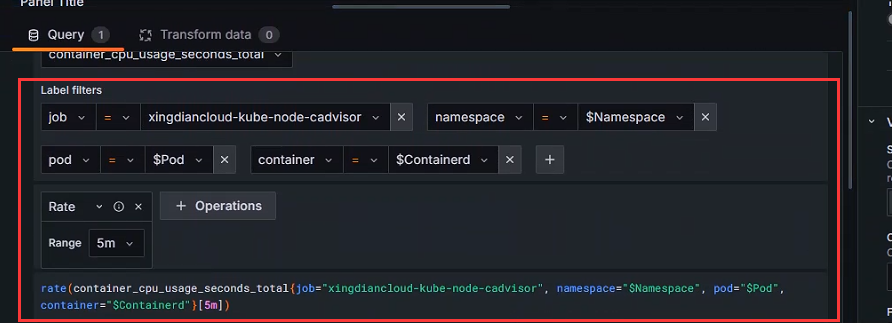
每个容器在该时间窗口内的总 CPU 使用率
指标中调用变量
rate(container_cpu_usage_seconds_total{job="xingdiancloud-kube-node-cadvisor", namespace="$Namespace", pod="$Pod", container="$Containerd"}[5m])
数据展示
五:Promql使用
1.Promql简介
Prometheus 是一个强大的开源监控系统,其查询语言 PromQL (Prometheus Query Language) 允许用户执行灵活的时间序列数据查询和分析
PromQL是Prometheus提供的一个函数式的表达式语言,可以使用户实时地查找和聚合时间序列数据
表达式计算结果可以在图表中展示,也可以在 Prometheus表达式浏览器中以表格形式展示,或者作为数据源以HTTP API的方式提供给外部系统使用
PromQL虽然以QL结尾,但是它不是类似SQL的语言,因为在时间序列上执行计算类型时,SQL语言相对缺乏表达能力
PromQL语言表达能力非常丰富,可以使用标签进行任意聚合,还可以使用标签将不同的标签连接到一起进行算术运算操作
内置了时间和数学等很多函数可以使用
时间序列: 时间序列是 Prometheus 中的核心数据单元。它由一个唯一的 metric 名称和一组键值对标签标识
样本: 每个时间序列由多个样本组成。样本包括一个时间戳和一个值
指标 : 指标是 Prometheus 中收集的数据类型,有四种:Counter(计数器)、Gauge(仪表盘)、Histogram(直方图)和 Summary(摘要)
2.Promql基本语法
语言数据类型
Instant vector:瞬时向量,一组time series(时间序列),每个time series包括了一个时间戳的数据点,所有time series数据点拥有相同的时间戳
Range vector:范围向量,一组time series包含一个时间范围内的一组数据点
Scalar:标量,为一个浮点数值
String:字符串,为一个字符串数值;当前未使用
Literals数据格式
String literals:字符串可以用单引号(‘’)、双引号(“”)或反引号(``)指定为文字
Float literals:浮点类型数值的格式为:-[.(digits)]
Time series(时间序列)选择器
Instant vector selectors(即时矢量选择器)
瞬时向量选择器用于选择一组time series和每个time series对应的某一个时间戳数据点,唯一的要求是必须指定metric指标名
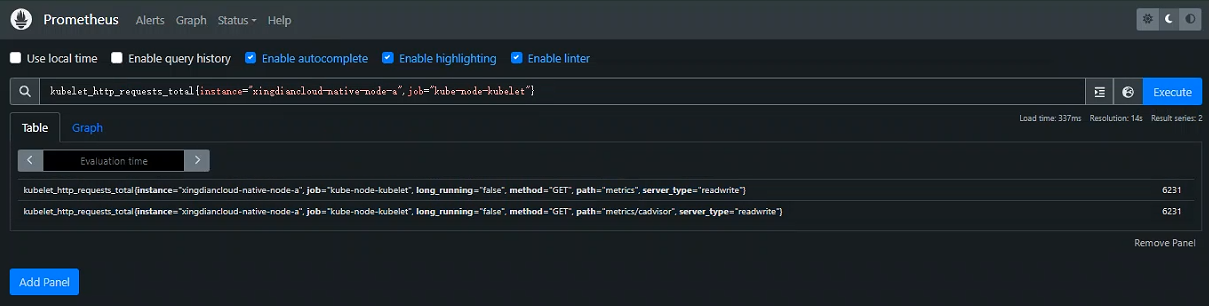
案例:查询指标名kubelet_http_requests_total对应的所有time series表达式
可以通过在花括号 ( {}) 中附加一个逗号分隔的标签匹配器列表来进一步过滤这些时间序列
仅选择具有
kubelet_http_requests_total度量名称且instance标签设置为xingdiancloud-native-node-a且其job标签设置为的时间序列kube-node-kubelet
kubelet_http_requests_total{instance="xingdiancloud-native-node-a",job="kube-node-kubelet"}
通过负匹配或正则表达式匹配tag选择时间序列,支持如下匹配运算符:
= 等于
!= 不等于
=~ 选择与提供的字符串进行正则表达式匹配的标签
!~ 选择与提供的字符串不匹配的标签
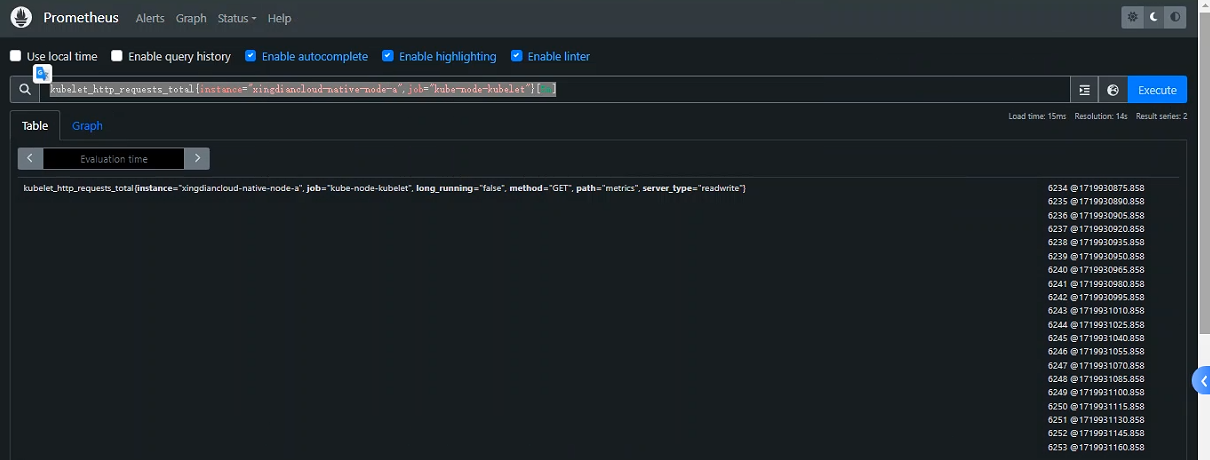
Range vector selectors(范围矢量选择器)
范围向量字面量的工作方式类似于即时向量字面量,唯一区别是选择的时间序列是一个时间范围内的时序数据。从语法上讲,持续时间附加在[]向量选择器末尾的方括号 ( ) 中,以指定应该为每个结果范围向量元素获取多远的时间值
案例:为所有时间序列选择了过去 5 分钟内记录的所有值,指标名称kubelet_http_requests_total和job标签设置为kube-node-kubelet且instance标签设置为xingdiancloud-native-node-a
kubelet_http_requests_total{instance="xingdiancloud-native-node-a",job="kube-node-kubelet"}[5m]
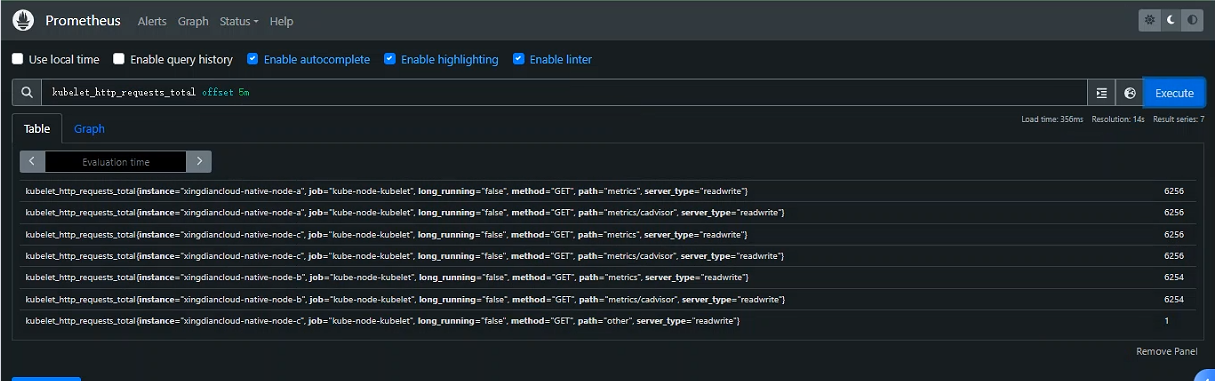
Offset modifier(偏移修改器)
Offset修改器允许修改查询中瞬时向量和范围向量的时间偏移
案例:返回kubelet_http_requests_total相对于当前查询评估时间过去 5 分钟的值
注意:offset修饰符总是需要立即跟随选择器
kubelet_http_requests_total offset 5m
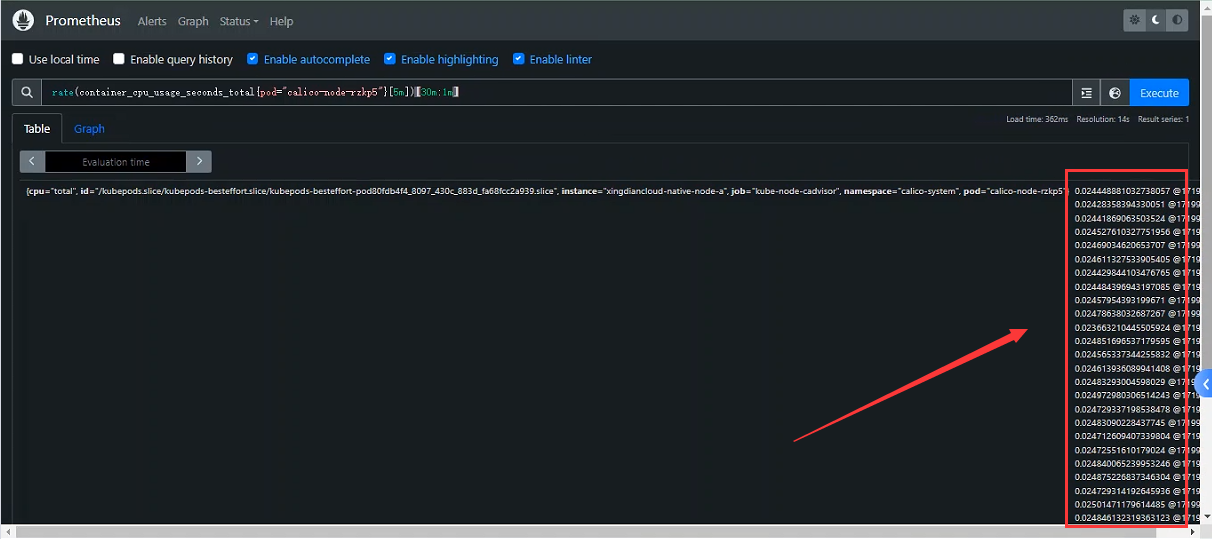
Subquery(子查询)
子查询允许针对给定的范围和分辨率运行即时查询;子查询的结果是一个范围向量
<instant_query> [ : []] [offset ]
注:是可选的,默认为全局评估间隔
案例:过去30分钟container_cpu_usage_seconds_total 5m统计的rate(平均增长速率)值,精度是1分钟
rate(container_cpu_usage_seconds_total{pod="calico-node-rzkp5"}[5m])[30m:1m]
3.PromQL运算符
