上传文件至 'MD'
This commit is contained in:
parent
68287a73b9
commit
f6ad89118c
1284
MD/3、Python 3.md
Normal file
1284
MD/3、Python 3.md
Normal file
File diff suppressed because it is too large
Load Diff
642
MD/4、Python 4.md
Normal file
642
MD/4、Python 4.md
Normal file
@ -0,0 +1,642 @@
|
||||
## 十五、面向对象编程介绍
|
||||
|
||||
### 1、什么是对象和类OOP
|
||||
|
||||
#### 1、从现实世界说起
|
||||
|
||||
##### a、什么是对象
|
||||
|
||||
现实世界中,任何一个可见,可触及的物体都可以成为对象。
|
||||
|
||||
比如说一辆汽车,一个人,都可以称为对象。
|
||||
|
||||
那每个对象都是有属性和功能(或者说技能)的。
|
||||
比如:
|
||||
一辆汽车的属性有:
|
||||
|
||||
> - 重量
|
||||
> - 具体的大小尺寸
|
||||
> - 车身颜色
|
||||
> - 价格
|
||||
|
||||
一辆汽车的功能有:
|
||||
|
||||
> - 行驶
|
||||
> - 载人
|
||||
|
||||
##### b、什么是类
|
||||
|
||||
什么又是类呢?
|
||||
|
||||
听人们常说,**物以类聚,人以群分**。
|
||||
|
||||
从字里行间不难看出,类就是具体很多对象共有属性和共有功能的抽象体。
|
||||
|
||||
这个抽象体,只是一个称谓,代表了具有相同属性和功能的某些对象。
|
||||
|
||||
比如,具体的一辆汽车是一个对象,红色汽车就是这些具有红色车身的汽车的统称,红色汽车就是一个类了。
|
||||
|
||||
相关的例子还有很多,比如 蔬菜是一个类,一个具体的茄子是属于蔬菜这个类的。
|
||||
|
||||
> 现实世界中是先有对象后有类的。
|
||||
|
||||
#### 2、回到计算机的世界
|
||||
|
||||
在计算机的代码中要表示对象的属性就是使用变量名 和数据的绑定方式。
|
||||
如 `color = 'red'`
|
||||
|
||||
那要表示对象的功能(或者说技能),在计算机的代码中是用函数实现的。这里的函数会被称为对象的 `方法`
|
||||
|
||||
计算机世界中是先有类,后有对象的。
|
||||
|
||||
> 就像建造一栋楼房,需要先有图纸,之后按照这个图纸建造房子。
|
||||
> 在计算机语言中,都是先创建一个类,给这个类定义一些属性和方法。之后通过这个类去实例化出一个又一个的对象。
|
||||
|
||||
#### 3、什么是面向对象的编程
|
||||
|
||||
先说编程,个人理解,编程就是利用编程语言书写代码逻辑,来描述一些事件,在这个过程中会涉及到具体对象,具体的条件约束,以及事件的结果。
|
||||
|
||||
比如,现实世界中的一件事,学员学开车。
|
||||
|
||||
这里涉及到的对象有
|
||||
|
||||
- 车
|
||||
- 教练
|
||||
- 学员
|
||||
- 道路
|
||||
|
||||
涉及到的技能有
|
||||
|
||||
- 车 :
|
||||
- 行驶
|
||||
- 教练 :
|
||||
- 开车
|
||||
- 教学员学开车
|
||||
- 学员:
|
||||
- 学习开车
|
||||
|
||||
当然所涉及到的东西,不止上面的这些,这里只是简单举例,表明原理即可。
|
||||
|
||||
假如想表述学员学开车这件事。
|
||||
|
||||
```python
|
||||
学员跟着教练学习开车技能,使用的是绿色吉普汽车,之后他学会了开车。
|
||||
```
|
||||
|
||||
很简单是吧,但是,要在计算机中体现出来该怎么办呢?
|
||||
|
||||
```python
|
||||
1 先定义每个对象的类,在类里定义各自对象的属性和方法
|
||||
|
||||
2 通过类把对象创建处来,这个创建的过程成为实例化,实例化的结果成为这个类的一个实例,当然这个实例也是一个对象,一切皆对象嘛。
|
||||
|
||||
3 利用实例的方法互相作用得到事件单结果。
|
||||
```
|
||||
|
||||
从最后一条不难发现, 每个对象的方法可以和其他对象进行交换作用的,从而也产生了新的结果。
|
||||
|
||||
这种用对象的方法和属性去相互作用来编写代码的逻辑思维或者说是编写代码的风格就是面向对象的编程了。
|
||||
|
||||
面向对象编程 Object Oriented Programming 简称 OOP,是一种程序设计思想。
|
||||
|
||||
OOP把对象作为程序的基本单元,一个对象包含了数据和操作数据的函数。
|
||||
|
||||
面向对象的程序设计是把计算机程序视为一组对象的集合,而且每个对象都可以接收其他对象发过来的消息,并处理这些消息,计算机程序的执行就是一系列消息在各个对象之间传递。这就是对象之间的交互。
|
||||
|
||||
### 2、Python 中一切皆对象
|
||||
|
||||
你可能听说过,在 Python 中一切皆对象。
|
||||
|
||||
在python中,一切皆对象。数字、字符串、元组、列表、字典、函数、方法、类、模块等等都是对象,包括你的代码。
|
||||
|
||||
之前也提到过,Python 中的对象都有三个特性
|
||||
|
||||
- **id**
|
||||
标识了一个对象的唯一性,使用内置函数 `id()` 可以获取到
|
||||
- **类型**
|
||||
表明了这个对象是属于哪个类, 使用内置函数 `type()` 可以获取到
|
||||
- **值**
|
||||
就是这个对象的本身,可以使用内置函数 `print()` 看到,这个看到的是 Python 让你看到的一个对象特有的表现方式而已。
|
||||
|
||||
### 3、创建类
|
||||
|
||||
使用关键字 `class` 创建一个类。
|
||||
|
||||
类名其实和之前我们说的使用变量名的规则一样。
|
||||
|
||||
但是这里有一点儿要注意,就是类名的第一个字母需要大写,这是规范。
|
||||
|
||||
```python
|
||||
class Foo:
|
||||
pass
|
||||
class Car():
|
||||
color = 'red' # 属性
|
||||
def run(self): # 方法
|
||||
pass
|
||||
self 指的是类实例对象本身(注意:不是类本身)。
|
||||
|
||||
class Person:
|
||||
def __init__(self,name):
|
||||
self.name=name
|
||||
def sayhello(self):
|
||||
print('My name is:',self.name)
|
||||
|
||||
p = Person('newrain')
|
||||
p.sayhello()
|
||||
print(p)
|
||||
|
||||
class Person:
|
||||
def __init__(self,name,age): #构造函数
|
||||
self.name=name
|
||||
self.age=age
|
||||
def sayhello(self):
|
||||
print('My name is:',self.name)
|
||||
def age1(self):
|
||||
print('is age',self.age)
|
||||
|
||||
p = Person('newrain','18')
|
||||
p.sayhello()
|
||||
p.age1()
|
||||
print(p)
|
||||
# 注意变量名和函数名不要重复
|
||||
|
||||
在上述例子中,self指向Person的实例p。 为什么不是指向类本身呢,如下例子:
|
||||
|
||||
class Person:
|
||||
def __init__(self,name,age): #构造函数
|
||||
self.name=name
|
||||
self.age=age
|
||||
def sayhello(self):
|
||||
print('My name is:',self.name)
|
||||
def age1(self):
|
||||
print('is age',self.age)
|
||||
|
||||
p = Person('newrain','18') # p的实例对象(p的self)
|
||||
p.sayhello()
|
||||
p.age1()
|
||||
|
||||
p1 = Person('test','18') #p1的实例对象地址 (p1的self)
|
||||
p1.sayhello()
|
||||
p1.age1()
|
||||
|
||||
print(p)
|
||||
print(p1)
|
||||
|
||||
如果self指向类本身,那么当有多个实例对象时,self指向哪一个呢?