PromQL支持基本的逻辑和算术运算;对于两个瞬时向量的运算,其结果可能影响匹配行为
算数运算符
+(加法)
- (减法)
* (乘法)
/ (除法)
%(模数)
^(幂)
匹配运算符
== (等于)
!= (不等于)
> (大于)
< (小于)
>=(大于或等于)
<=(小于或等于)
=~(正则表达式匹配)
!~(正则表达式不匹配)
逻辑/集合运算符
and 过滤出两个向量里都有的时间序列
or 过滤出两个向量里所有的时间序列
unless 过滤出左边向量里,右边没有的时间序列
聚合运算符
支持以下内置聚合运算符,可用于聚合单个即时向量的元素,从而生成具有聚合值的元素更少的新向量
sum (总和)
min (最小值)
max (最大值)
avg (平均值)
group (结果向量中的所有值都是1)
stddev (计算维度上的总体标准偏差)
stdvar (计算维度上的总体标准方差)
count (计算向量中的元素个数)
count_values(计算具有相同值的元素个数)
bottomk (样本值的最小k个元素)
topk (按样本值计算的最大k个元素)
quantile (在维度上计算 φ-quantile (0 ≤ φ ≤ 1))
选择运算符
{}(标签选择器)
[](时间范围选择器)
集合运算符
on 指定了应该用于匹配的标签。只有这些标签完全匹配的向量才会被计算在内
ignoring 指定了在匹配时应该忽略的标签;除了这些被忽略的标签外,其他标签必须匹配
group_left、group_right 用于多对一或一对多的匹配,保留其他不匹配的标签
函数调用
rate() 函数用于计算每秒的平均变化率,通常用于计算每秒钟的平均增长量。它适用于计数器类型的指标,这些指标只会单调递增 increase() 函数同样用于计算计数器指标的增长量,但它返回的是指定时间窗口内的增量总和 delta() 函数用于计算任意类型指标的增量,它可以计算两个样本点之间的差值 irate() 函数用于估计瞬时的变化率,它计算在最近的时间间隔内的变化率。与 rate() 相比,irate() 可以更快速地反映短期的变化趋势
运算符优先级
聚合运算符
选择运算符
函数调用
逻辑运算符
匹配运算符
算术运算符
集合运算符
案例:
sum(rate(kubelet_http_requests_total{job="kube-node-kubelet"}[5m])) / sum(rate(kubelet_http_requests_total[5m]))
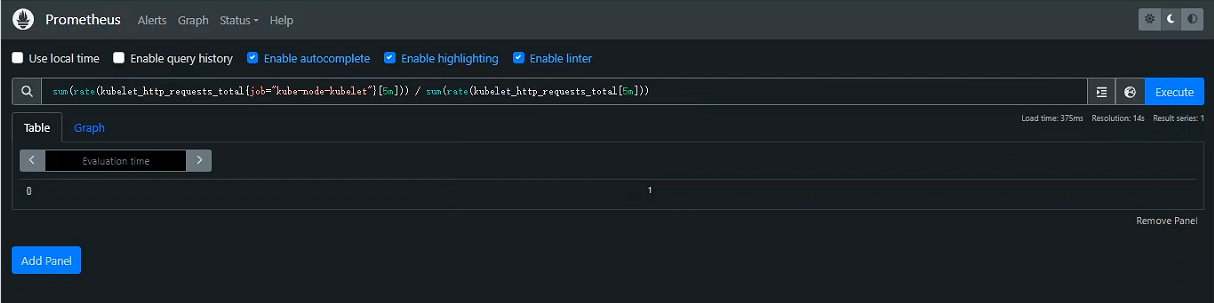
rate(kubelet_http_requests_total{job="kube-node-kubelet"}[5m])和rate(kubelet_http_requests_total[5m])中的选择运算符[]具有最高优先级
然后是函数调用
rate()
接下来是聚合运算符
sum()
最后是算术运算符
/
总结:了解这些优先级可以帮助你更准确地构建 PromQL 查询,确保查询按预期顺序执行
4.PromQL内置函数
一些函数有默认参数,例如year(v=vector(time()) instant-vector);这意味着有一个参数v是一个即时向量,如果没有提供,它将默认为表达式的值vector(time())
abs():
abs(v instant-vector)返回输入向量,其中所有样本值都转换为其绝对值
absent():
absent(v instant-vector)如果传递给它的瞬时向量有任何元素,则返回一个空向量;如果传递给它的向量没有元素,则返回一个值为 1 的 1 元素向量;通常用于设置告警,判断给定的指标和标签没有数据时产生告警
absent_over_time():
absent_over_time(v range-vector)如果传递给它的范围向量有任何元素,则返回一个空向量;如果传递给它的范围向量没有元素,则返回一个值为 1 的 1 元素向量;同absent(),常用于判断指标与标签组合,不存在于时间序列时报警
ceil():
ceil(v instant-vector)将所有元素的样本值四舍五入到最接近的整数
changes():
changes(v range-vector)计算给出的时间范围内,value是否发生变化,将发生变化时的条目作为即时向量返回
clamp():
clamp(v instant-vector, min scalar, max scalar)设定所有元素的样本值的上限与下限注:当min>max时,返回一个空向量:NaN if min or max is NaN
day_of_month():
day_of_month(v=vector(time()) instant-vector)以 UTC 格式返回每个给定时间的月份日期,返回值从 1 到 31
day_of_week():
day_of_week(v=vector(time()) instant-vector)以 UTC 格式返回每个给定时间的星期几,返回值从 0 到 6,其中 0 表示星期日
days_in_month():
days_in_month(v=vector(time()) instant-vector)以 UTC 格式返回每个给定时间该月的天数,返回值从 28 到 31
delta():
delta(v range-vector)计算范围向量中每个时间序列元素的第一个值和最后一个值之间的差,返回具有给定增量和等效标签的即时向量;增量被外推以覆盖范围向量选择器中指定的整个时间范围,因此即使样本值都是整数,也可以获得非整数结果
案例:
监控容器 CPU 使用情况的指标。具体来说,它表示容器在系统模式下使用的总 CPU 时间(以秒为单位)
现在跟2个小时前的差异
delta(container_cpu_system_seconds_total{pod="calico-node-pwlrv"}[2h])
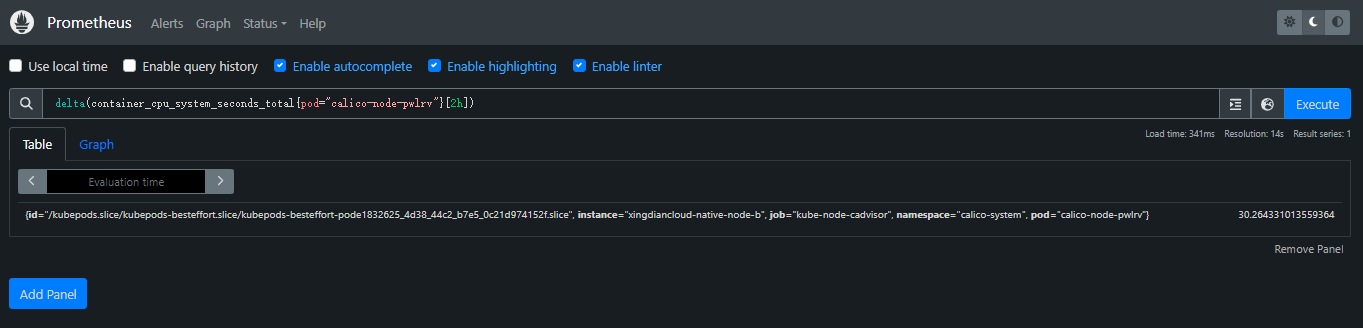
container:表示特定容器的 CPU 使用情况
cpu:表示 CPU 资源
system_seconds_total:系统模式下使用的总 CPU 时间,系统模式指的是操作系统内核执行的时间。
deriv(): deriv(v range-vector) 使用简单线性回归的方法计算时间序列在范围向量 中的每秒导数
注:deriv()函数在可视化页面上只能用于仪表盘
exp(): exp(v instant-vector) 计算v中所有元素的指数函数
histogram_quantile():分位直方图; histogram_quantile(φ scalar, b instant-vector) 从instant vector中获取数据计算q分位(0<= q <=1);b里的样本是每个桶的计数。每个样本必须具有标签le,表示桶的上限。直方图指标类型会自动提供了_bucket后缀和相应tags的time series;使用rate()函数指定分位计算的时间窗口
案例:指标名为kubelet_http_requests_duration_seconds_bucket,计算其对应所有time series过去10分钟90分位数
histogram_quantile(0.9,rate(kubelet_http_requests_duration_seconds_bucket[10m]))
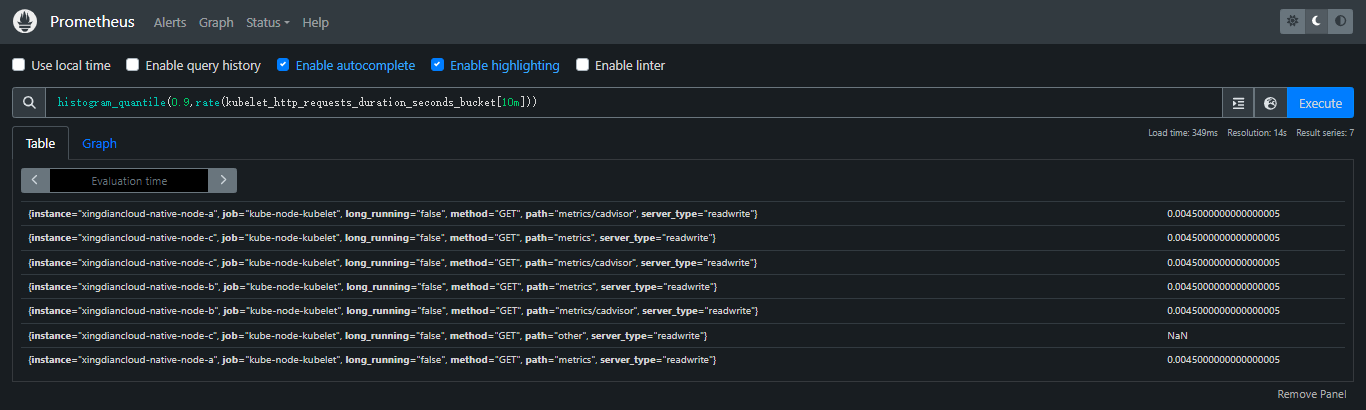
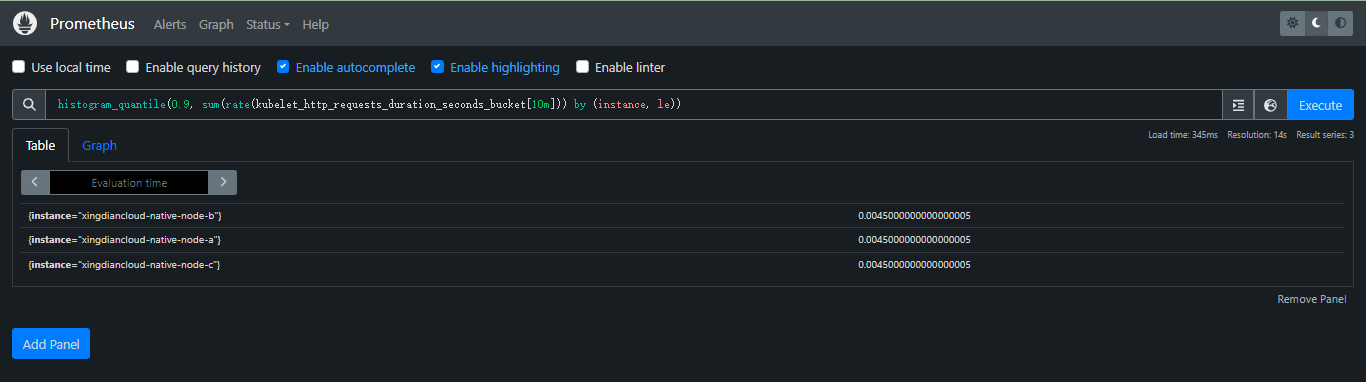
案例:指标名kubelet_http_requests_duration_seconds_bucket对应的每个tags组合(每个time series)计算90分位数;为了聚合数据,比如使用sum()进行聚合,需要通过by子句包含le标签
histogram_quantile(0.9, sum(rate(kubelet_http_requests_duration_seconds_bucket[10m])) by (instance, le))
hour(): hour(v=vector(time()) instant-vector) 以 UTC 格式返回每个给定时间的一天中的小时,返回值从 0 到 23
increase(): increase(v range-vector) 计算范围向量中时间序列的增量。单调性的中断(例如由于目标重新启动而导致的计数器重置)会自动调整。该增加被外推以覆盖范围向量选择器中指定的整个时间范围,因此即使计数器仅增加整数增量,也可以获得非整数结果
案例:返回范围向量中每个时间序列在过去 5 分钟内测量的 HTTP 请求数
increase(kubelet_http_requests_total{instance="xingdiancloud-native-node-a"}[5m])
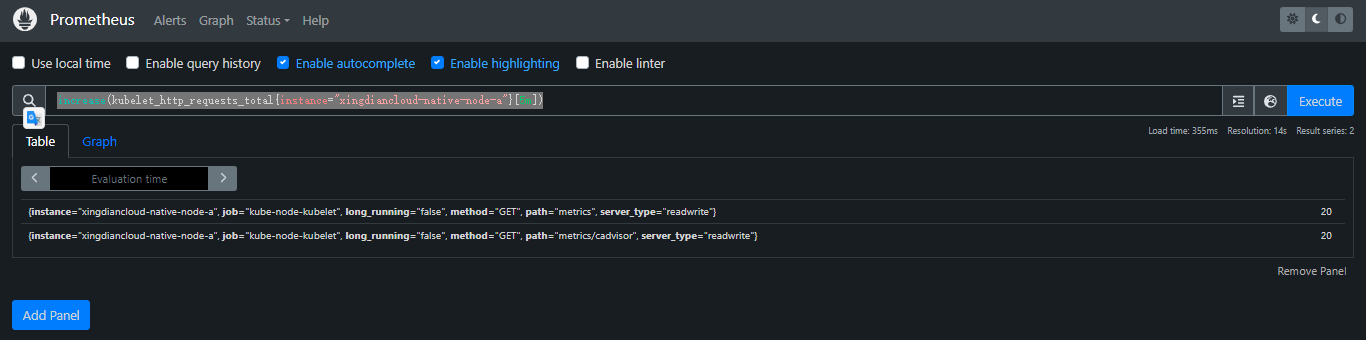
注:increase只能与counter类型指标(按增长率展示,即相邻两个时间点的差值除以时间差)一起使用。它是rate(v)乘以指定时间范围窗口下的秒数(相当于rate()乘以秒数),更易于人类理解。在记录规则中使用rate,以便每秒一致地跟踪增长。
irate():
irate(v range-vector)计算范围向量中时间序列的每秒瞬时增长率。这是基于最后两个数据点。单调性的中断(例如由于目标重新启动而导致的计数器重置)会自动调整
案例:返回针对范围向量中每个时间序列的两个最近数据点的 HTTP 请求的每秒速率,最多可追溯 5 分钟(瞬时增长速率)
irate(kubelet_http_requests_total{instance="xingdiancloud-native-node-a"}[5m])
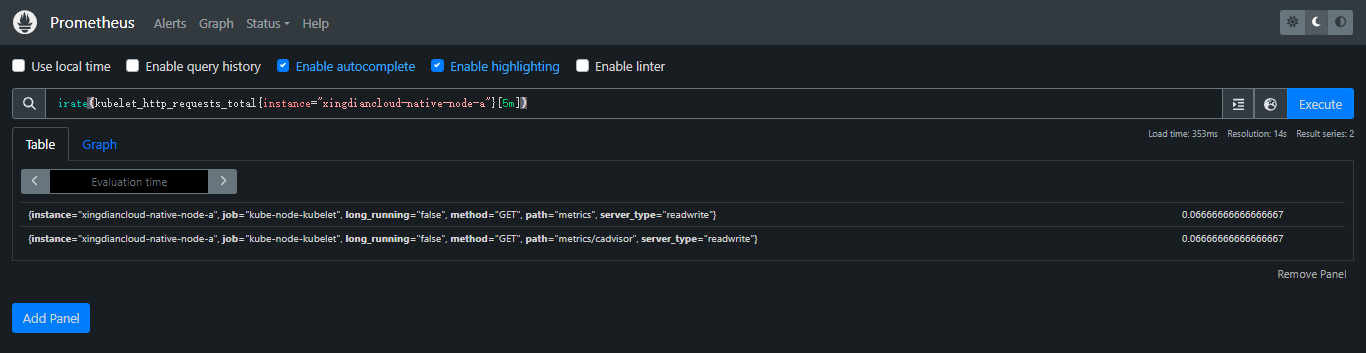
注:irate仅应在绘制易失性、快速移动的计数器时使用。用于rate警报和缓慢移动的计数器,因为速率的短暂变化可以重置
ln():ln(v instant-vector) 计算v中所有元素的自然对数
log2():log2(v instant-vector) 计算v中所有元素的二进制对数
rate(): rate(v range-vector) 计算范围向量中时间序列的每秒平均增长率。单调性的中断(例如由于目标重新启动而导致的计数器重置)会自动调整。此外,计算推断到时间范围的末端,允许错过刮擦或刮擦周期与该范围的时间段的不完美对齐
案例:返回在过去 5 分钟内测量的每秒 HTTP 请求速率,范围向量中的每个时间序列
rate(kubelet_http_requests_total{instance="xingdiancloud-native-node-a"}[5m])
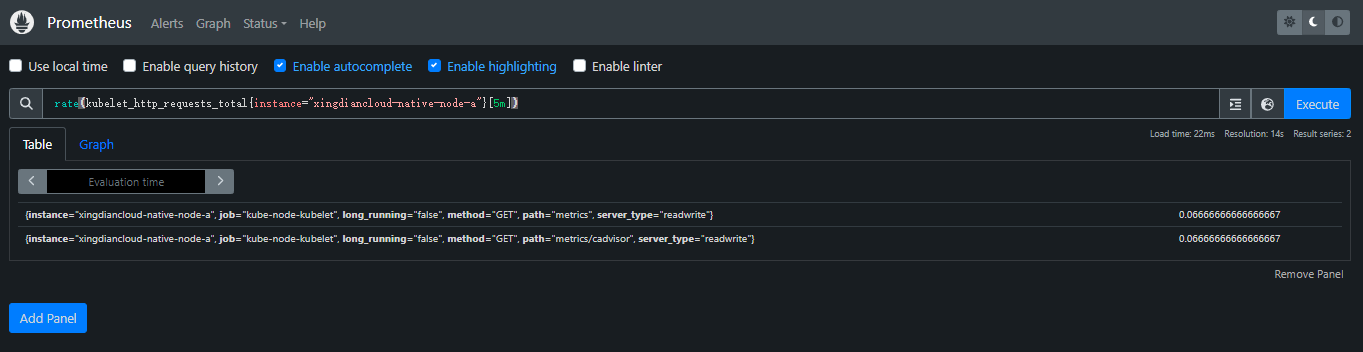
resets():resets(v range-vector) 对于每个输入时间序列,resets(v range-vector)将提供的时间范围内的计数器重置次数作为即时向量返回。两个连续样本之间值的任何减少都被解释为计数器复位;
注意:resets()只能作用于counter类型指标
round():round(v instant-vector, to_nearest=1 scalar) 将所有元素的样本值四舍五入为v最接近的整数。平局通过四舍五入解决。可选to_nearest参数允许指定样本值应该四舍五入的最接近的倍数。这个倍数也可以是分数。默认为1
scalar(): scalar(v instant-vector) 给定一个单元素输入向量,scalar(v instant-vector)以标量形式返回该单元素的样本值。如果输入向量没有恰好一个元素,scalar将返回NaN