|
||||
|
||||
总结
|
||||
self 在定义时需要定义,但是在调用时会自动传入。
|
||||
self 的名字并不是规定死的,但是最好还是按照约定是用self
|
||||
self 总是指调用时的类的实例。
|
||||
```
|
||||
|
||||
```python
|
||||
#_*_ coding:utf-8 _*_
|
||||
# 面向函数
|
||||
def f1():
|
||||
print('name')
|
||||
|
||||
def f2(name):
|
||||
print('i am %s' % name)
|
||||
|
||||
f1()
|
||||
f2('lili')
|
||||
|
||||
# 面向对象
|
||||
class foo:
|
||||
def f1(self):
|
||||
print('name')
|
||||
|
||||
def f2(self,name):
|
||||
print('i am %s' % name)
|
||||
|
||||
obj = foo()
|
||||
obj.f1()
|
||||
obj.f2('name')
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 4、实例化对象
|
||||
|
||||
使用 `类名()` 可以实例化一个对象,你可以使用给这个实例化的对象起一个名字。(根据类实例化对象)
|
||||
|
||||
定义类
|
||||
|
||||
```python
|
||||
class Car():
|
||||
color = 'red' # 属性
|
||||
def travel(self): # 方法
|
||||
pass
|
||||
```
|
||||
|
||||
实例化一个对象
|
||||
|
||||
```python
|
||||
Car() # 没有起名字
|
||||
|
||||
mycar = Car() # 起了个名字 mycar
|
||||
```
|
||||
|
||||
> 由类实例化出的对象成为这个类的一个实例
|
||||
|
||||
### 5、属性
|
||||
|
||||
类的属性分为类的数据属性(key=value)和函数属性
|
||||
|
||||
类的实例只有数据属性(key=value)
|
||||
|
||||
```python
|
||||
class Person():
|
||||
city = "BeiJing" # 类的数据属性
|
||||
def run(self): # 类的函数属性
|
||||
pass
|
||||
```
|
||||
|
||||
> 类属性可以被类和对象调用, 是所有对象共享的
|
||||
>
|
||||
> 实例属性只能由对象调用
|
||||
|
||||
### 6、对象的初始化方法 `__init__()`
|
||||
|
||||
对象的初始化方法是用于实例化对象时使用的。
|
||||
|
||||
方法的名称是固定的 `__init__()`
|
||||
|
||||
当进行实例化的时候,此方法就会自动被调用。
|
||||
|
||||
```python
|
||||
# 类的封装
|
||||
class Person():
|
||||
def __init__(self,name,age): # 初始化方法
|
||||
self.Name = name
|
||||
self.Age = age
|
||||
|
||||
def run(self):
|
||||
print('{} is running'.format(self.Name))
|
||||
|
||||
#_*_ coding:utf-8 _*_
|
||||
# 面向函数
|
||||
def fetch():
|
||||
#连接数据库,hostname,port ,user, pwd ,db,字符集,
|
||||
#打开数据连接
|
||||
#操作数据库链接
|
||||
#关闭
|
||||
pass
|
||||
|
||||
def modify():
|
||||
#连接数据库,hostname,port ,user, pwd ,db,字符集,
|
||||
#打开数据连接
|
||||
#操作数据库链接
|
||||
#关闭
|
||||
pass
|
||||
def remove():
|
||||
#连接数据库,hostname,port ,user, pwd ,db,字符集,
|
||||
#打开数据连接
|
||||
#操作数据库链接
|
||||
#关闭
|
||||
pass
|
||||
def create():
|
||||
#连接数据库,hostname,port ,user, pwd ,db,字符集,
|
||||
#打开数据连接
|
||||
#操作数据库链接
|
||||
#关闭
|
||||
pass
|
||||
|
||||
# 如果参数化也可以解决
|
||||
def create(hostname,port ,user, pwd ,db):
|
||||
#连接数据库,hostname,port ,user, pwd ,db,字符集,
|
||||
#打开数据连接
|
||||
#操作数据库链接
|
||||
#关闭
|
||||
pass
|
||||
|
||||
# 面向对象
|
||||
class foo:
|
||||
def __init__(self,hostname,port ,user, pwd ,db): #构造方法
|
||||
self.hostname = hostname
|
||||
self.port = port
|
||||
#...将所有的参数构造成方法
|
||||
def fetch(self):
|
||||
pass
|
||||
def modify(self,name):
|
||||
pass
|
||||
def create(self,name):
|
||||
# 连接 self.hostname,self.port (直接调用构造函数的方法)
|
||||
pass
|
||||
def remove(self,name):
|
||||
pass
|
||||
|
||||
obj = foo(hostname,port,user,pwd,db)
|
||||
obj.create()
|
||||
|
||||
# 类的执行流程(封装)
|
||||
#1,解释器从上往下执行,将类读到内存里
|
||||
#2,获取类的各种方法,没有创建对象
|
||||
#3,创建一个foo对象obj,类对象指针(python一切都是对象,对象就有创建他的类)
|
||||
#4,把值传给了构造函数,保存在了构造函数里
|
||||
#5,通过类对象指针指向foo类,调用里面的方法(简单理解还是变量,把类和对象关联起来)
|
||||
|
||||
#类里面要公用的字段统一封装到构造函数里,统一调用
|
||||
|
||||
```
|
||||
|
||||
### 7、方法
|
||||
|
||||
凡是在类里定义的函数都都称为方法
|
||||
|
||||
方法本质上是函数,也是类的函数属性
|
||||
|
||||
```python
|
||||
class Person():
|
||||
def run(self): # 方法
|
||||
pass
|
||||
|
||||
def talk(self): # 方法
|
||||
pass
|
||||
#_*_ coding:utf-8 _*_
|
||||
#游戏模式
|
||||
|
||||
#1、创建三个游戏人物,分别是:
|
||||
#莎莎,女,18,初始战斗力1000
|
||||
#浪浪,男,20,初始战斗力1800
|
||||
#小爱,女,19,初始战斗力2500
|
||||
|
||||
# class Person:
|
||||
# def __init__(self, name, gen, age, fig): # 构造函数
|
||||
# self.name = name
|
||||
# self.gender = gen
|
||||
# self.age = age
|
||||
# self.fight =fig
|
||||
#
|
||||
# #创建角色
|
||||
# obj1 = Person('莎莎','女',18,1000)
|
||||
|
||||
...
|
||||
# 内存里根据类,创建了3个对象,3个对象都指向同一个类
|
||||
# 给游戏添加功能(聊天,打架)怎么添加
|
||||
class Person:
|
||||
def __init__(self, na, gen, age, fig):
|
||||
self.name = na
|
||||
self.gender = gen
|
||||
self.age = age
|
||||
self.fight = fig
|
||||
|
||||
def grassland(self):
|
||||
"""注释:战斗,消耗200战斗力"""
|
||||
self.fight = self.fight - 200
|
||||
|
||||
def practice(self):
|
||||
"""注释:自我修炼,增长100战斗力"""
|
||||
self.fight = self.fight + 200
|
||||
|
||||
def war(self):
|
||||
"""注释:多人游戏,消耗500战斗力"""
|
||||
self.fight = self.fight - 500
|
||||
|
||||
def detail(self):
|
||||
"""注释:当前对象的详细情况"""
|
||||
temp = "姓名:%s ; 性别:%s ; 年龄:%s ; 战斗力:%s" % (self.name, self.gender, self.age, self.fight)
|
||||
print(temp)
|
||||
|
||||
# 创建游戏角色
|
||||
obj1 = Person('莎莎','女',18,1000)
|
||||
obj1.grassland()
|
||||
obj1.practice()
|
||||
obj1.detail()
|
||||
|
||||
obj1 = Person('浪浪','男',18,2000)
|
||||
obj1.grassland()
|
||||
obj1.detail()
|
||||
|
||||
obj1 = Person('小爱','女',18,10000)
|
||||
obj1.grassland()
|
||||
obj1.detail()
|
||||
|
||||
#1, 通过obj2找到类,
|
||||
#2,再通过类执行类里面的方法
|
||||
#3,执行对应的方法,然后就是对自身属性的改变(减少增加)
|
||||
|
||||
# 面向对象模板的实现过程(函数式编程做不到)
|
||||
# 通过面向对象的类先创建模板,通过模板创建多个角色,
|
||||
# 然后多个角色再来执行模板里面的方法
|
||||
# 将内存里对象的属性进行改变
|
||||
|
||||
```
|
||||
|
||||
方法可以被这个类的每个实例对象调用,当一个实例对象调用此方法的时候, `self` 会不自动传值,传入的值就是目前的 实例对象。
|
||||
|
||||
### 8、魔法函数`__str__()` 实现定义类的实例的表现形式
|
||||
|
||||
当我们定义一个类的时候,默认打印出它实例时是不易读的,某些情况下我需要让这个类的实例的表现形式更易读。就可以使用 `__str__()` 这个方法。
|
||||
|
||||
**使用前**
|
||||
|
||||
```python
|
||||
class Person:
|
||||
def __init__(self, name):
|
||||
self.name = name
|
||||
|
||||
p = Person('xiaoming')
|
||||
|
||||
print(p)
|
||||
# <__main__.Person object at 0x10ac290f0>
|
||||
|
||||
```
|
||||
|
||||
**使用后**
|
||||
|
||||
```python
|
||||
class Person:
|
||||
def __init__(self, name):
|
||||
self.name = name
|
||||
|
||||
def __str__(self):
|
||||
return "{}".format(self.name)
|
||||
p = Person('xiaoming')
|
||||
|
||||
print(p)
|
||||
# xiaoming
|
||||
```
|
||||
|
||||
> 其实,`__str__()` 方法本身在我们定义类的时候就已经存在了,是 Python 内置的。我们在这里只是有把这个方法重写了。
|
||||
> 这个方法在使用的时候有**返回值**,且返回值必须是**字符串**类型
|
||||
|
||||
### 9、继承
|
||||
|
||||
在现实世界中,类的继承,表现为我们可以把一个类的共同的属性和方法再进行一个高度的抽象,成为另一个类,这个被抽象出来的类成为父类,刚才被抽象的类成为子类。
|
||||
|
||||
但在计算机中,需要先定义一个父类,之后再定义其他的类(子类)并且继承父类。
|
||||
|
||||
这时子类即使什么也不用做,就会具备父类的所以属性(数据属性和函数属性)。这在计算机语言中就被称为`继承`。 继承并不是 Python 语言特有的,而是所有面向对象语言都有的特性。
|
||||
|
||||
面向对象语言的特性还有另外两个: `多态`, `封装`。
|
||||
|
||||
`继承`、 `多态` 和 `封装` 被称为面向对象语言都三大特性。
|
||||
|
||||
这里我们先只对 `继承` 来讲解。
|
||||
|
||||
#### 1、单纯的继承
|
||||
|
||||
(菱形继承)
|
||||
|
||||
下面我是定义了两个类 `Person` 和 `Teacher`。
|
||||
|
||||
```python
|
||||
Teacher 继承了 Person
|
||||
```
|
||||
|
||||
`Teacher` 被称为子类, `Person` 就是父类
|
||||
|
||||
```python
|
||||
class Person:
|
||||
def __init__(self, name, age):
|
||||
self.name = name
|
||||
self.age = age
|
||||
|
||||
def run(self):
|
||||
print(f'{self.name} is running')
|
||||
|
||||
|
||||
class Teacher(Person):
|
||||
pass
|
||||
|
||||
t = Teacher('xiaoming', '18')
|
||||
t.run()
|
||||
```
|
||||
|
||||
#### 2、添加新方法
|
||||
|
||||
在继承的时候,子类可以定义只属于自己的方法。
|
||||
|
||||
```python
|
||||
class Person:
|
||||
def __init__(self, name, age):
|
||||
self.name = name
|
||||
self.age = age
|
||||
|
||||
def run(self):
|
||||
print(f'{self.name} is running')
|
||||
|
||||
class Teacher(Person):
|
||||
def talk(self):
|
||||
print(f"{self.name} is talking...")
|
||||
|
||||
t = Teacher('xiaoming', '18')
|
||||
t.talk()
|
||||
```
|
||||
|
||||
#### 3、覆盖方法(方法重写)
|
||||
|
||||
在继承中,子类还可以把父类的方法重新实现一下。
|
||||
|
||||
就是定义一个和父类方法同名的方法,但是方法中代码不一样。
|
||||
|
||||
```python
|
||||
class Person:
|
||||
def __init__(self, name, age):
|
||||
self.name = name
|
||||
self.age = age
|
||||
|
||||
def run(self):
|
||||
print(f'{self.name} is running')
|
||||
|
||||
|
||||
class Teacher(Person):
|
||||
def run(self):
|
||||
print(f"{self.name} running on the road")
|
||||
|
||||
def talk(self):
|
||||
print(f"{self.name} is talking...")
|
||||
|
||||
t = Teacher('xiaoming', '18')
|
||||
t.run()
|
||||
```
|
||||
|
||||
#### 4、添加属性
|
||||
|
||||
在继承时,子类还可以为自己的实例对象添加实例的属性。
|
||||
|
||||
```python
|
||||
class Person:
|
||||
def __init__(self, name, age):
|
||||
self.name = name
|
||||
self.age = age
|
||||
|
||||
def run(self):
|
||||
print(f'{self.name} is running')
|
||||
|
||||
class Teacher(Person):
|
||||
def __init__(self,name, age, lev):
|
||||
super().__init__(name, age)
|
||||
self.lev = lev
|
||||
|
||||
|
||||
t = Teacher('xiaoming', 18, 5)
|
||||
|
||||
print(t.lev)
|
||||
```
|
||||
|
||||
### 10、对象之间的互相作用
|
||||
|
||||
王者农药
|
||||
|
||||
在一个类中的方法中,可以通过给其传递相应的参数,从而对其他类的的实例对象进行操作。
|
||||
|
||||
```python
|
||||
#_*_ coding:utf-8 _*_
|
||||
class Master:
|
||||
def __init__(self, name, age,init_self=516, mana=230, attack_num=100):
|
||||
self.name = name
|
||||
self.age = age
|
||||
self.init_self = init_self
|
||||
self.init_mana = mana
|
||||
self.attack_num = attack_num
|
||||
|
||||
def attack(self, obj):
|
||||
self.init_mana = self.init_mana - 20 # 210
|
||||
#print(self.init_mana)
|
||||
obj_self_num = obj.init_self - self.attack_num # 516-90=426
|
||||
obj.init_self = obj_self_num #426
|
||||
def __str__(self):
|
||||
return "{}".format(self.init_mana)
|
||||
|
||||
class Soldier():
|
||||
def __init__(self, name, age,init_self=960, attack_num=90):
|
||||
self.name = name
|
||||
self.age = age
|
||||
self.init_self = init_self
|
||||
self.attack_num = attack_num
|
||||
|
||||
def attack(self, obj):
|
||||
obj_self_num = obj.init_self - self.attack_num #960-100=860
|
||||
obj.init_self = obj_self_num #860
|
||||
m = Master('貂蝉', 18)
|
||||
print(m)
|
||||
|
||||
s = Soldier("阿轲", 30)
|
||||
#s.attack()
|
||||
# 貂蝉攻击 阿轲, 把被攻击的对象 s 作为实参传给 m 对象的方法 `attack`
|
||||
m.attack(s)
|
||||
s.attack(m)
|
||||
# 验证
|
||||
print(s.init_self)
|
||||
print(m.init_self)
|
||||
print(m.init_mana)
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 作业
|
||||
|
||||
```
|
||||
1、根据自己的理解,整理一下面向对象和函数式编程的优劣势.