sort():sort(v instant-vector) 返回按样本值升序排序的向量元素
time(): time() 返回自 1970 年 1 月 1 日 UTC 以来的秒数。请注意,这实际上并不返回当前时间,而是要计算表达式的时间
year():year(v=vector(time()) instant-vector) 以 UTC 格式返回每个给定时间的年份
5.相关案例
获取被监控的服务器内存的总量
machine_memory_bytes
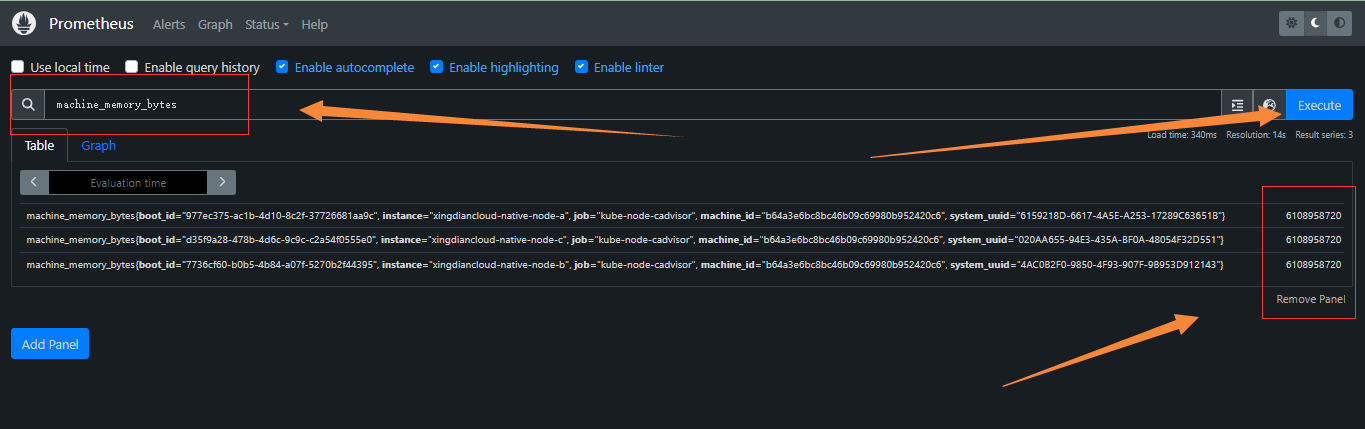
上图中每一行都是一个服务器的内存总量指标数据,后面是具体的值,单位: 字节。
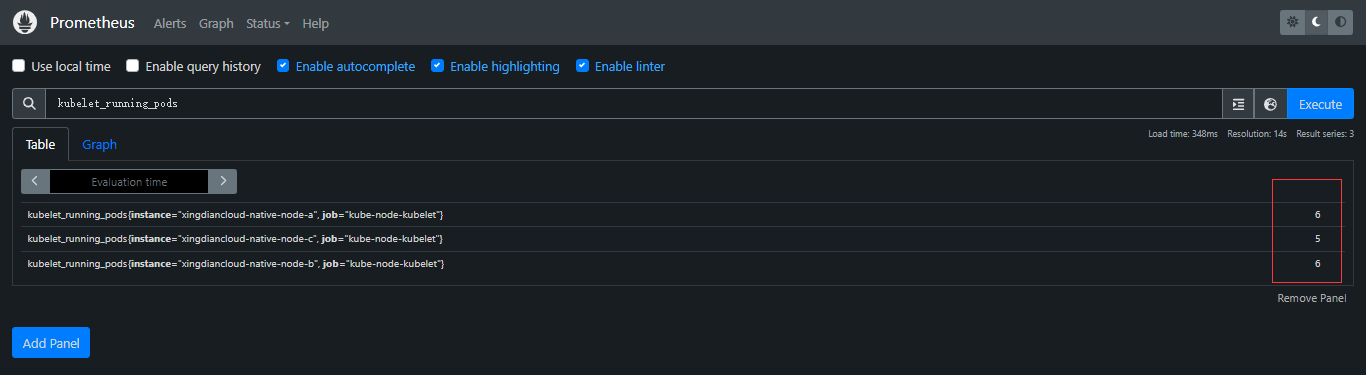
获取被监控节点每个节点POD数量
kubelet_running_pods
获取其中某一个节点POD数量
kubelet_running_pods{instance="xingdiancloud-native-node-a"}
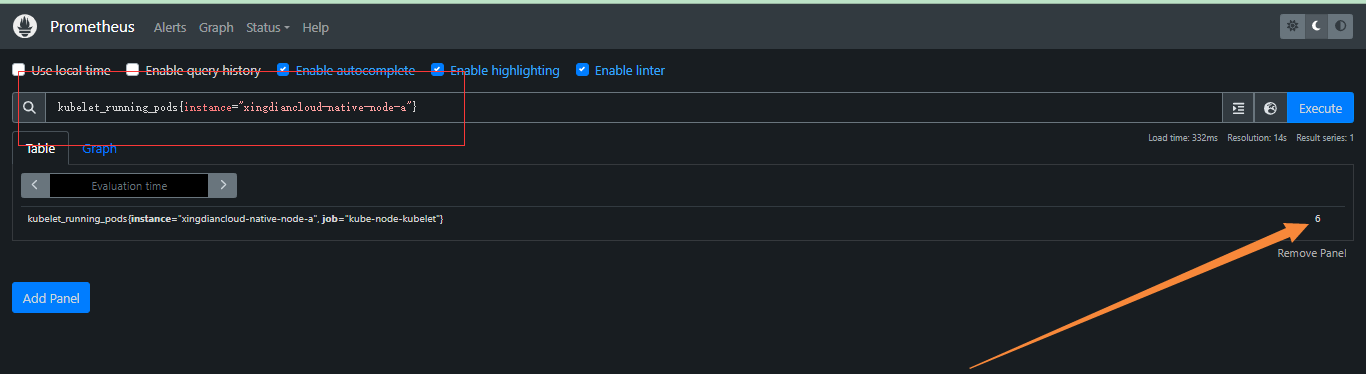
注意:instance 是一个标签,用来表示数据来源的实例。它通常用于区分不同的主机、服务器或服务实例;在 PromQL 查询中,instance 标签常用于筛选、分组和聚合来自不同实例的监控数据
基本查询
查询某个时间序列的最新值
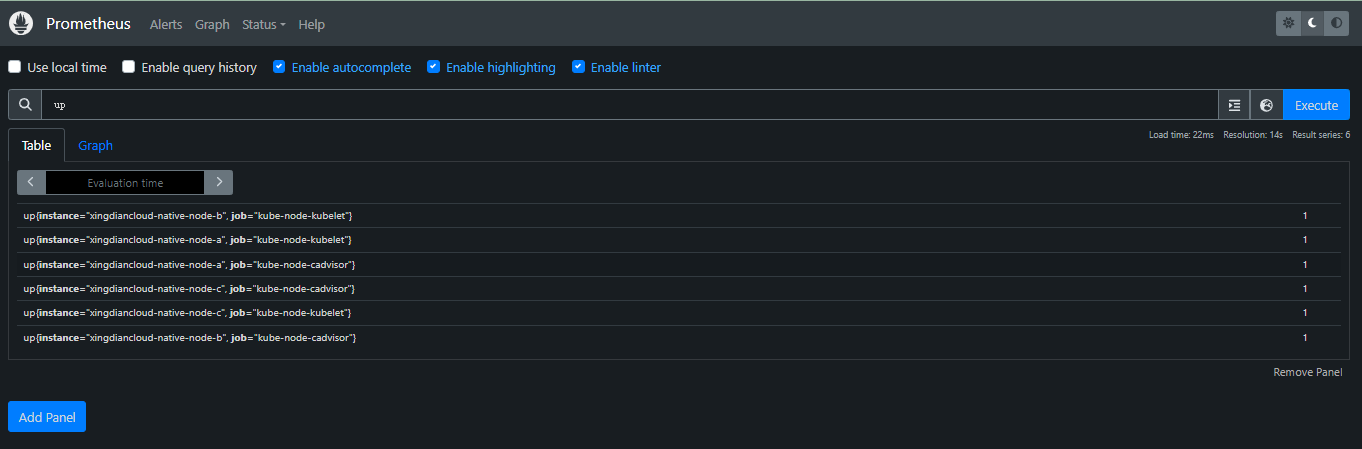
up
up 是一个内置指标,表示目标是否处于活动状态
查询某个时间序列的所有数据点
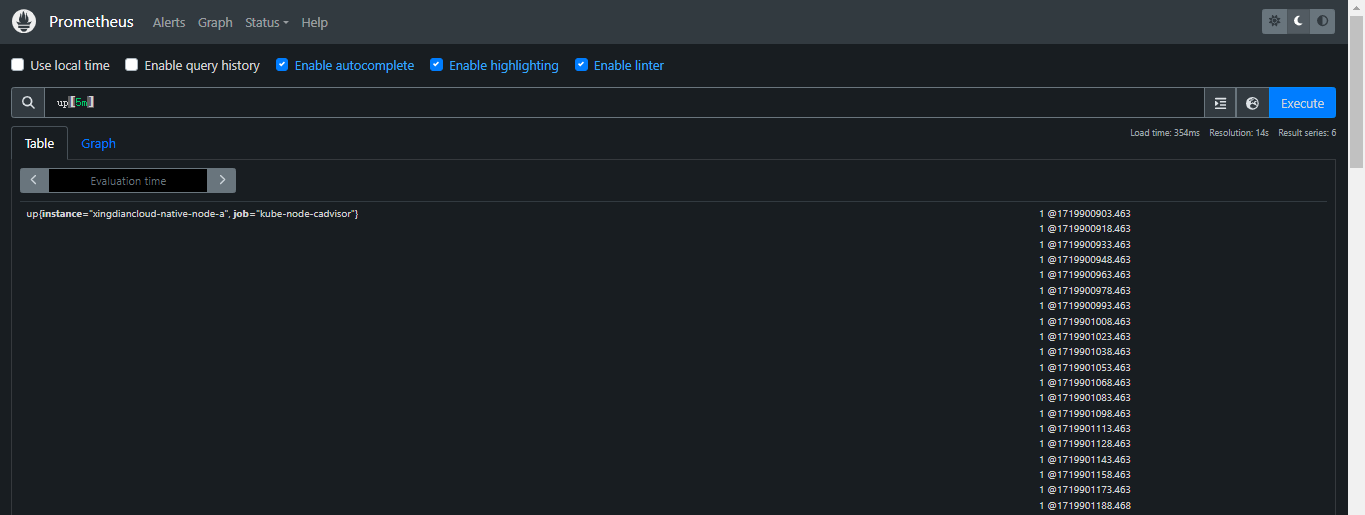
up[5m]
案例二:
自带指标
比率和变化率
计算指标在过去 5 分钟内每秒的变化率
rate(kubelet_http_requests_total[5m])
kubelet_http_requests_total: 这个指标表示 Kubelet 处理的 HTTP 请求的总数。
rate(): 这个函数用于计算时间序列的平均速率。它需要一个时间范围作为参数。
[5m]: 这个时间范围表示计算过去 5 分钟内的数据。
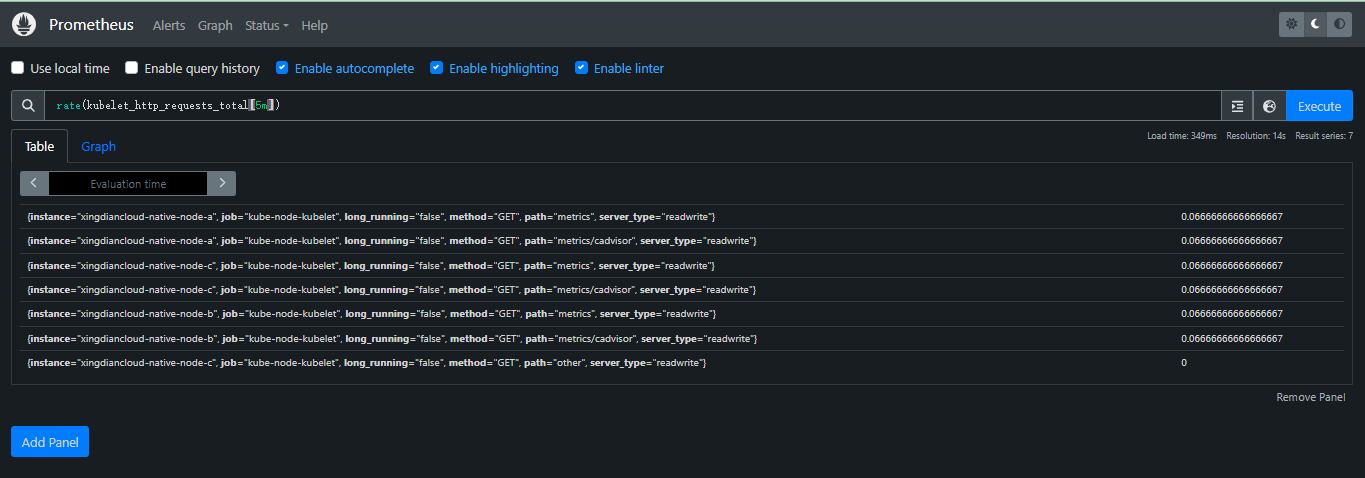
扩展了解
如果kubelet_http_requests_total指标包含method标签,你可以按 HTTP 方法分组查看请求速率:
rate(kubelet_http_requests_total{method="GET"}[5m])
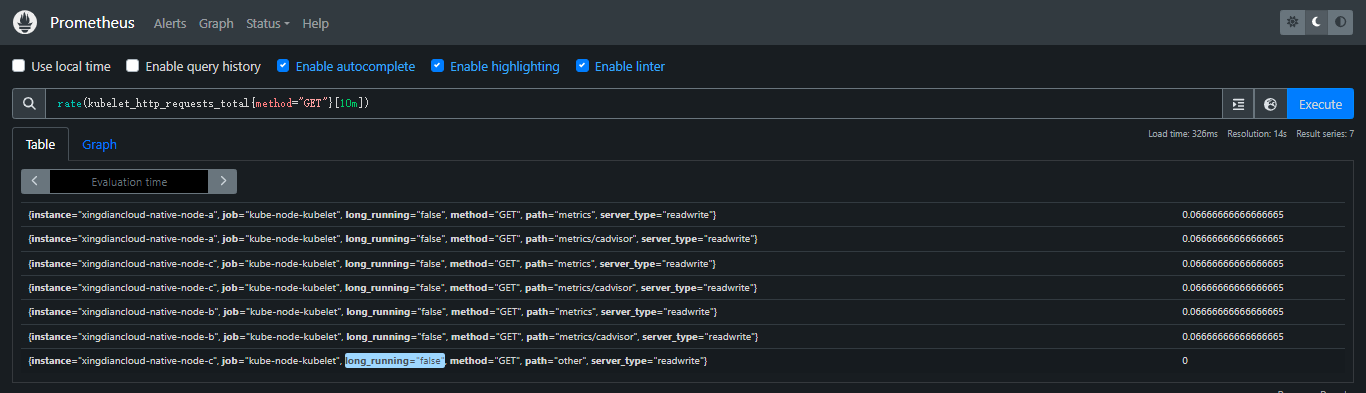
如果 kubelet_http_requests_total 指标包含 code 标签,你可以按状态码分组查看请求速率
rate(kubelet_http_requests_total{code="200"}[5m])
六:企业案例
1.监控Kubernetes集群中数据库MYSQL应用
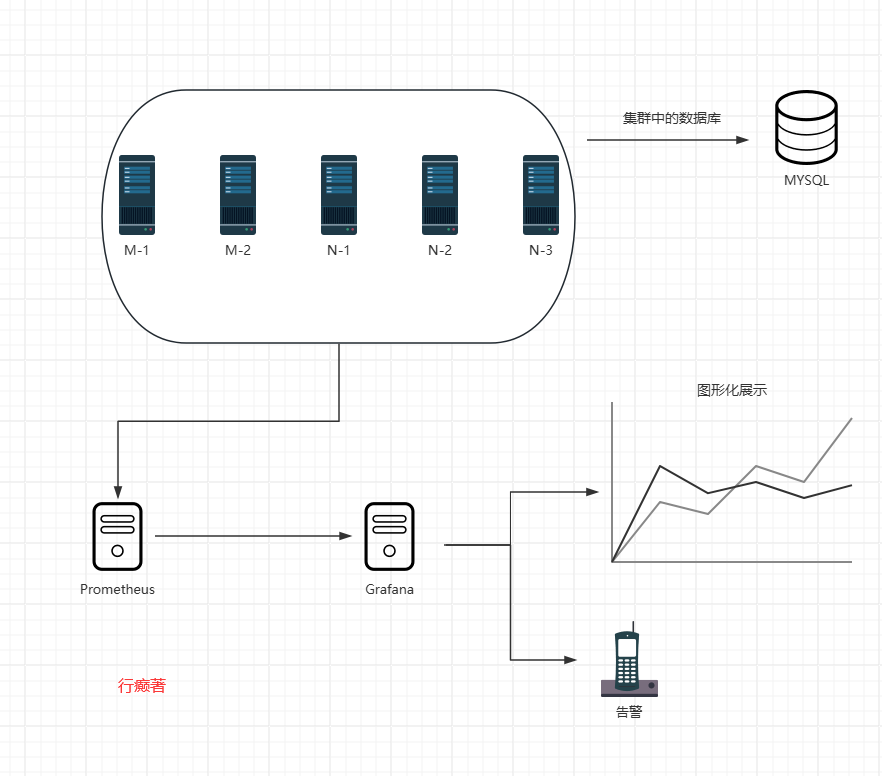
在现代应用中,MySQL数据库的性能和稳定性对业务至关重要;有效的监控可以帮助预防问题并优化性能;Prometheus作为一款强大的开源监控系统,结合Grafana的可视化能力,可以提供全面的MySQL监控方案
集群架构
部署Mysql-exporter
部署方式
部署在Kubernetes集群内部(采用)
基于物理服务器单独部署
简介
MySQL Exporter 是一个专门用于从 MySQL 数据库收集性能和运行状况指标,并提供给Prometheus的工具
帮助用户监控 MySQL 数据库的各种指标,如查询性能、连接数、缓存命中率、慢查询等
功能
收集 MySQL 服务器的全局状态、InnoDB 状态、表和索引统计信息等
收集与性能相关的指标,如查询执行时间、连接数、缓存使用情况等
支持自定义查询,用户可以定义自己的查询以收集特定指标
MySQL Exporter 将收集到的指标以 Prometheus 可读的格式暴露出来,供 Prometheus 抓取
提供了丰富的指标标签,便于在 Prometheus 中进行查询和分析
常见 MySQL Exporter 指标
mysql_global_status_uptime: MySQL 服务器的运行时间
mysql_global_status_threads_connected: 当前连接的线程数
mysql_global_status_threads_connected: 当前连接的线程数
mysql_global_status_slow_queries: 慢查询的数量
mysql_global_status_queries: 总查询数
安装部署
前提:Kubernetes集群正常运行,本次安装在Kubernetes集群内部,对应的yaml文件如下
[root@xingdiancloud-master mysql-exporter]# cat mysql-exporter.yaml
apiVersion: v1
kind: Secret
metadata:
name: mysql-exporter-secret
type: Opaque
data:
mysql_user: cm9vdA== # base64 encoded value of your MySQL username
mysql_password: MTIzNDU2 # base64 encoded value of your MySQL password
---
apiVersion: v1
kind: Service
metadata:
name: mysql-exporter-service
labels:
app: mysql-exporter
spec:
type: NodePort
ports:
- name: mysql-exporter
port: 9104