|
||||
2、编写一个图书管理系统的框架
|
||||
(1) 登录功能
|
||||
(2) 注册功能
|
||||
(3) 借书功能
|
||||
(4) 还书功能
|
||||
(5) 图书上架功能 管理员
|
||||
```
|
||||
|
||||
702
MD/5、Python 5.md
Normal file
702
MD/5、Python 5.md
Normal file
@ -0,0 +1,702 @@
|
||||
## 十六、模块的导入和使用
|
||||
|
||||
### 1、模块介绍
|
||||
|
||||
- Python 有时候称为胶水语言,就是因为它有强大的可扩展性,这个扩展性就是用模块实现的。
|
||||
|
||||
- 模块其实就是一个以 `.py` 结尾的 Python 文件,这个文件中可以包含变量、函数、类等。
|
||||
|
||||
- 模块可以包含实现了一个或者多个功能的代码。
|
||||
|
||||
- 模块可以在其他 Python 文件中使用,可以通过网络进行传播。
|
||||
|
||||
这样的话,如果想在你的程序中实现某些功能,其实网络的其他程序猿已经给你写好了,下载下来,安装到自己的环境下,就可以使用了。
|
||||
|
||||
### 2、为什么要模块化
|
||||
|
||||
**模块化编程**是指将大型,笨拙的编程任务分解为单独的,更小的,更易于管理的子任务或**模块的过程**。然后可以像构建块一样拼凑单个模块以创建更大的应用程序。
|
||||
|
||||
在大型应用程序中**模块化**代码有几个优点:
|
||||
|
||||
- **简单性:**模块通常只关注问题的一小部分,而不是关注当前的整个问题。如果您正在处理单个模块,那么您的头脑中要思考的将有一个较小的问题范围。这使得开发更容易,更不容易出错。
|
||||
- **可维护性:**模块通常设计为能够在不同的问题域之间实施逻辑边界。如果以最小化相互依赖性的方式编写模块,则对单个模块的修改将对程序的其他部分产生影响的可能性降低。(您甚至可以在不了解该模块之外的应用程序的情况下对模块进行更改。)这使得许多程序员团队在大型应用程序上协同工作更加可行。
|
||||
- **可重用性:**单个模块中定义的功能可以通过应用程序的其他部分轻松地重用。这消除了重新创建重复代码的需要。
|
||||
- **范围:**模块通常定义一个单独的**命名空间**,这有助于避免程序的不同区域中的变量名之间的冲突。
|
||||
|
||||
**函数**,**模块**和**包**都是Python中用于促进代码模块化的构造。
|
||||
|
||||
### 3、模块的分类
|
||||
|
||||
#### 1、实现方式分类
|
||||
|
||||
实际上有两种不同的方法可以在Python中定义**模块**:
|
||||
|
||||
1. 模块可以用Python本身编写。
|
||||
2. 模块可以用**C**编写并在运行时动态加载,就像`re`(**正则表达式**)模块一样。
|
||||
|
||||
以上两种情况下,模块的内容都以相同的方式访问:使用`import`语句
|
||||
|
||||
#### 2、模块的归属分类
|
||||
|
||||
- 1. 包含在解释中的一个**内置的**模块本,像[`itertools`模块](https://realpython.com/python-itertools/)。
|
||||
- 1. 其他机构或个人开发者编写的模块,成为第三方模块
|
||||
- 1. 自己写的 `.py` 文件,就是自定义的模块
|
||||
|
||||
#### 3、第三方模块
|
||||
|
||||
从网络上下载的模块称为 **第三方模块**。
|
||||
|
||||
#### 安装方法
|
||||
|
||||
##### 1、 `pip3` 工具安装
|
||||
|
||||
例如下面的示例是安装用于执行远程主机命令的模块 `paramiko`
|
||||
|
||||
```shell
|
||||
注意: pip3 是 bash 环境下的命令
|
||||
pip3 install paramiko
|
||||
```
|
||||
|
||||
> python2.x 使用 `pip`
|
||||
> python3.x 使用 `pip3`
|
||||
> 当然这也不是固定的,比如你给 `pip3` 定义了一个别名 `pip`
|
||||
|
||||
##### 2、源码安装
|
||||
|
||||
源码安装就是,从网络上下载没有封装的 python 文件的源码,之后在本地执行其源码中的 `setup.py` 文件进行安装。
|
||||
|
||||
模块的源码一般都有一个主目录,主目录中包含了一个到多个子目录和文件。
|
||||
但是主目录下一定有一个 `setup.py` 的文件,这个是源码安装的入口文件,就是需要执行这个文件并且传入一个 `install` 参数进行源码安装。
|
||||
|
||||
示例:
|
||||
|
||||
###### a. 下载源码包
|
||||
|
||||
```shell
|
||||
wget https://files.pythonhosted.org/packages/4a/1b/9b40393630954b54a4182ca65a9cf80b41803108fcae435ffd6af57af5ae/redis-3.0.1.tar.gz
|
||||
```
|
||||
|
||||
###### b. 解压源码包
|
||||
|
||||
```shell
|
||||
tar -xf redis-3.0.1.tar.gz
|
||||
```
|
||||
|
||||
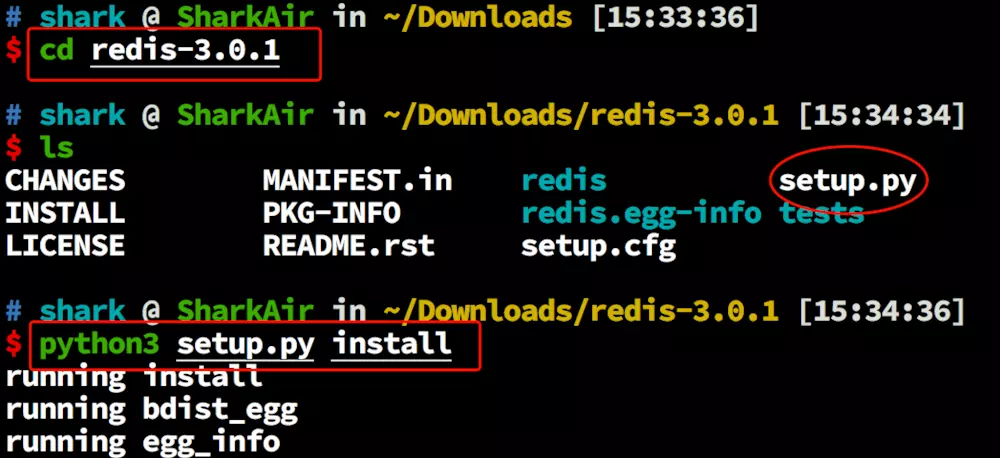
1. 进入模块源码的主目录,并安装源码包
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
> 上面表示安装成功
|
||||
|
||||
#### 4、自定义模块
|
||||
|
||||
有的情况下,是需要自己编写一些模块的,这种就是自定义模块了。
|
||||
|
||||
示例:
|
||||
|
||||
```python
|
||||
some_mod.py
|
||||
x = 10
|
||||
|
||||
li = ['shark', 18]
|
||||
|
||||
def foo():
|
||||
return 30
|
||||
|
||||
class Person():
|
||||
def __init__(self, name, age):
|
||||
self.name = name
|
||||
self.age = age
|
||||
```
|
||||
|
||||
#### 5、内置模块
|
||||
|
||||
模块除了 **第三方模块**, **自定义模块**,还有 **内置模块**。
|
||||
|
||||
### 4、模块的使用
|
||||
|
||||
- 使用模块需要先导入模块名。
|
||||
|
||||
- 模块名就是把 `.py` 去掉后的文件名。比如 `some_mod.py` 的模块名就是 `some_mod`
|
||||
|
||||
#### 1、导入模块
|
||||
|
||||
```python
|
||||
import some_mod
|
||||
```
|
||||
|
||||
#### 2、使用模块中的对象
|
||||
|
||||
要想使用模块中的变量名或者函数名等,只需要使用 `模块名.变量名` 的方式即可。
|
||||
|
||||
例如,下面是使用的了 `some_mod` 模块中的 `foo` 函数。
|
||||
|
||||
```python
|
||||
import some_mod
|
||||
|
||||
some_mod.foo()
|
||||
```
|
||||
|
||||
#### 3、更多模块导入的方式
|
||||
|
||||
a. 从模块中导入其中的一个对象
|
||||
|
||||
```python
|
||||
from some_mod import x
|
||||
```
|
||||
|
||||
b. 从模块中导入多个对象
|
||||
|
||||
```python
|
||||
from some_mod import x, foo
|
||||
```
|
||||
|
||||
c. 从模块中导入全部的对象, 不建议这么做
|
||||
|
||||
```python
|
||||
from some_mod import *
|
||||
```
|
||||
|
||||
#### 4、导入模块时模块的代码会自动被执行一次
|
||||
|
||||
```python
|
||||
st = """www.qfecu.com
|
||||
千峰欢迎您!
|
||||
www.qfecu.com
|
||||
千峰欢迎您!
|
||||
"""
|
||||
|
||||
print(st)