targetPort: 9104
nodePort: 30182
selector:
app: mysql-exporter
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: mysql-exporter
spec:
selector:
matchLabels:
app: mysql-exporter
template:
metadata:
labels:
app: mysql-exporter
spec:
containers:
- name: mysql-exporter
#image: prom/mysqld-exporter
image: 10.9.12.201/xingdian/mysql-exporter
env:
- name: DATA_SOURCE_NAME
value: "root:123456@(10.9.12.206:30180)/"
- name: DATA_SOURCE_PASS
valueFrom:
secretKeyRef:
name: mysql-exporter-secret
key: mysql_password
ports:
- containerPort: 9104
[root@xingdiancloud-master mysql-exporter]# kubectl create -f mysql-exporter.yaml
关联Prometheus
前提:Prometheus已经安装完成并正常运行,参考第二部分,配置文件如下
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'xingdiancloud-mysql-exporter'
scrape_interval: 15s
static_configs:
- targets: ['10.9.12.206:30182']
案例
注意:
所有案例最终将在Grafana中进行展示和分析
监控总查询数
数据源已添加完成
创建Dashboard
添加图标
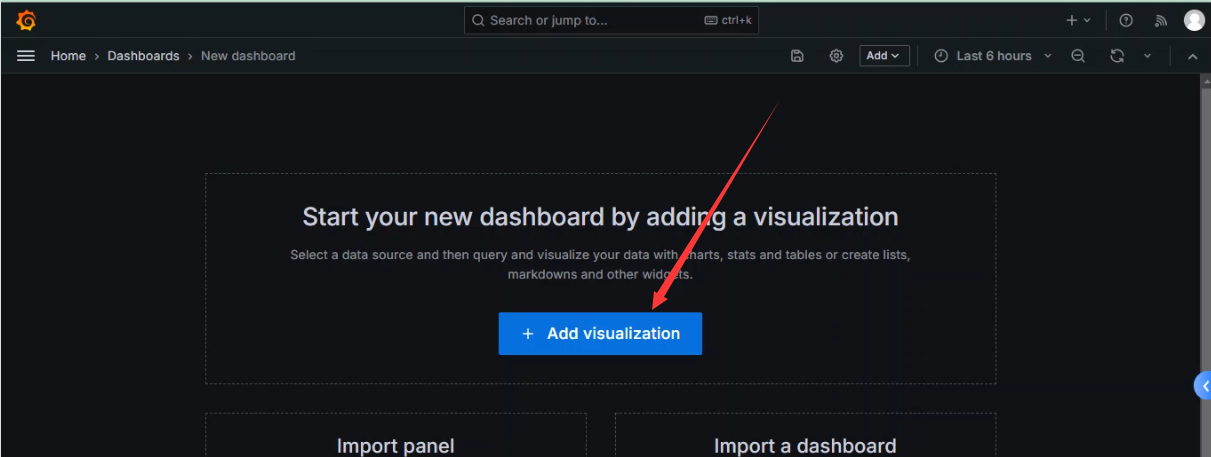
选择数据源
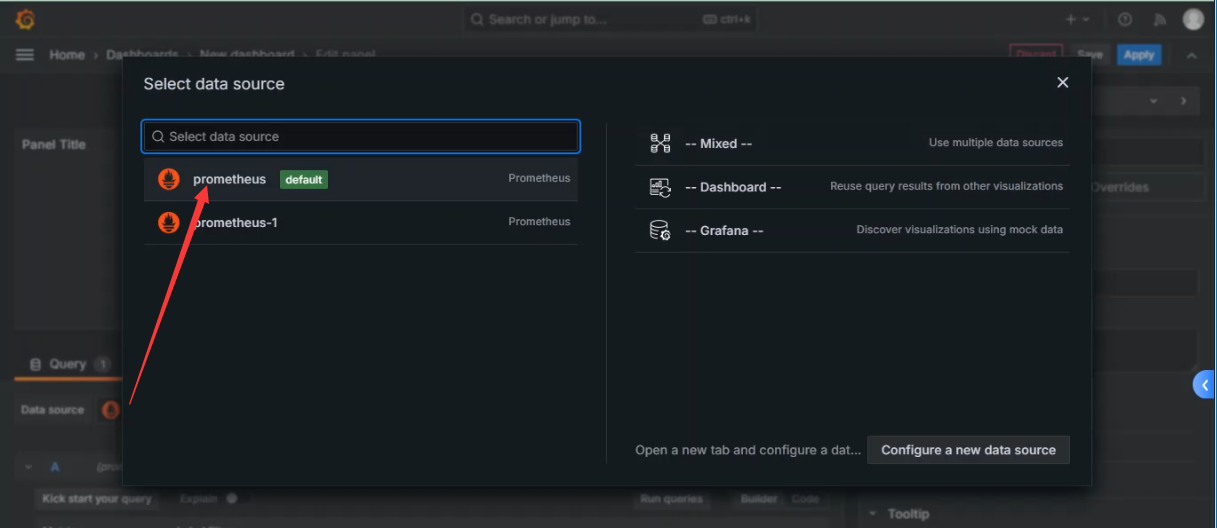
选择指标
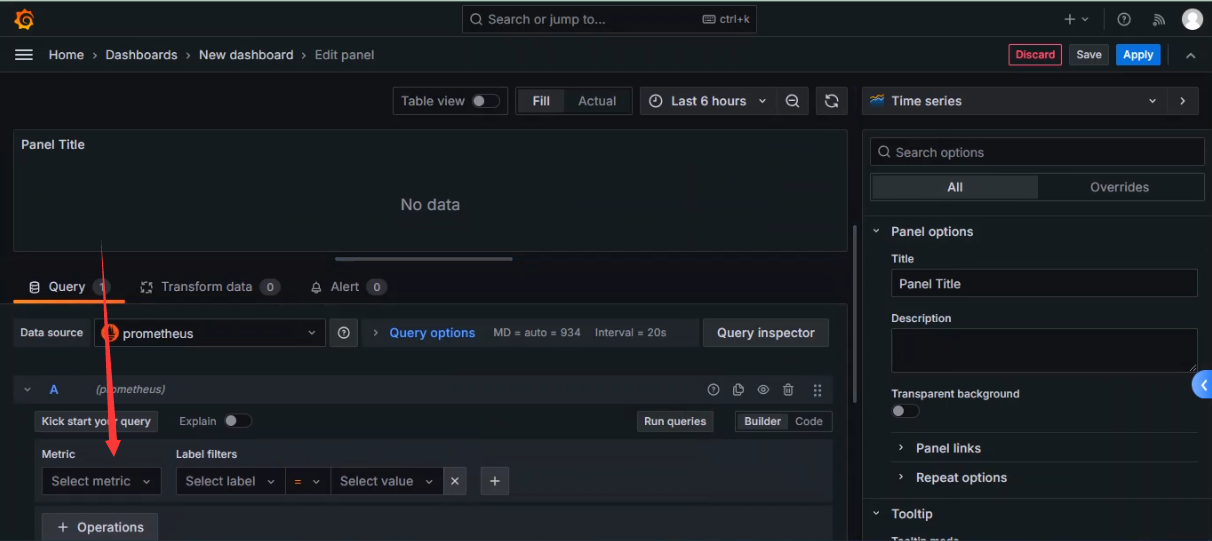
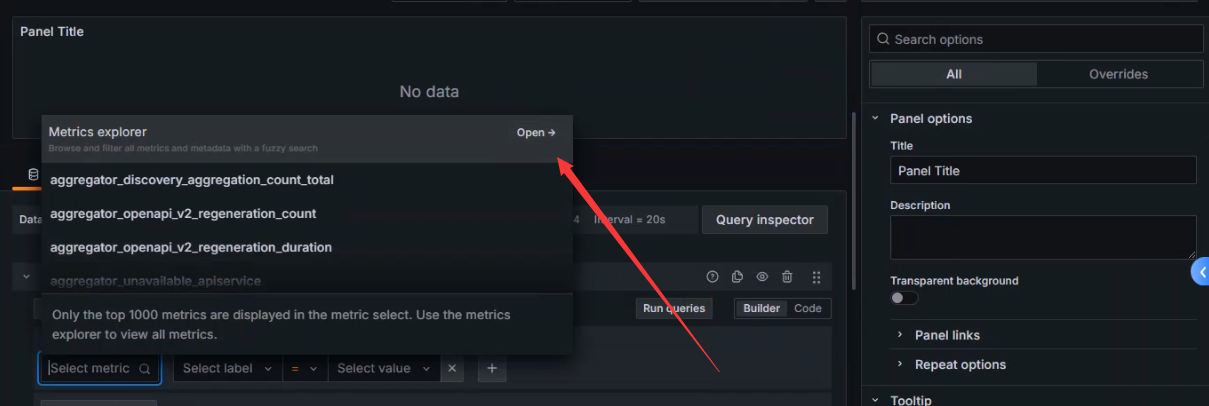
选择总查询数指标
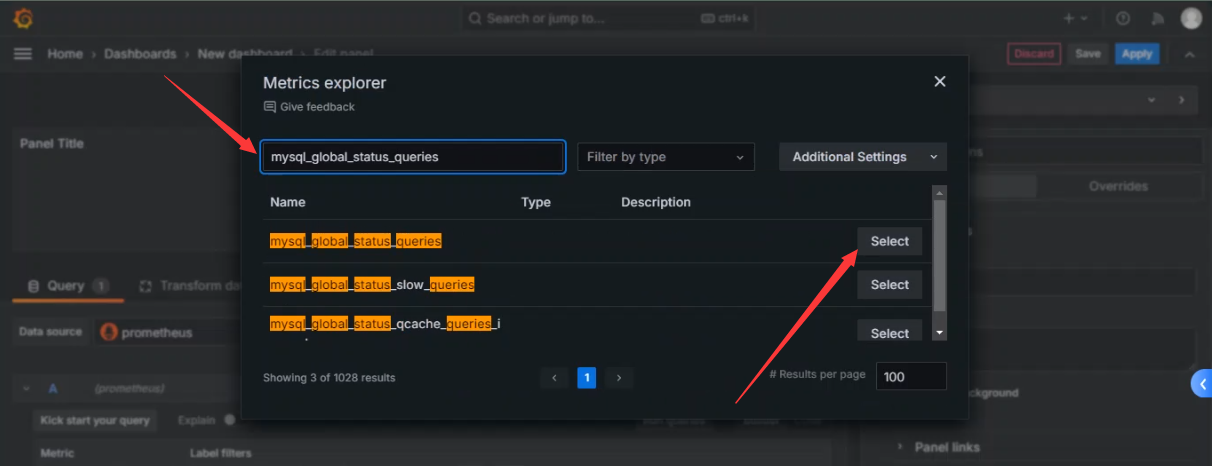
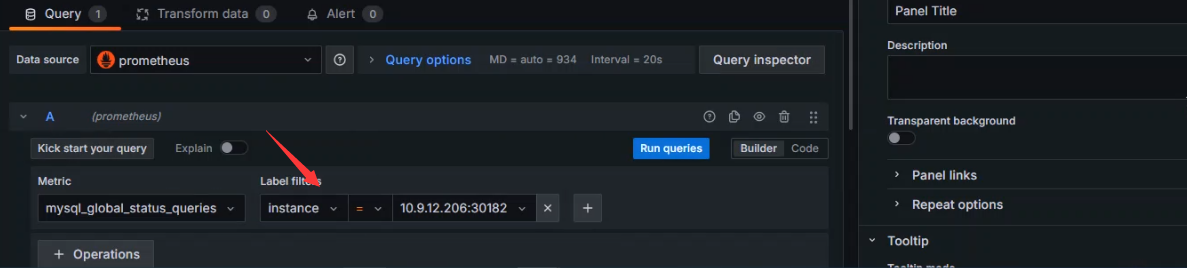
标签过滤,如果监控数据库集群,可以使用标签指定对应的数据库主机
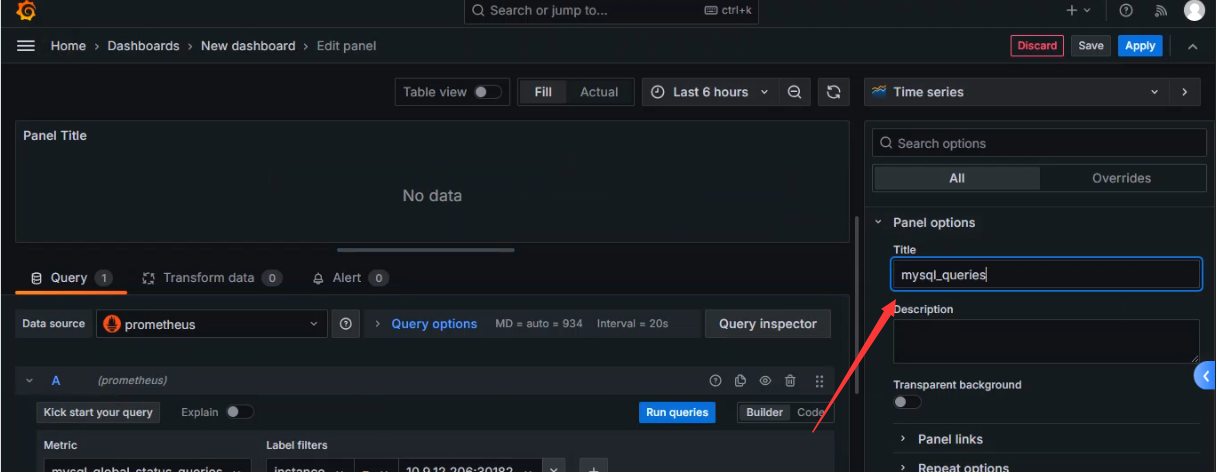
设置图标名字
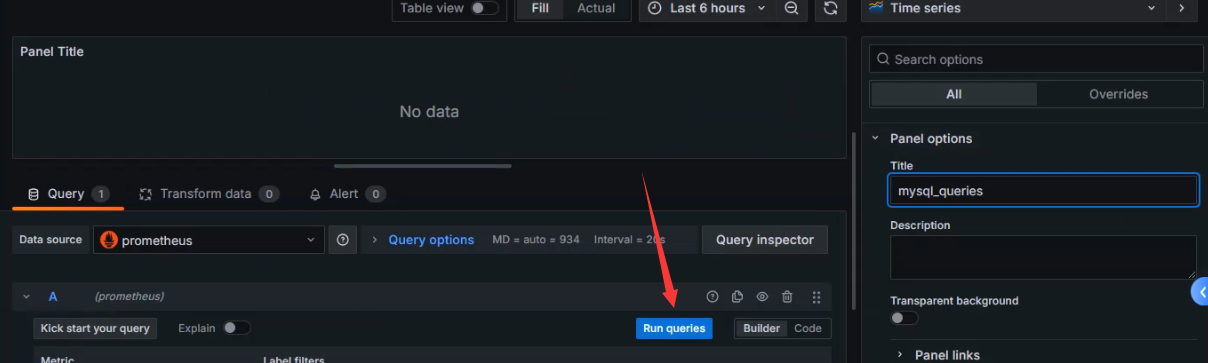
获取数据
查看数据
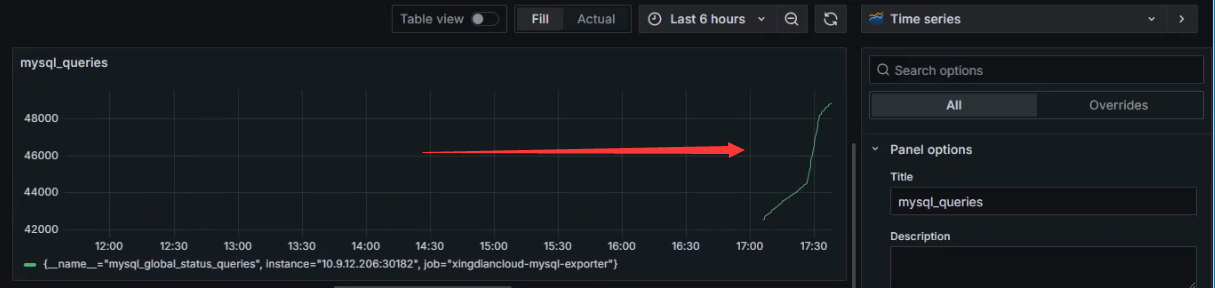
保存并应用
监控 MySQL 中 TPS 的指标
TPS代表每秒事务数
MySQL 的 TPS 指标主要通过以下状态变量来衡量
mysql_global_status_commands_total: 提交事务的次数
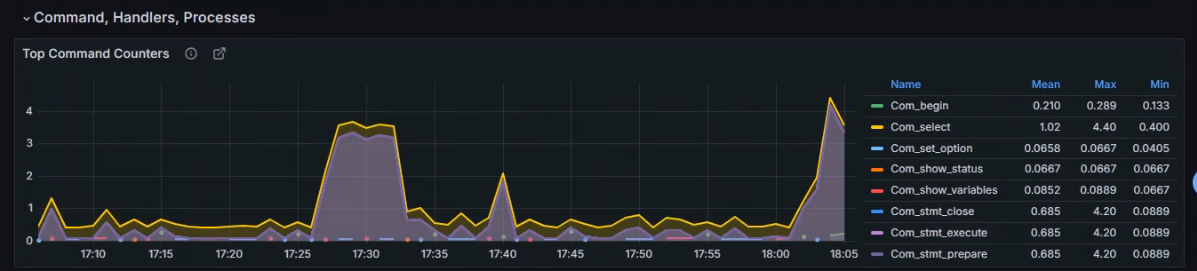
具体来说,mysql_global_status_commands_total 包含了以下几种命令的执行次数统计:
com_select: 查询操作的次数com_insert: 插入操作的次数com_update: 更新操作的次数com_delete: 删除操作的次数com_replace: 替换操作的次数com_load: 加载数据操作的次数com_commit: 提交事务的次数com_rollback: 回滚事务的次数com_prepare_sql: 准备 SQL 语句的次数com_stmt_execute: 执行 SQL 语句的次数com_stmt_prepare: 准备 SQL 语句的次数com_stmt_close: 关闭 SQL 语句的次数com_stmt_reset: 重置 SQL 语句的次数
添加数据源
略
创建Dashboard
略
创建图标
略
设置指标
选择指标:mysql_global_status_commands_total
使用函数:rate()
时间范围:5m
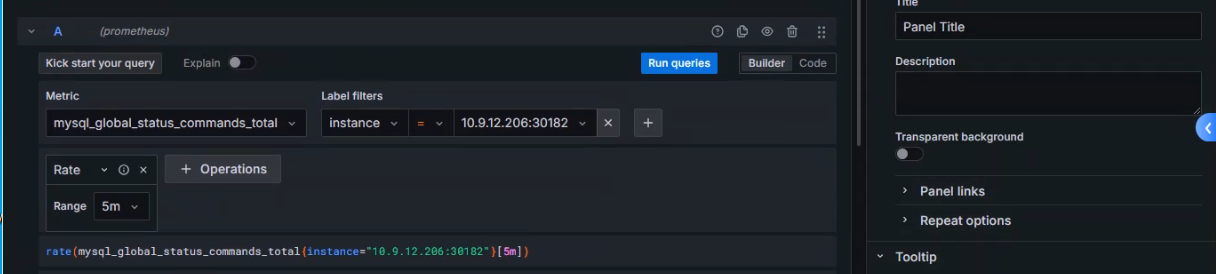
查询数据
略
设置图标名称
略
数据展示
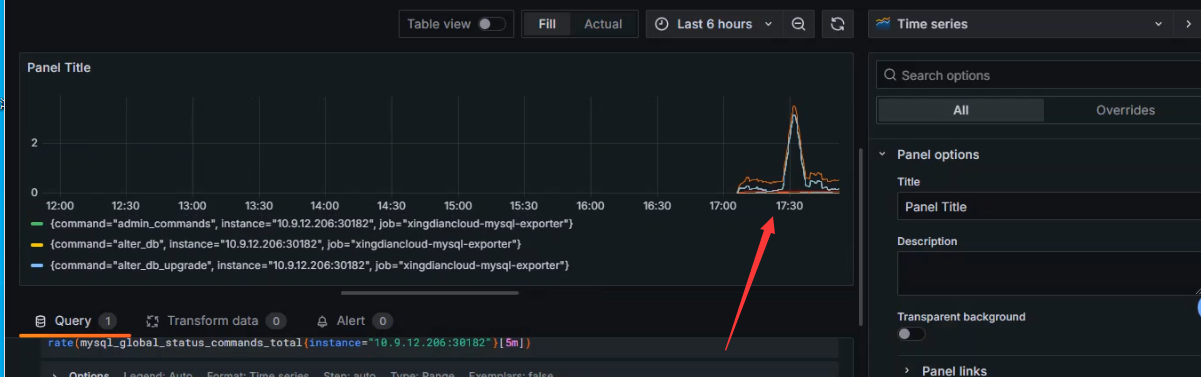
管理员执行的操作的TPS
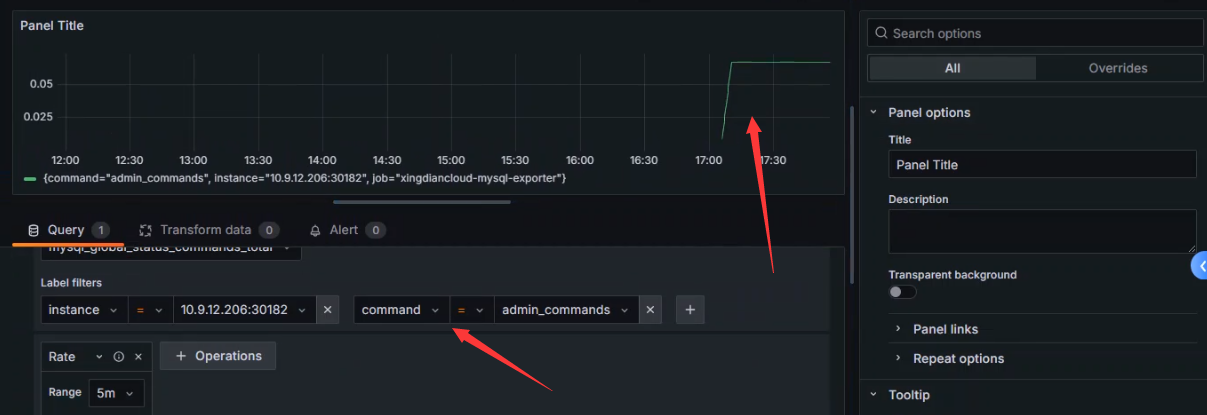
扩展该指标的command
mysql_global_status_commands_total 中的 command 标签代表了 MySQL 数据库执行的不同类型的命令,这些命令涵盖了数据库的各个方面,包括管理、查询、事务等
admin_commands: 管理命令,涉及数据库服务器的管理操作,如用户管理、权限管理等
user_commands: 用户命令,用户发起的数据库操作命令,如查询、更新等
delete: DELETE 操作的次数
insert: INSERT 操作的次数
update: UPDATE 操作的次数
select: SELECT 操作的次数
commit: 事务提交的次数
rollback: 事务回滚的次数
create_db: 创建数据库的次数
drop_db: 删除数据库的次数
create_table: 创建表的次数
drop_table: 删除表的次数
alter_table: 修改表结构的次数
set: 执行 SET 命令的次数
show: 执行 SHOW 命令的次数
.....
Grafana模板监控
获取模板地址:https://grafana.com/grafana/dashboards/14057-mysql/
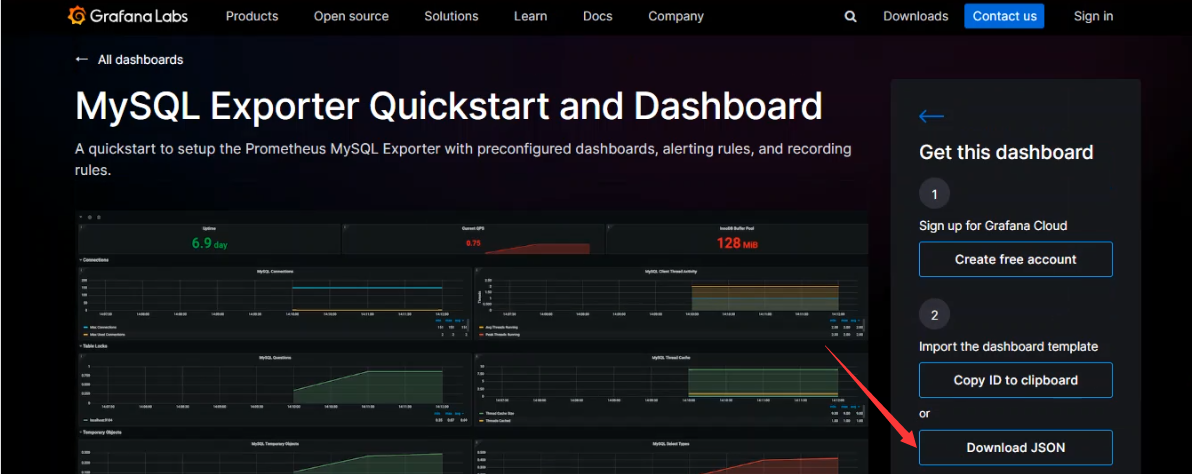
Grafana导入模板
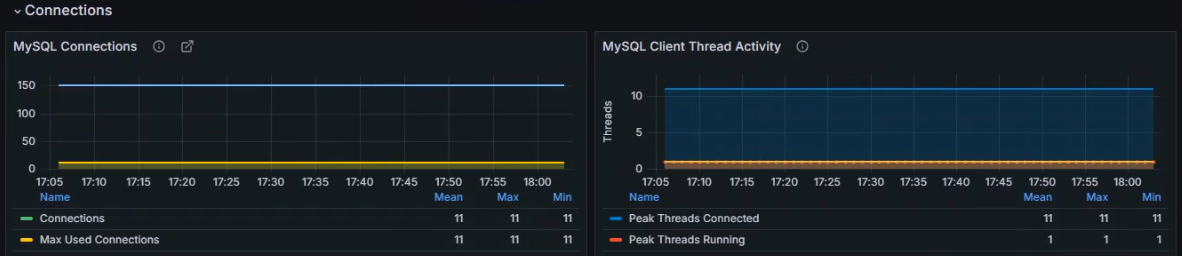
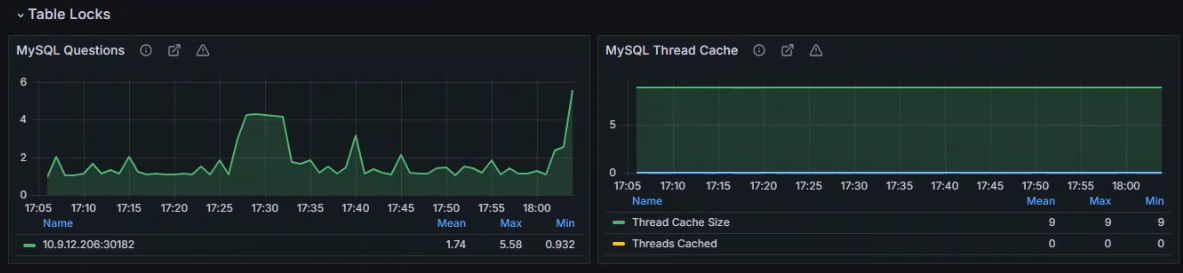
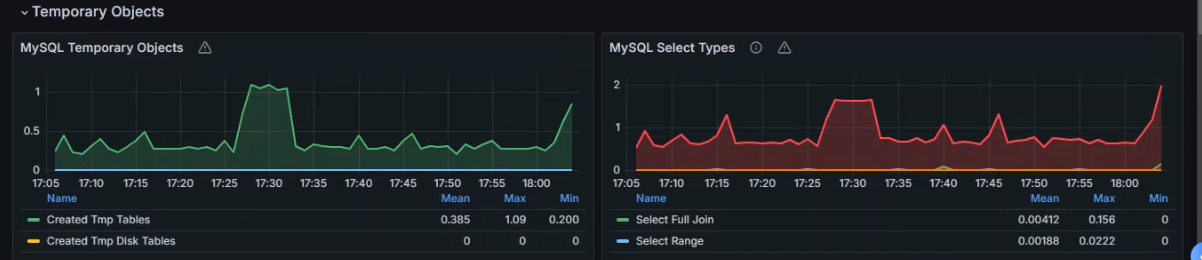
数据展示

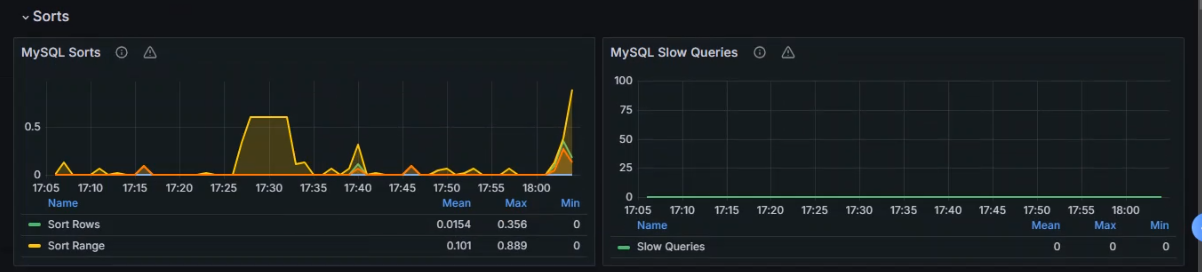
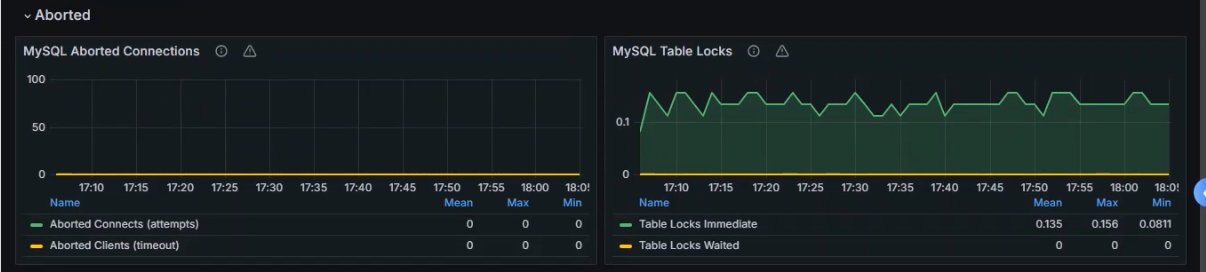
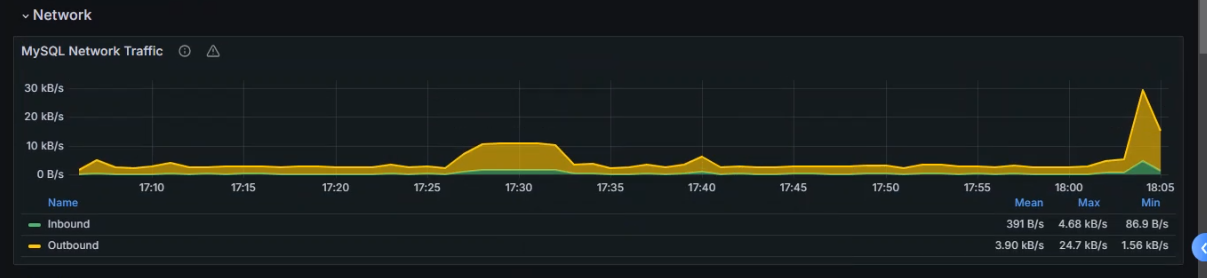
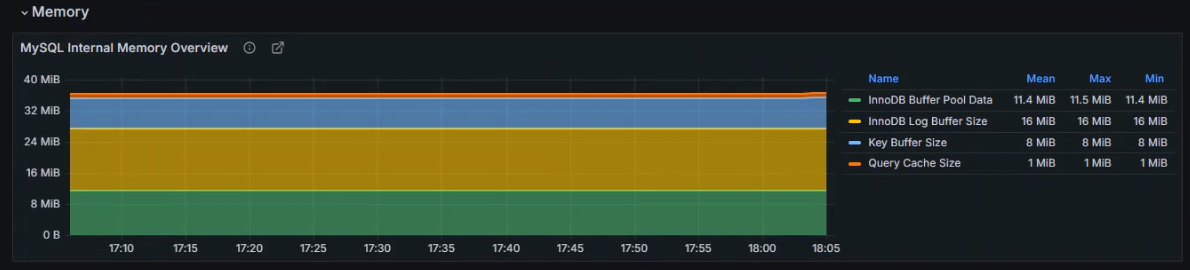

2.监控Kubernetes集群
集群架构
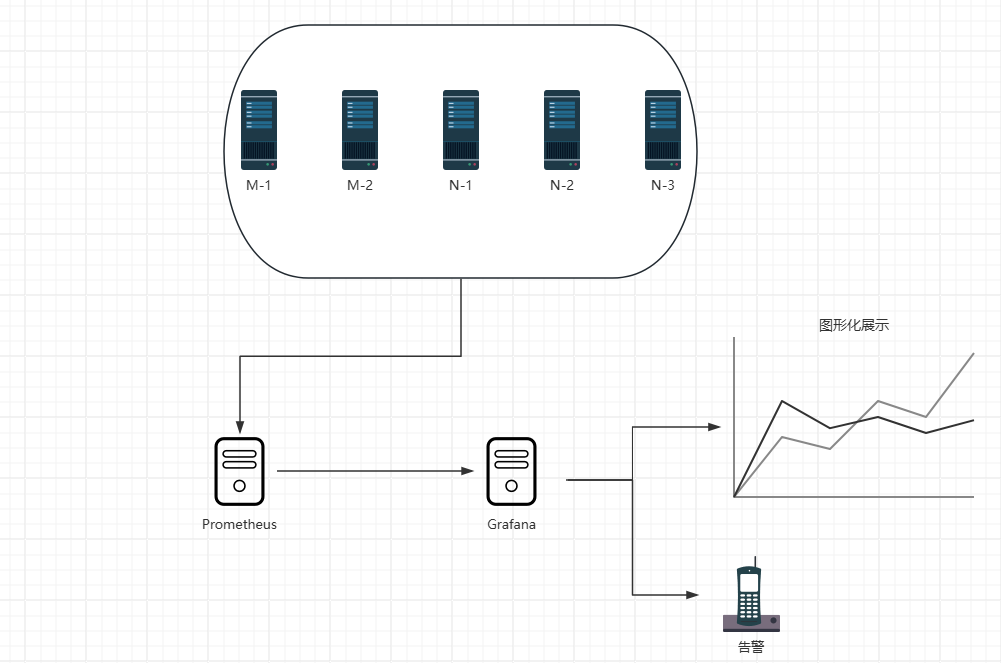
部署采集器
简介
Node Exporter是安装在Kubernetes集群中采集器
可以定期收集系统资源使用情况并将其暴露给 Prometheus 或其他监控系统
其主要功能包括收集 CPU、内存、磁盘、网络等系统指标
帮助管理员和开发人员了解 Kubernetes 集群的健康状况、资源利用率和性能指标
部署
略;见本文章的第二部分
常见指标
注意:指标名字可能会有所差别但是其原理不变
kubelet 相关指标
kubelet_running_pod_count: 当前运行的 Pod 数量
kubelet_running_containers: 当前运行的容器数量
kubelet_volume_stats_used_bytes: 使用的卷存储字节数
kubelet_volume_stats_available_bytes: 可用的卷存储字节数
kube-state-metrics 提供的指标
kube_deployment_status_replicas_available: 可用的部署副本数
kube_node_status_capacity_cpu_cores: 节点的 CPU 核心容量
kube_node_status_capacity_memory_bytes: 节点的内存容量
Kubernetes API Server 相关指标
apiserver_request_count: API 请求计数
apiserver_request_latencies: API 请求的延迟
Etcd 相关指标
etcd_server_has_leader: 是否存在 Etcd 集群的领导者
etcd_server_storage_db_size_bytes: Etcd 存储的数据库大小Etcd 相关指标
案例
集群中所有容器在该时间窗口内的总 CPU 使用率
添加数据源
略
创建Dashboard
略
创建图标
略
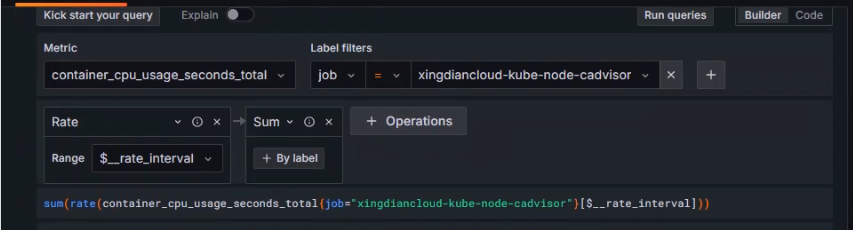
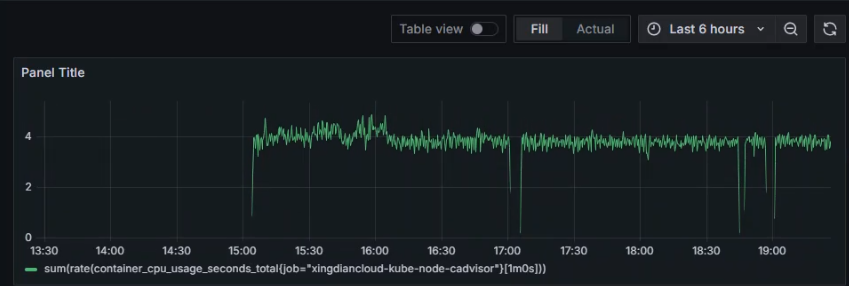
设置指标
选择指标:container_cpu_usage_seconds_total
使用函数:rate()
时间范围:[$__rate_interval]
使用函数:sum()
表达式为
sum(rate(container_cpu_usage_seconds_total[$__rate_interval]))
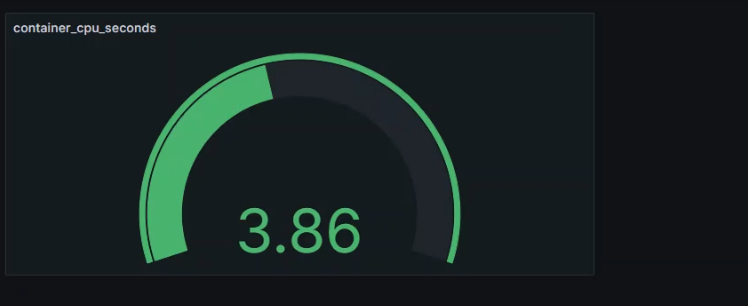
数据展示
集群某节点 CPU 核心在指定时间间隔内的空闲时间速率
添加数据源
略
创建Dashboard
略
创建图标
略
设置指标
sum by(cpu) (rate(node_cpu_seconds_total{job="xingdiancloud-kubernetes-nodes", instance="10.9.12.203:9100", mode="idle"}[$__rate_interval]))
指标解释
rate(node_cpu_seconds_total{...}[$__rate_interval]):