|
||||
```
|
||||
|
||||
## 十七、包的导入和使用
|
||||
|
||||
### 1、包是什么?
|
||||
|
||||
- 包就是包含了一个 `__init__.py` 文件的文件夹,这个文件夹下可以有更多的目录或文件。就是说,包里可以用子包或单个 `.py` 的文件。
|
||||
|
||||
- 其实包也是模块,就是说包和单一的 `.py` 文件统称为模块。
|
||||
|
||||
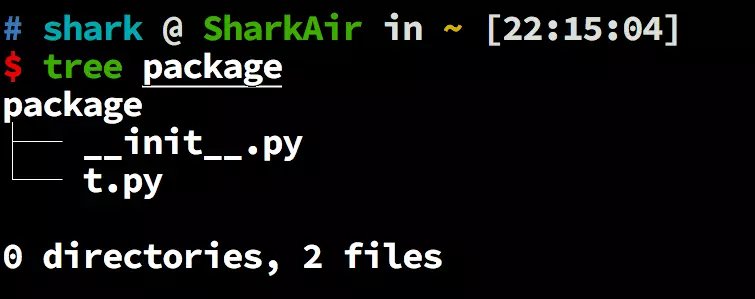
### 2、包的目录结构
|
||||
|
||||
|
||||
|
||||
### 1、文件 `__init__.py`
|
||||
|
||||
`__init__.py` 文件,在 Python3.x 中可以没有,但是在 Python2.x 中必须有。
|
||||
|
||||
文件中可以有代码,也可以是个空文件,但是文件名不能是其他的。
|
||||
|
||||
到导入包的时候,此文件假如存在,会以此文件去建包的名称空间。
|
||||
|
||||
也就是说,导入包的时候,只要在 `__init__.py` 文件中的名称才可以生效。否则,即使是一个模块在包目录下面也不会被导入到内存中,也就不会生效。
|
||||
|
||||
### 3、使用包
|
||||
|
||||
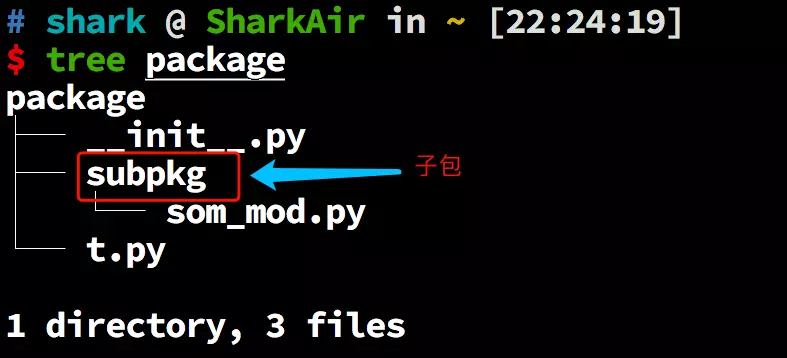
示例包目录机构
|
||||
|
||||
|
||||
|
||||
使用包也需要导入
|
||||
|
||||
#### 1、单独导入包
|
||||
|
||||
```python
|
||||
import package # 注意这样不会导入其下面的模块和子包
|
||||
```
|
||||
|
||||
#### 2、 从包中导入下面的模块
|
||||
|
||||
```python
|
||||
from package import t
|
||||
```
|
||||
|
||||
#### 3、从包中导入下面的子包,注意这不会导入子包下面的任何模块
|
||||
|
||||
```python
|
||||
from package import subpkg
|
||||
```
|
||||
|
||||
#### 4、从包的子包中导入子包的模块
|
||||
|
||||
```python
|
||||
from package.subpkg import som_mod
|
||||
```
|
||||
|
||||
#### 5、从包或子包的模块中导入具体的对象
|
||||
|
||||
```python
|
||||
from package.t import foo
|
||||
|
||||
from package.subpkg.som_mod import x
|
||||
|
||||
from package.t import x as y # 把 x 导入后起个别名 y
|
||||
```
|
||||
|
||||
**记住一点:不论是导入包还是模块,从左向右的顺序来说,最后一个点儿的左边一定是一个包名,而不能是一个模块名**
|
||||
|
||||
下面是错误的
|
||||
|
||||
```python
|
||||
import package.t.foo
|
||||
from package.subpkg import som_mod.x
|
||||
```
|
||||
|
||||
### 4、模块的内置变量 `__name__`
|
||||
|
||||
每个 `.py` 文件都有一个变量名 `__name__`, 这个变量名的值会根据这个文件的用途不同而随之变化。
|
||||
|
||||
1. 当文件作为模块被其他文件使用时,`__name__` 的值是这个文件的模块名
|
||||
2. 当文件作为脚本(就是作为可执行文件)使用时,`__name__` 的值是字符串类型的 `'__main__'`
|
||||
|
||||
通常你会看到一些 Python 脚本中会有类似下面的代码:
|
||||
|
||||
```python
|
||||
some_script.py
|
||||
def foo():
|
||||
pass
|
||||
|
||||
def func():
|
||||
pass
|
||||
|
||||
def main():
|
||||
foo()
|
||||
func()
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
print('程序自身在运行')
|
||||
else:
|
||||
print('我来自另一模块')
|
||||
```
|
||||
|
||||
使用这个脚本
|
||||
|
||||
```python
|
||||
python3 some_script.py
|
||||
```
|
||||
|
||||
> 这样执行这个脚本的话,其内置的 `__name__` 变量的值就是字符串的 `'__main__'`。
|
||||
> 这样的话, `if` 的判断添加就会达成,从而其语句下面的代码就会执行, `main()` 函数就会被调用 。
|
||||
|
||||
### 5、模块名的搜索路径
|
||||
|
||||
当你导入模块或者包的时候, 查找模块或包的顺序:
|
||||
|
||||
1. 系统会先从当前目录下查找
|
||||
2. 之后再从`sys.path` 输出的值中的路径里查找模块名或者包名。
|
||||
|
||||
```python
|
||||
import sys
|
||||
|
||||
print(sys.path)
|
||||
```
|
||||
|
||||
`sys.path` 输出的值是一个 Python 的列表,这个列表我们可以对其修改的。
|
||||
|
||||
比如我们可以把某个文件的路径添加到此列表中,通常会这么做。
|
||||
|
||||
```python
|
||||
run.py
|
||||
import os
|
||||
import sys
|
||||
|
||||
BASE_DIR = os.path.dirname(os.path.abspath(__file__)) # python2
|
||||
sys.path.insert(0, BASE_DIR)
|
||||
|
||||
sys.path.insert(0,'D:\gitlab') # 将D:\gitlab 添加到python解释器的查询列表中
|
||||
print(sys.path)
|
||||
```
|
||||
|
||||
|
||||
|
||||
## 十八、常用模块
|
||||
|
||||
### 1、sys 模块
|
||||
|
||||
提供了一系列有关Python运行环境的变量和函数
|
||||
|
||||
```python
|
||||
#python3 sys模块
|
||||
#sys模块负责程序与python解释器的交互,提供了一系列的函数和变量,
|
||||
#用于操控python运行时的环境。
|
||||
|
||||
!# sys.argv 接收命令行参数,生成一个List,第一个元素是程序本身路径
|
||||
# sys.exc_info() 获取当前正在处理的异常类,exc_type、exc_value、exc_traceback当前处理的异常详细信息
|
||||
!# sys.exit(n) 退出程序,正常退出时exit(0)
|
||||
# sys.hexversion 获取Python解释程序的版本值,16进制格式如:0x020403F0
|
||||
# sys.version 获取Python解释程序的版本信息
|
||||
# sys.maxsize 获取内存中最大的Int值 python2中是maxint
|
||||
# sys.maxunicode 获取内存从中最大的Unicode值
|
||||
# sys.modules 返回系统导入的模块字典,key是模块名,value是模块
|
||||
!# sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
|
||||
# sys.platform 返回操作系统平台名称
|
||||
# sys.stdout 标准输出
|
||||
# sys.stdin 标准输入
|
||||
# sys.stderr 错误输出
|
||||
!# sys.exec_prefix 返回平台独立的python文件安装的位置
|
||||
|
||||
import sys
|
||||
sys.argv # 命令行参数列表,第一个元素是程序本身路径;用于接收执行
|
||||
# Python 脚本时传的参数
|
||||
# 示例:
|
||||
python3 echo.py
|
||||
a b c
|
||||
|
||||
# echo.py 文件内容
|
||||
import sys
|
||||
print(sys.argv[1:])
|
||||
|
||||
# 输出结果
|
||||
['a', 'b', 'c']
|
||||
|
||||
print('脚本名称:{}'.format(sys.argv[0]))
|
||||
for i in sys.argv:
|
||||
if i == sys.argv[0]:
|
||||
continue
|
||||
print('参数为:',i)
|
||||
|
||||
print('总参数个数:{}'.format(len(sys.argv)-1)