rate函数计算在指定时间间隔($__rate_interval)内时间序列的每秒平均增长率。node_cpu_seconds_total{...}过滤node_cpu_seconds_total指标,使其只包括以下标签:job="xingdiancloud-kubernetes-nodes":指定 Prometheus 监控任务的名称instance="10.9.12.203:9100":指定特定节点的实例地址。mode="idle":指定 CPU 模式为idle,即空闲时间
sum by(cpu) (...):
sum by(cpu)汇总计算结果,按cpu标签分组- 这意味着它会计算每个 CPU 核心的空闲时间速率
综上所述,这段查询语句的功能是:
- 计算特定节点(
10.9.12.203:9100)上每个 CPU 核心在指定时间间隔内的空闲时间速率 - 结果按 CPU 核心进行分组和汇总
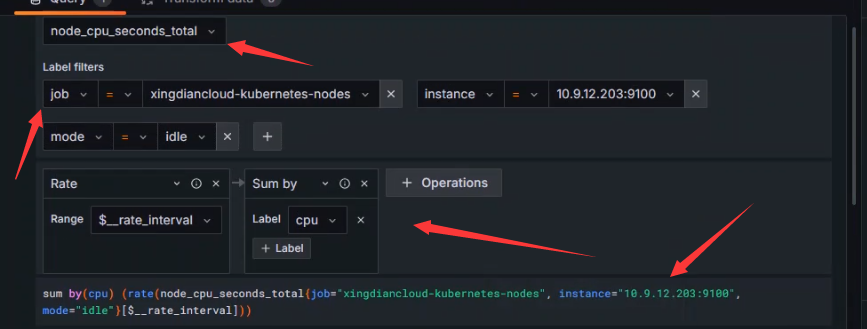
数据展示

七:Grafana监控告警
1.监控简介
Grafana能够将监控数据和告警配置集成到同一个界面中,便于用户一站式管理和查看监控数据及其相关告警
Grafana支持多种通知方式,如邮件、Slack、Webhook等,可以根据不同的情况选择合适的通知方式
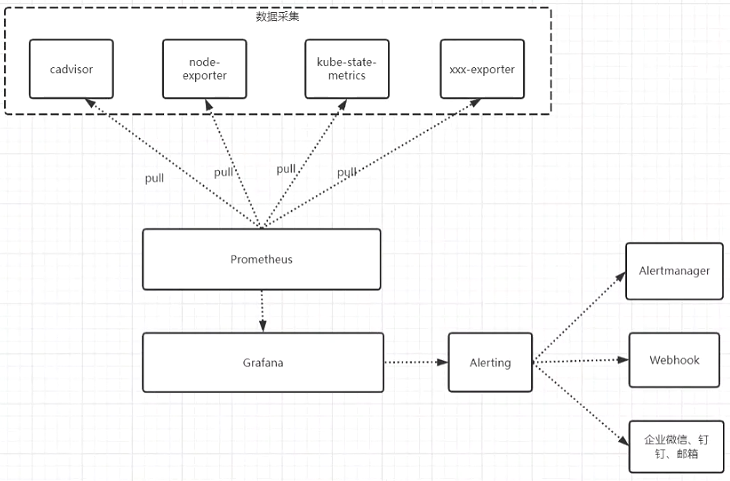
2.监控架构
3.Grafana Alerting
除了Prometheus的AlertManager可以发送报警,Grafana Alerting同时也支持
Grafana Alerting可以无缝定义告警在数据中的位置,可视化的定义阈值,通过钉钉、email等获取告警通知
可直观的定义告警规则,不断的评估并发送通知
4.原理图
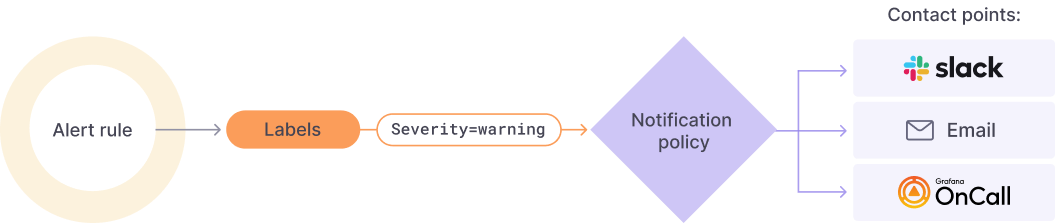
Alert rule :设置确定警报实例是否会触发的评估标准;警报规则由一个或多个查询和表达式、条件、评估频率以及满足条件的持续时间(可选)组成
Labels:将警报规则及其实例与通知策略和静默相匹配;它们还可用于按严重性对警报进行分组
Notification policy:设置警报的发送地点、时间和方式;每个通知策略指定一组标签匹配器来指示它们负责哪些警报;通知策略具有分配给它的由一个或多个通知者组成的联系点
Contact points:定义触发警报时如何通知您的联系人;我们支持多种 ChatOps 工具,确保您的团队收到警报
5.配置关联邮箱
修改Grafana配置文件
[root@grafana grafana]# vim conf/defaults.ini
[smtp]
enabled = true 启用SMTP邮件发送 false:禁用SMTP邮件发送
host = smtp.163.com:25 SMTP服务器的主机名和端口
user = zhuangyaovip@163.com 用于身份验证的SMTP用户名,对应的邮箱地址
password = MYNCREJBMRFBV*** 授权密码
cert_file = 用于TLS/SSL连接的证书文件路径;如果不使用证书文件,可以留空
key_file = 用于TLS/SSL连接的私钥文件路径;如果不使用私钥文件,可以留空
skip_verify = true 是否跳过对SMTP服务器证书的验证;false:验证服务器证书;true:跳过验证
from_address = zhuangyaovip@163.com 发送邮件时的发件人地址
from_name = Grafana 发送邮件时的发件人名称
ehlo_identity = 用于EHLO命令的标识符,可以留空,默认使用Grafana服务器的主机名
startTLS_policy = 指定STARTTLS的策略,可选值包括:always, never, optional。默认是optional,即如果SMTP服务器支持STARTTLS就使用
enable_tracing = false 是否启用SMTP通信的调试跟踪;true:启用调试跟踪,false:禁用调试跟踪
重启服务
[root@grafana grafana]# nohup ./bin/grafana-server --config ./conf/defaults.ini &
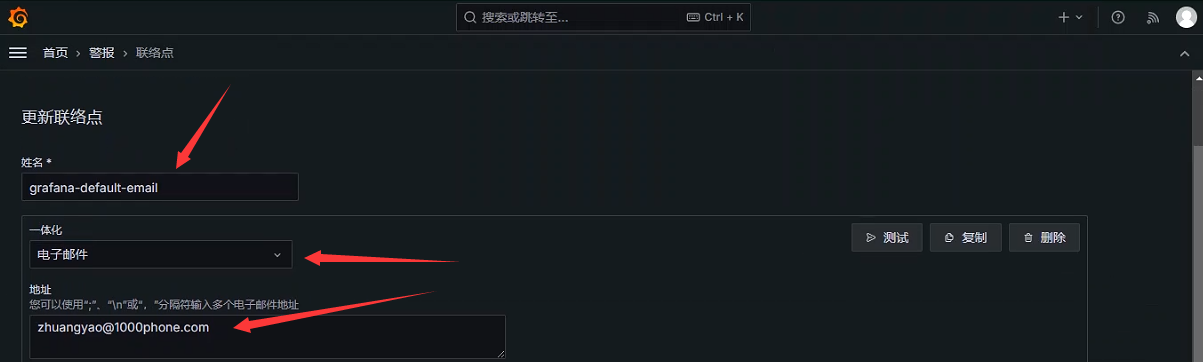
配置联络点
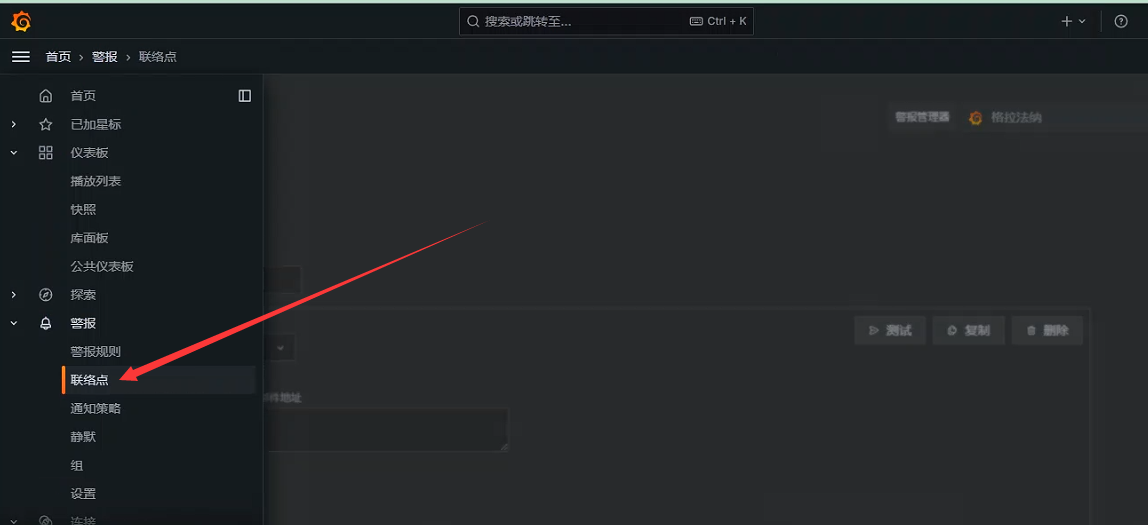
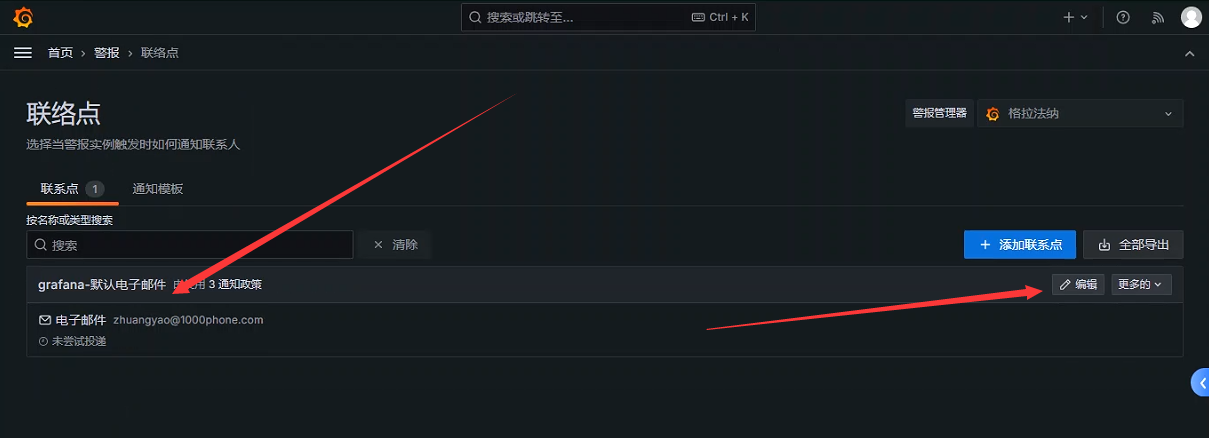
指定联络点名称,收件人地址
配置信息模板和主题模板

测试是否可用
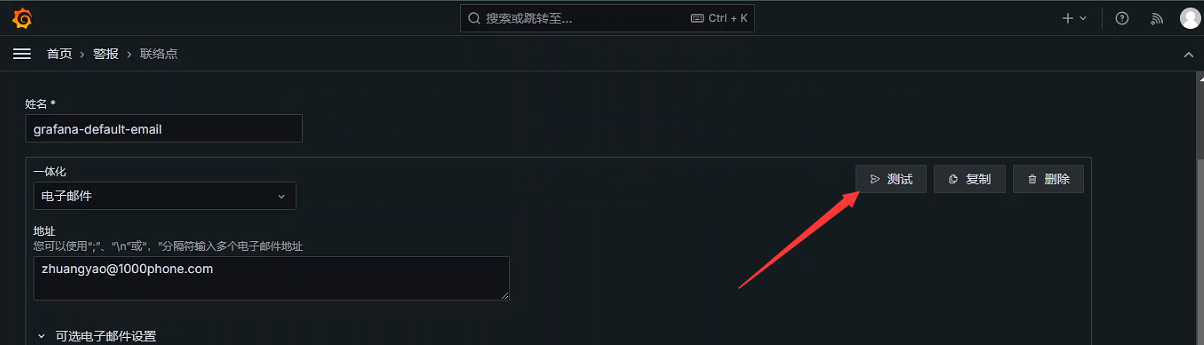
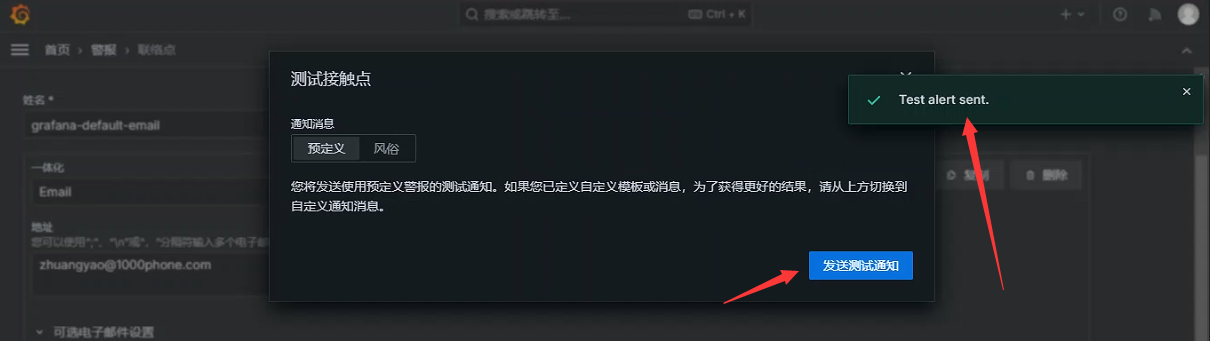
收件人确认
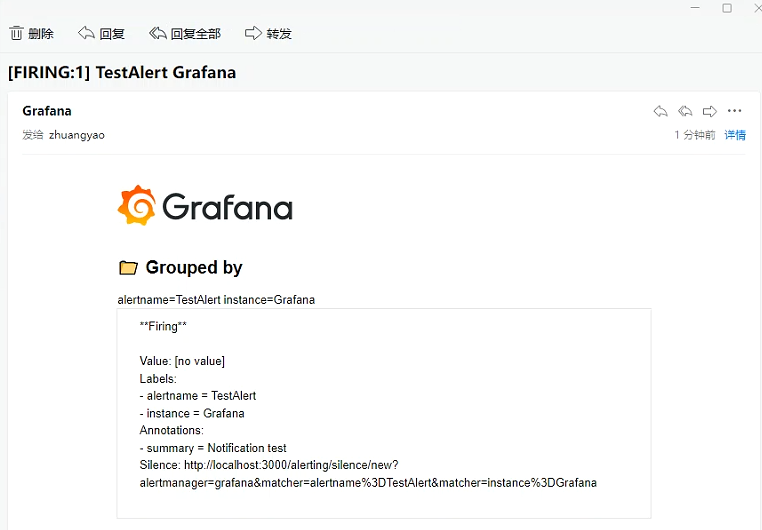
至此,邮箱配置成功
6.通知策略
作用
确定警报如何路由到联络点
配置
系统自带默认策略:如果没有找到其他匹配的策略,所有警报实例将由默认策略处理
7.配置使用
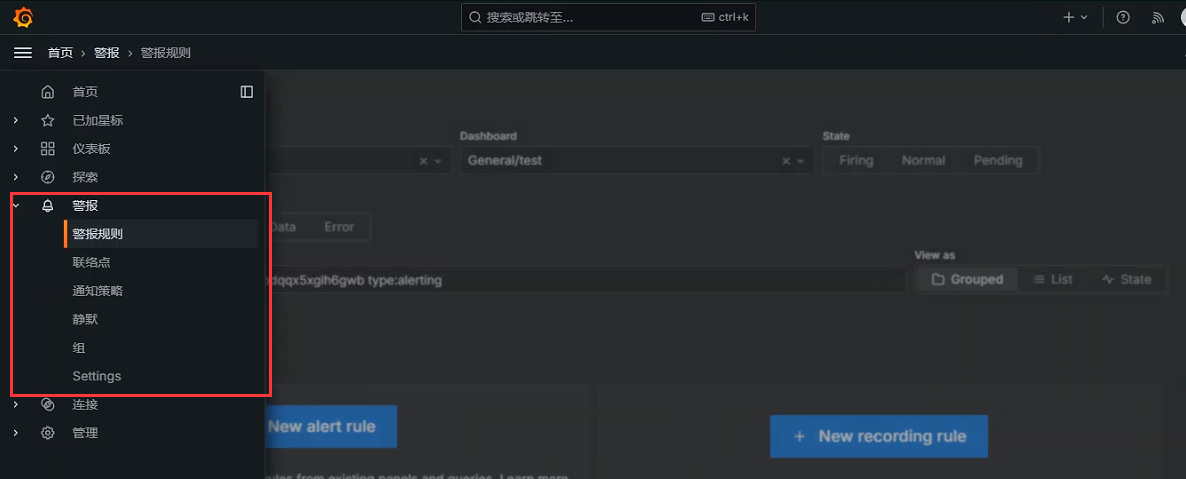
查看警报规则
关联数据源和Dashboard

告警规则(Alert rules)
- 告警规则是一组评估标准,用于确定告警实例是否会触发。该规则由一个或多个查询和表达式、一个条件、评估频率以及满足条件的持续时间(可选)组成
- 在查询和表达式选择要评估的数据集时,条件会设置告警必须达到或超过才能创建警报的阈值
- 间隔指定评估警报规则的频率。持续时间在配置时表示必须满足条件的时间。告警规则还可以定义没有数据时的告警行为
告警规则状态(Alert rule state)
| 状态 | 描述 |
|---|---|
| Normal | 评估引擎返回的时间序列都不是处于Pending 或者 Firing状态 |
| Pending | 评估引擎返回的至少一个时间序列是Pending |
| Firing | 评估引擎返回的至少一个时间序列是Firing |
告警规则运行状况(Alert rule health)
| 状态 | 描述 |
|---|---|
| Ok | 评估告警规则时没有错误 |
| Error | 评估告警规则时没有错误 |
| NoData | 在规则评估期间返回的至少一个时间序列中缺少数据 |
告警实例状态(Alert instance state)
| 状态 | 描述 |
|---|---|
| Normal | 既未触发也未挂起的告警状态,一切正常 |
| Pending | 已激活的告警状态少于配置的阈值持续时间 |
| Alerting | 已激活超过配置的阈值持续时间的告警的状态 |
| NoData | 在配置的时间窗口内未收到任何数据 |
| Error | 尝试评估告警规则时发生的错误 |
New alert rule
Enter alert rule name

Define query and alert condition
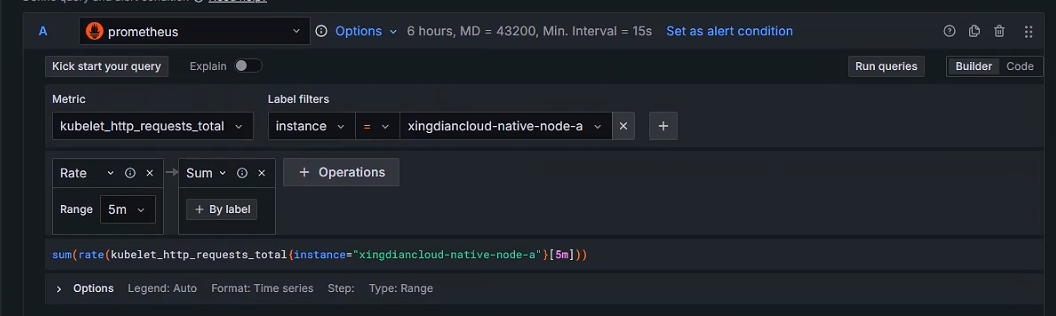
Rule type

Expressions
表达式
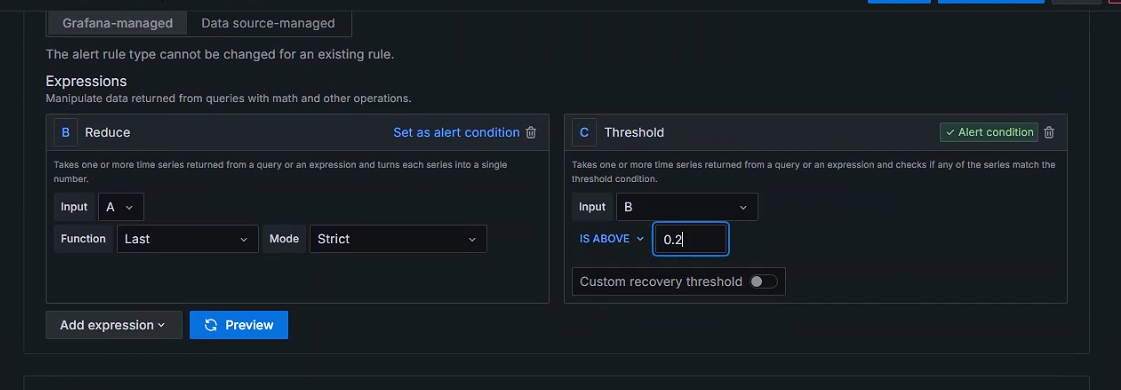
将Reduce(减少)的Function选为最后一个值
将Threshold(临界点)的IS ABOVE的值设置为会触发的值,模拟报警产生
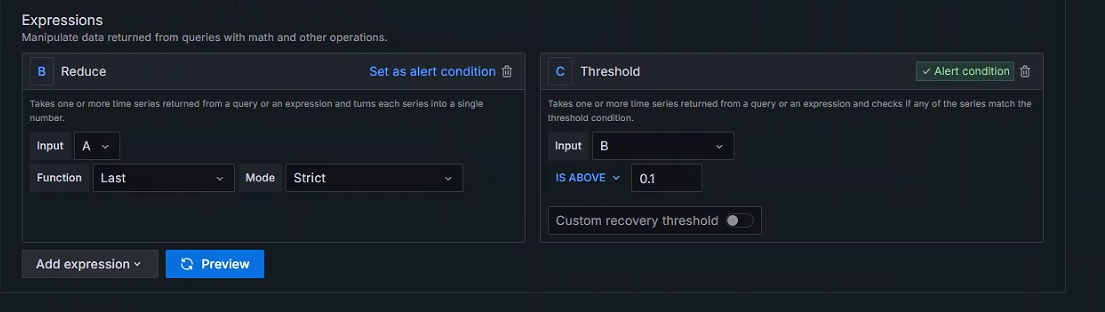
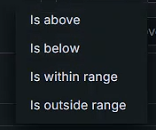
临界点参数:
IS ABOVE:高于
IS BELOW:在下面,低于
IS WITHIN RANGE:在范围内
IS OUTSIDE RANGE:超出范围
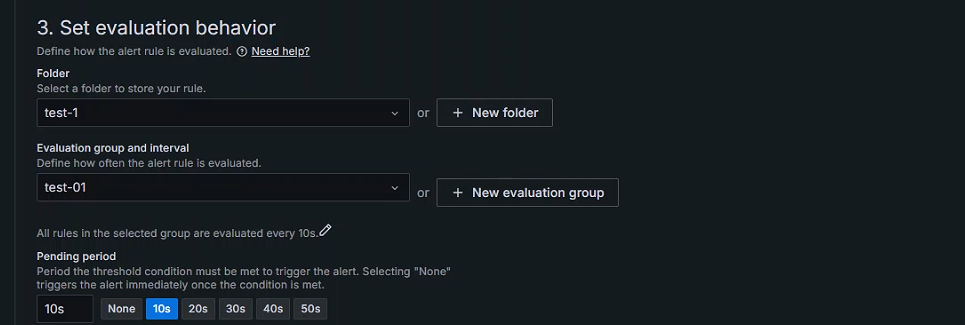
Set evaluation behavior
定义如何评估警报规则
选择文件夹存储规则,文件夹不存在需要自行创建
定义评估警报规则的频率
触发警报的阈值条件必须满足的时间段;选择“无”会在满足条件后立即触发警报
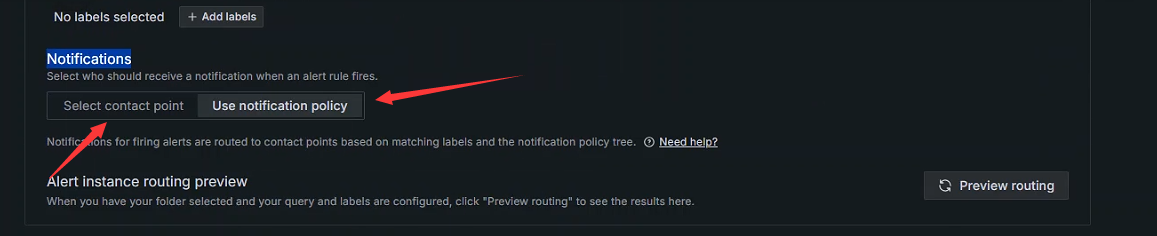
Notifications
选择当警报规则触发时应该如何接收通知
选择联络点:直接将告警信息发送给对应的接收者
使用通知策略:触发警报的通知会根据匹配的标签和通知策略树路由到联络者
使用通知策略

使用联络点
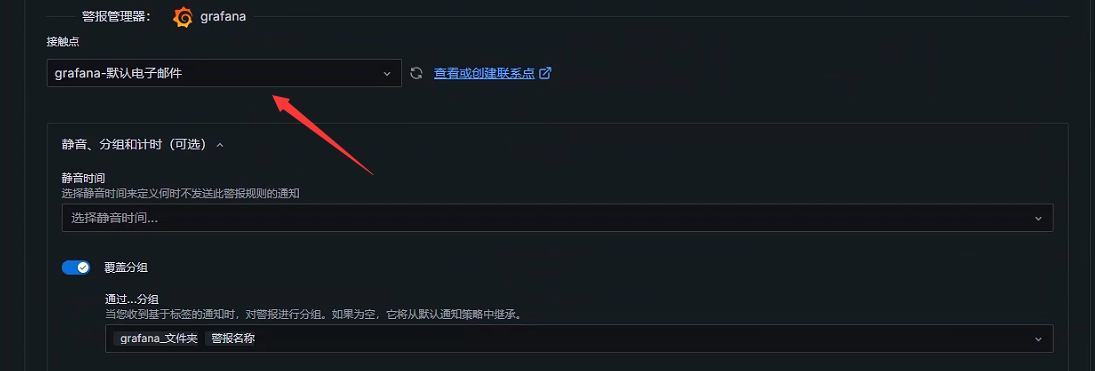
保存规则
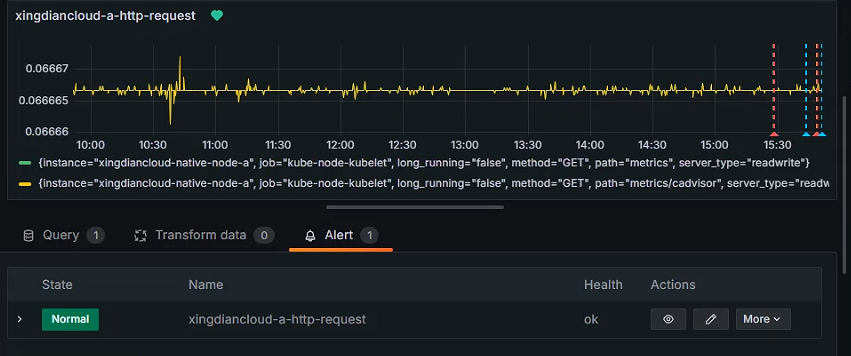
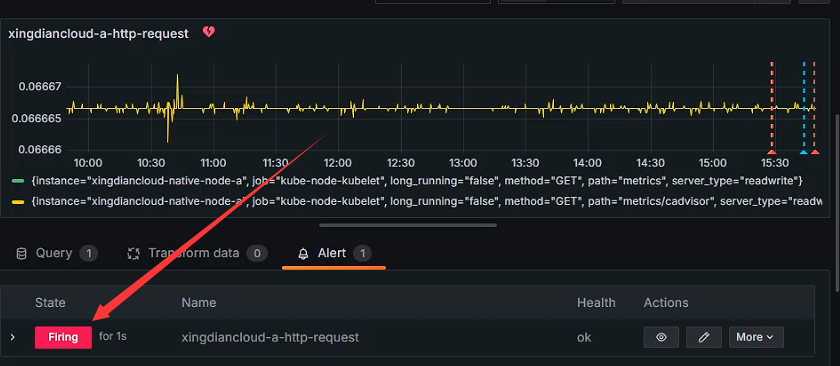
查看状态
状态为Firing 意为触发了告警
查看是否接收到邮件
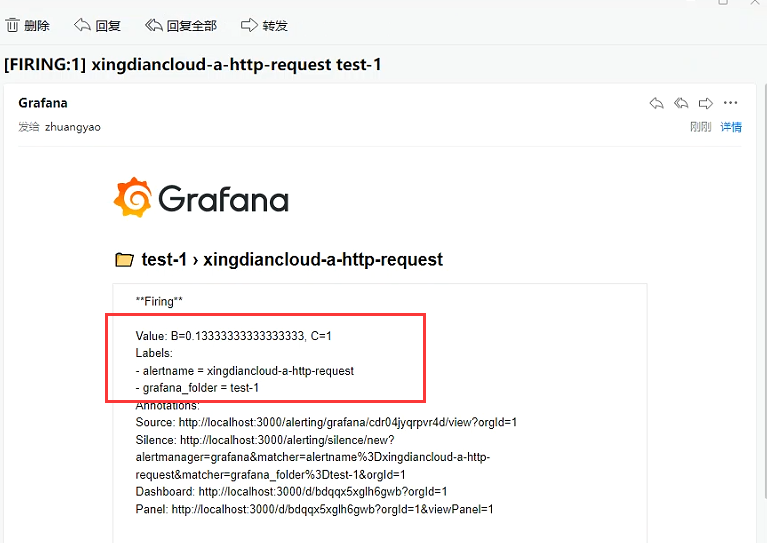
邮箱告警成功
修改临界点值回复正常状态