|
||||
|
||||
[root@python python]# ./sysargv.py s1 s2 s3 s4 s5
|
||||
脚本名称:./sysargv.py
|
||||
参数为: s1
|
||||
参数为: s2
|
||||
参数为: s3
|
||||
参数为: s4
|
||||
参数为: s5
|
||||
总参数个数:5
|
||||
|
||||
|
||||
```
|
||||
|
||||
### 2、os 模块
|
||||
|
||||
os模块是与操作系统交互的一个接口,包含普遍的操作系统功能,如果你希望你的程序能够与平台有关的话,这个模块是尤为重要的。
|
||||
|
||||
```python
|
||||
import os
|
||||
|
||||
# os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 # pwd
|
||||
# os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd # cd
|
||||
# os.curdir 返回当前目录: ('.')
|
||||
# os.pardir 获取当前目录的父目录字符串名:('..')
|
||||
# os.makedirs('dirname1/dirname2') 可生成多层递归目录 # mkdir -p
|
||||
# os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 rmdir -p
|
||||
# os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname # mkdir
|
||||
# os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname # rmdir
|
||||
# os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 # ls -a
|
||||
# os.remove() 删除一个文件
|
||||
# os.rename("oldname","newname") 重命名文件/目录 rename
|
||||
# os.stat('path/filename') 获取文件/目录信息
|
||||
# os.sep 输出操作系统特定的路径分隔符,win下为"\",Linux下为"/"
|
||||
# os.linesep 输出当前平台使用的行终止符,win下为"\r\n",Linux下为"\n"
|
||||
# os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为:
|
||||
# os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
|
||||
# os.system("bash command") 运行shell命令,直接显示 #一般用于脚本中去打印 # 这种方法实用性不如 os.popen subprocess.getoutput
|
||||
# os.environ 获取系统环境变量
|
||||
# os.path.abspath(path) 返回path规范化的绝对路径
|
||||
# os.path.split(path) 将path分割成目录和文件名二元组返回 # 不去检测文件系统
|
||||
# os.path.dirname(path) 返回path的上一层目录。其实就是os.path.split(path)的第一个元素
|
||||
# os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
|
||||
# os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False # if [ -e ]
|
||||
# os.path.isabs(path) 如果path是绝对路径,返回True
|
||||
# os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False # if [ -f ]
|
||||
# os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False # if [ -d ]
|
||||
# os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,最后一个绝对路径之前的参数将被忽略
|
||||
# os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
|
||||
# os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
|
||||
|
||||
开始练习
|
||||
import os
|
||||
# 获取当前工作目录,即当前python脚本工作的目录路径
|
||||
os.getcwd()
|
||||
|
||||
# 切换当前脚本工作目录;相当于shell下cd
|
||||
os.chdir("./dirname")
|
||||
|
||||
# 创建单级目录,相当于 shell 中的 mkdir dirname
|
||||
os.mkdir('dirname')
|
||||
|
||||
# 递归创建目录
|
||||
os.makedirs('dir1/dir2')
|
||||
|
||||
# 删除单级空目录,若目录非空则无法删除,并报错。
|
||||
os.rmdir('dirname')
|
||||
|
||||
# 递归删除 空 目录
|
||||
os.removedirs('dir1/dir2')
|
||||
|
||||
# 列出指定目录下的所有文件和目录,包括隐藏文件,并以列表方式打印
|
||||
os.listdir('dirname')
|
||||
|
||||
# 递归查找目录下的文件和目录,返回一个生成器对象。
|
||||
# 生成器对象是个可迭代对象,每一层包含了三个值:
|
||||
# 1. 当前目录路径,2. 其下面的所有子目录, 3. 其下面的所有文件
|
||||
os.walk('dirname')
|
||||
|
||||
### 练习需求 ###
|
||||
1. 在 /tmp 目录下,创建目录 a/b/c
|
||||
2. 进入到 /tmp/a/b 目录下,创建一个目录 f
|
||||
3. 把当前的工作目录写到 f 目录下的 work.txt 文件内。
|
||||
4. 删除目录 c
|
||||
5. 把 /tmp 目录下及其子目录下的所有文件和目录打印到屏幕上
|
||||
# 如果path存在,返回True;如果path不存在,返回False 在这里值得注意的是,
|
||||
# 在Linux shell 中,Python会认为: / 左边一定是一个目录,而不是文件
|
||||
os.path.exists(path)
|
||||
|
||||
# 如果path是一个存在的目录,则返回True。否则返回False
|
||||
os.path.isdir(path)
|
||||
|
||||
# 如果path是一个存在的文件,返回True。否则返回False
|
||||
os.path.isfile(path)
|
||||
|
||||
# 删除一个文件
|
||||
os.remove('file')
|
||||
|
||||
# 重命名文件/目录
|
||||
os.rename("oldname", "new")
|
||||
|
||||
# 如果path是绝对路径,返回 True
|
||||
os.path.isabs(path)
|
||||
|
||||
# 将 path 分割成目录和文件名二元组返回
|
||||
os.path.split(path)
|
||||
|
||||
|
||||
# 返回 文件 或 path 规范化的绝对路径
|
||||
os.path.abspath(path)
|
||||
|
||||
# 返回path的目录。 其实返回的就是 os.path.split(path) 的第一个元素
|
||||
os.path.dirname(path)
|
||||
|
||||
# 将多个路径组合后返回,每个路径之间不需要加路径分隔符(\或者/)
|
||||
os.path.join(path1[, path2[, ...]])
|
||||
```
|
||||
|
||||
### 3、time 时间模块
|
||||
|
||||
#### 1、time 模块
|
||||
|
||||
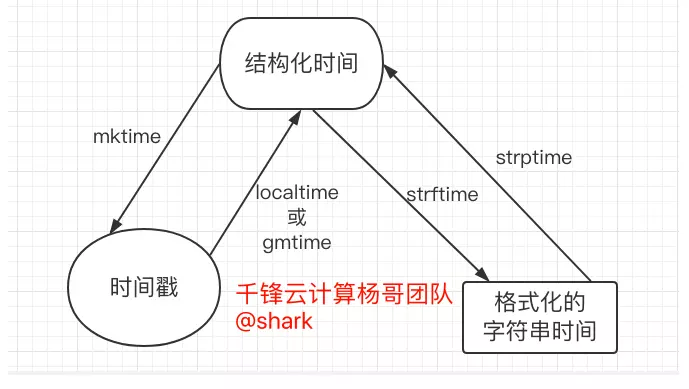
在Python中,通常有这几种方式来表示时间:
|
||||
|
||||
- 时间戳(timestamp):通常来说,时间戳表示的是从1970年1月1日00:00:00开始到目前的秒数。我们运行 `type(time.time())`,返回的是float类型。
|
||||
|
||||
- 结构化的时间(struct_time):struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,周几,一年中第几天,夏令时)
|
||||
|
||||
```python
|
||||
属性 值
|
||||
tm_year(年) 比如2011
|
||||
tm_mon(月) 1 - 12
|
||||
tm_mday(日) 1 - 31
|
||||
tm_hour(时) 0 - 23
|
||||
tm_min(分) 0 - 59
|
||||
tm_sec(秒) 0 - 61(60和61为闰秒)
|
||||
tm_wday(weekday) 0 - 6(0表示周一)
|
||||
tm_yday(一年中的第几天) 1 - 366
|
||||
tm_isdst(是否是夏令时) 默认为 0
|
||||
```
|
||||
|
||||
- 格式化的时间字符串(Format String)
|
||||
|
||||
```python
|
||||
# 快速认识它们
|
||||
In [139]: import time
|
||||
|
||||
In [140]: time.time()
|
||||
Out[140]: 1522057206.0065496
|
||||
|
||||
In [141]: time.localtime() # 本地时间, 结构化时间
|
||||
Out[141]: time.struct_time(tm_year=2018, tm_mon=3, tm_mday=26, tm_hour=17, tm_min=40, tm_sec=53, tm_wday=0, tm_yday=85, tm_isdst=0)
|
||||
|
||||
In [142]: time.gmtime() # 格林威治时间(UTC)
|
||||
Out[142]: time.struct_time(tm_year=2018, tm_mon=3, tm_mday=26, tm_hour=9, tm_min=43, tm_sec=31, tm_wday=0, tm_yday=85, tm_isdst=0)
|
||||
|
||||
In [143]: time.strftime("%Y-%m-%d %X")
|
||||
Out[143]: '2018-03-26 17:40:40'
|
||||
|
||||
|
||||
#time模块没有time.py文件,是内置到解释器中的模块
|
||||
#三种时间表示方式
|
||||
'''
|
||||
1、时间戳(timestamp): 通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。
|
||||
2、格式化的时间字符串:"2018-09-03 10:02:01"
|
||||
3、元组(struct_time):struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天,夏令时)
|
||||
'''
|
||||
#UTC:(Coordinated Universal Time,世界协调时),亦即格林威治天文时间,世界标准时间。在中国为UTC+8
|
||||
#DST:(Daylight Saving Time),即夏令时。
|
||||
|
||||
大家开始练习
|
||||
import time
|
||||
#时间戳 time()
|
||||
print(time.time())
|
||||
1535939025.4159343
|
||||
|
||||
#struct_time
|
||||
localtime([secs]) 将一个时间戳转换为当前时区的struct_time。secs参数未提供,则以当前时间为准。
|
||||
#当地时间
|
||||
print(time.localtime(time.time()))
|
||||
time.struct_time(tm_year=2018, tm_mon=9, tm_mday=3, tm_hour=9, tm_min=46, tm_sec=7, tm_wday=0, tm_yday=246, tm_isdst=0)
|
||||
print(time.localtime())
|
||||
time.struct_time(tm_year=2018, tm_mon=9, tm_mday=3, tm_hour=9, tm_min=48, tm_sec=19, tm_wday=0, tm_yday=246, tm_isdst=0)
|
||||
|
||||
t_local=time.localtime()
|
||||
print(t_local.tm_year)
|
||||
print(t_local.tm_mon)
|
||||
print(t_local.tm_mday)
|
||||
|
||||
|
||||
#gmtime([secs]) 将一个时间戳转换为UTC时区(0时区)的struct_time。
|
||||
print(time.gmtime())
|
||||
time.struct_time(tm_year=2018, tm_mon=9, tm_mday=3, tm_hour=1, tm_min=51, tm_sec=38, tm_wday=0, tm_yday=246, tm_isdst=0)
|
||||
|
||||
mktime(t) : 将一个struct_time转化为时间戳。
|
||||
print(time.mktime(time.localtime()))
|
||||
1535939934.0
|
||||
|
||||
asctime([t]) : 把一个表示时间struct_time表示为这种形式:'Mon Sep 3 10:01:46 2018'。默认将time.localtime()作为参数传入。
|
||||
print(time.asctime())
|
||||
Mon Sep 3 10:01:46 2018
|
||||
|
||||
ctime([secs]) : 把一个时间戳转化为time.asctime()的形式,默认time.time()为参数。
|
||||
print(time.ctime())
|
||||
Mon Sep 3 10:05:40 2018
|
||||
|
||||
strftime(format[, t])
|
||||
# 把一个代表时间的struct_time转化为格式化的时间字符串。
|
||||
# 如果t未指定,将传入time.localtime()。
|
||||
# 如果元组中任何一个元素越界,ValueError的错误将会被抛出。
|
||||
print(time.strftime("%Y-%m-%d %X")) #%X 等同于 %H%M%S
|
||||
print(time.strftime("%Y-%m-%d %X",time.localtime()))
|
||||
print(time.strftime("%Y-%m-%d %H:%M:%S"))
|
||||
|
||||
strptime(string[, format])
|
||||
# 把一个格式化时间字符串转化为struct_time。实际上它是strftime()是逆操作。
|
||||
print(time.strptime('2018-09-03 10:14:53', '%Y-%m-%d %X'))
|
||||
time.struct_time(tm_year=2018, tm_mon=9, tm_mday=3, tm_hour=10, tm_min=14, tm_sec=53, tm_wday=0, tm_yday=246, tm_isdst=-1)
|
||||
|
||||
sleep(secs)
|
||||
time.sleep(10) #停止10秒,继续运行
|
||||
|
||||
```
|
||||
|
||||
格式化时间的变量:
|
||||
|
||||
| **格式** | **含义** |
|
||||
| -------- | ------------------------------------------------------------ |
|
||||
| %a | 本地(locale)简化星期名称 |
|
||||
| %A | 本地完整星期名称 |
|
||||
| %b | 本地简化月份名称 |
|
||||
| %B | 本地完整月份名称 |
|
||||
| %c | 本地相应的日期和时间表示 |
|
||||
| %d | 一个月中的第几天(01 - 31) |
|
||||
| %H | 一天中的第几个小时(24小时制,00 - 23) |
|
||||
| %I | 第几个小时(12小时制,01 - 12) |
|
||||
| %j | 一年中的第几天(001 - 366) |
|
||||
| %m | 月份(01 - 12) |
|
||||
| %M | 分钟数(00 - 59) |
|
||||
| %p | 本地am或者pm的相应符 |
|
||||
| %S | 秒(00 - 61) |
|
||||
| %U | 一年中的星期数。(00 - 53星期天是一个星期的开始。)第一个星期天之前的所有天数都放在第0周。 |
|
||||
| %w | 一个星期中的第几天(0 - 6,0是星期天) |
|
||||
| %W | 和%U基本相同,不同的是%W以星期一为一个星期的开始。 |
|
||||
| %x | 本地相应日期 |
|
||||
| %X | 本地相应时间 |
|
||||
| %y | 去掉世纪的年份(00 - 99) |
|
||||
| %Y | 完整的年份 |
|
||||
| %Z | 时区的名字(如果不存在为空字符) |
|
||||
| %% | ‘%’字符 |
|
||||
|
||||
#### 2、时间的互相转换
|
||||
|
||||
|
||||
|
||||
```python
|
||||
In [153]: time.time()
|
||||
Out[153]: 1522071229.4780636
|
||||
|
||||
In [154]: time.localtime(1522071229.4780636)
|
||||
|
||||
In [155]: time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(1522071229.4780636))
|
||||
|
||||
In [156]: time.strptime('2018-03-26 21:41', "%Y-%m-%d %H:%M")
|
||||
|
||||
In [157]: time.mktime(time.localtime())
|
||||
In [178]: time.ctime(1093849081)
|
||||
Out[178]: 'Mon Aug 30 14:58:01 2004'
|
||||
|
||||
In [179]: time.asctime(time.localtime())
|
||||
Out[179]: 'Mon Mar 26 21:49:41 2018'
|
||||
|
||||
In [183]: time.strptime('Mon mar 04 21:53:42 2018')
|
||||
|
||||
In [182]: time.strptime('Mon mar 04 21:53:42 2018', "%a %b %d %H:%M:%S %Y")
|
||||
time.sleep(5) # 休眠 5 秒钟
|
||||
|
||||
print(time.clock()) # 精确到毫秒
|
||||
```
|
||||
|
||||
#### 3、datetime 模块
|
||||
|
||||
datetame 是 time 的升级版
|
||||
|
||||
```python
|
||||
import datetime
|
||||
In [192]: str(datetime.date.fromtimestamp(time.time()))
|
||||
Out[192]: '2018-03-26'
|
||||
|
||||
In [193]: str(datetime.datetime.now())
|
||||
Out[193]: '2018-03-26 22:09:44.424473'
|
||||
|
||||
In [194]: datetime.datetime.now() + datetime.timedelta(3)
|
||||
Out[194]: datetime.datetime(2018, 3, 29, 22, 10, 42, 315584)
|
||||
|
||||
In [196]: datetime.datetime.now() + datetime.timedelta(minutes=30)
|
||||
Out[196]: datetime.datetime(2018, 3, 26, 22, 41, 32, 44547)
|
||||
|
||||
In [15]: datetime.date.strftime(datetime.datetime.now(),'%Y-%m')
|
||||
Out[15]: '2018-04'
|
||||
|
||||
In [16]: datetime.datetime.strftime(datetime.datetime.now(),'%Y-%m')
|
||||
Out[16]: '2018-04'
|
||||
|
||||
import time,datetime
|
||||
print('返回当前时间:',datetime.datetime.now())
|
||||
显示结果:
|
||||
返回当前时间: 2017-12-19 18:13:01.974500
|
||||
|
||||
print('时间戳直接转成字符串格式: ',datetime.date.fromtimestamp(time.time()))
|
||||
显示结果:
|
||||
时间戳直接转成字符串格式: 2017-12-19
|
||||
|
||||
print('当前时间精确到微妙:',datetime.datetime.now())
|
||||
显示结果:
|
||||
当前时间精确到微妙: 2017-12-19 18:13:01.974500
|
||||
|
||||
print('当前时间+3天: ',datetime.datetime.now() + datetime.timedelta(3))
|
||||
显示结果:
|
||||
当前时间+3天: 2017-12-22 18:13:01.974500
|
||||
|
||||
print('当前时间-3天',datetime.datetime.now() + datetime.timedelta(-3))
|
||||
显示结果:
|
||||
当前时间-3天 2017-12-16 18:13:01.974500
|
||||
|
||||
print('当前时间+3小时',datetime.datetime.now() + datetime.timedelta(hours=3))
|
||||
显示结果:
|
||||
当前时间+3小时 2017-12-19 21:13:01.974500
|
||||
|
||||
print('当前时间+30分: ',datetime.datetime.now() + datetime.timedelta(minutes=30))
|
||||
显示结果:
|
||||
当前时间+30分: 2017-12-19 18:43:01.974500
|
||||
|
||||
print('当前时间+2年:',datetime.datetime.now()+datetime.timedelta(days=365*2))
|
||||
显示结果:
|
||||
当前时间+2年: 2019-12-19 18:13:01.974500
|
||||
|
||||
c_time = datetime.datetime.now()
|
||||
print('时间替换:', c_time.replace(minute=3,hour=2)) #时间替换
|
||||
显示结果:
|
||||
时间替换: 2017-12-19 02:03:01.974500
|
||||
```
|
||||
853
MD/6、Python 6.md
Normal file
853
MD/6、Python 6.md
Normal file
@ -0,0 +1,853 @@
|
||||
### 4、shutil 压缩打包模块
|
||||
|
||||
**shutil 是 Python3 中高级的文件 文件夹 压缩包 处理模块**
|
||||
|
||||
#### 1、拷贝文件
|
||||
|
||||
拷贝文件的内容到另一个文件中,参数是文件的相对路径或者绝对路径
|
||||
|
||||
```python
|
||||
import shutil
|
||||
shutil.copyfile('./src.file','./dst.file') #给目标文件命名
|
||||
```
|
||||
|
||||
#### 2、拷贝文件和权限
|
||||
|
||||
```python
|
||||
import shutil
|
||||
shutil.copy2('f1.log', 'f2.log')
|
||||
```
|
||||
|
||||
#### 3、递归拷贝
|
||||
|
||||
递归的去拷贝文件夹
|
||||
|
||||
**shutil.copytree(src, dst, symlinks=False, ignore=None)**
|
||||
|
||||
```python
|
||||
shutil.copytree('/home','/tmp/hbak',
|
||||
ignore=shutil.ignore_patterns('*.txt'))
|
||||
# 递归拷贝一个文件夹下的所有内容到另一个目录下,目标目录应该是原来系统中不存在的
|
||||
```
|
||||
|
||||
> **shutil.ignore_patterns(\*patterns)** 忽略某些文件
|
||||
>
|
||||
> **ignore=shutil.ignore_patterns('排除的文件名', '排除的文件夹名') 支持通配符,假如有多个用逗号隔开**
|
||||
|
||||
#### 4、递归删除
|
||||
|
||||
递归删除一个文件夹下的所有内容
|
||||
|
||||
```python
|
||||
shutil.rmtree('/tmp/hb')
|
||||
shutil.rmtree('/tmp/hbad/')
|
||||
|
||||
# 最后结尾的一定是明确的文件名,不可以类似下面这样
|
||||
shutil.rmtree('/tmp/hbak/*')
|
||||
```
|
||||
|
||||
#### 5、递归移动
|
||||
|
||||
递归的去移动文件,它类似mv命令。
|
||||
|
||||
```python
|
||||
shutil.move('/home/src.file', './shark')
|
||||
```
|
||||
|
||||
#### 6、压缩
|
||||
|
||||
创建压缩包并返回文件路径,例如:zip、tar
|
||||
|
||||
```python
|
||||
# 将 /home/shark 目录下的所以文件打包压缩到当前目录下,
|
||||
# 名字 shark,格式 gztar。扩展名会自动根据格式自动生成。
|
||||
|
||||
shutil.make_archive('shark', # 压缩后文件名
|
||||
'gztar', # 指定的压缩格式
|
||||
'/home/shark/') # 被压缩的文件夹名字
|
||||
|
||||
# 将 /home/shark 目录下的所以文件打包压缩到 /tmp 目录下,名字shark,格式 tar
|
||||
shutil.make_archive( '/tmp/shark','tar','/home/shark/')
|
||||
|
||||
# 查看当前 python 环境下支持的压缩格式
|
||||
ret = shutil.get_archive_formats()
|
||||
print(ret)
|
||||
```
|
||||
|
||||
#### 7、解压缩
|
||||
|
||||
```python
|
||||
# 解压的文件名 解压到哪个路径下,压缩的格式
|
||||
shutil.unpack_archive('./a/b.tar.gz', './a/c/','gztar')
|
||||
```
|
||||
|
||||
### 5、subprocess 模块执行本机系统命令
|
||||
|
||||
`os.system()` 执行的命令只是把命令的结果输出导终端,程序中无法拿到执行命令的结果。
|
||||
|
||||
`subprocess` 是开启一个系统底层的单个进程,执行 shell 命令,可以得到命令的执行结果。
|
||||
|
||||
```python
|
||||
# 在 shell 中运行命令,并且获取到标准正确输出、标准错误输出
|
||||
In [209]: subprocess.getoutput('ls |grep t')
|
||||
Out[209]: 'test.py'
|
||||
|
||||
In [222]: ret = subprocess.getstatusoutput('date -u')
|
||||
|
||||
In [223]: ret
|
||||
Out[223]: (0, '2018年 03月 26日 星期一 14:46:42 UTC')
|
||||
```
|
||||
|
||||
### 6、Python3 正则模块(标准库)
|
||||
|
||||
#### 1、常用特殊字符匹配内容
|
||||
|
||||
**字符匹配:**
|
||||
|
||||
| 正则特殊字符 | 匹配内容 |
|
||||
| ------------ | ---------------------------------- |
|
||||
| . | 匹配除换行符(\n)以外的单个任意字符 |
|
||||
| \w | 匹配单个字母、数字、汉字或下划线 |
|
||||
| \s | 匹配单个任意的空白符 |
|
||||
| \d | 匹配单个数字 |
|
||||
| \b | 匹配单词的开始或结束 |
|
||||
| ^ | 匹配整个字符串的开头 |
|
||||
| $ | 匹配整个字符串的结尾 |
|
||||
|
||||
**次数匹配:**
|
||||
|
||||
| 正则特殊字符 | 匹配内容 |
|
||||
| ------------ | ------------------------------------------------------------ |
|
||||
| * | 重复前一个字符 0 - n 次 |
|
||||
| + | 重复前一个字符 1 - n 次 |
|
||||
| ? | 重复前一个字符 0 - 1 次 |
|
||||
| {n} | 重复前一个字符 n 次 `a{2}` 匹配 `aa` |
|
||||
| {n,} | 重复前一个字符 n 次或 n 次以上 `a{2,}` 匹配 `aa` 或`aaa` 以上 |
|
||||
| {n, m} | 重复前一个字符 n 到 m 次之间的任意一个都可以 |
|
||||
|
||||
#### 2、Python 中使用正则的方法
|
||||
|
||||
- #### match
|
||||
|
||||
只在整个字符串的起始位置进行匹配
|
||||
|
||||
**示例字符串**
|
||||
|
||||
```python
|
||||
string = "isinstance yangge enumerate www.qfedu.com 1997"
|
||||
```
|
||||
|
||||
**示例演示:**
|
||||
|
||||
```python
|
||||
import re
|
||||
In [4]: r = re.match("is\w+", string)
|
||||
|
||||
In [8]: r.group() # 获取匹配成功的结果
|
||||
Out[8]: 'isinstance'
|
||||
```
|
||||
|
||||
- #### search
|
||||
|
||||
从整个字符串的开头找到最后,当第一个匹配成功后,就不再继续匹配。
|
||||
|
||||
```python
|
||||
In [9]: r = re.search("a\w+", string)
|
||||
|
||||
In [10]: r.group()
|
||||
Out[10]: 'ance'
|
||||
```
|
||||
|
||||
- #### findall
|
||||
|
||||
搜索整个字符串,找到所有匹配成功的字符串, 把这些字符串放在一个列表中返回。
|
||||
|
||||
```python
|
||||
In [16]: r = re.findall("a\w+", string)
|
||||
|
||||
In [17]: r
|
||||
Out[17]: ['ance', 'angge', 'ate']
|
||||
```
|
||||
|
||||
- #### sub
|
||||
|
||||
把匹配成功的字符串,进行替换。
|
||||
|
||||
```python
|
||||
re.sub的功能
|
||||
re是regular expression的缩写,表示正则表达式;sub是substitude的缩写,表示替换
|
||||
re.sub是正则表达式的函数,实现比普通字符串更强大的替换功能
|
||||
# 语法:
|
||||
"""
|
||||
("a\w+", "100", string, 2)
|
||||
匹配规则,替换成的新内容, 被搜索的对象, 有相同的替换次数
|
||||
"""
|
||||
sub(pattern,repl,string,count=0,flag=0)
|
||||
|
||||
1、pattern正则表达式的字符串 eg中r'\w+'
|
||||
|
||||
2、repl被替换的内容 eg中'10'
|
||||
|
||||
3、string正则表达式匹配的内容eg中"xy 15 rt 3e,gep"
|
||||
|
||||
4、count:由于正则表达式匹配的结果是多个,使用count来限定替换的个数从左向右,默认值是0,替换所有的匹配到的结果eg中2
|
||||
|
||||
5、flags是匹配模式,可以使用按位或者“|”表示同时生效,也可以在正则表达式字符串中指定
|
||||
|
||||
eg:
|
||||
In [24]: import re
|
||||
In [24]: re.sub(r'\w+','10',"xy 15 rt 3e,gep",2,flags=re.I )
|
||||
'10 10 rt 3e,gep',
|
||||
其中r'\w+'为正则表达式,匹配多个英文单词或者数字,'10'为被替换的内容,“xy 15 rt 3e,gep”是re匹配的字符串内容,count只替换前2个,flag表示忽略大小写
|
||||
|
||||
In [24]: r = re.sub("a\w+", "100", string, 2)
|
||||
|
||||
In [25]: r
|
||||
Out[25]: 'isinst100 y100 enumera www.qfedu.com 1997'
|
||||
|
||||
# 模式不匹配时,返回原来的值
|
||||
```
|
||||
|
||||
- #### split
|
||||
|
||||
以匹配到的字符进行分割,返回分割后的列表
|
||||
|
||||
```
|
||||
re.split(pattern, string, maxsplit=0, flags=0)
|
||||
|
||||
pattern compile 生成的正则表达式对象,或者自定义也可
|
||||
string 要匹配的字符串
|
||||
maxsplit 指定最大分割次数,不指定将全部分割
|
||||
|
||||
flags 标志位参数 (了解)
|
||||
re.I(re.IGNORECASE)
|
||||
使匹配对大小写不敏感
|
||||
|
||||
re.L(re.LOCAL)
|
||||
做本地化识别(locale-aware)匹配
|
||||
|
||||
re.M(re.MULTILINE)
|
||||
多行匹配,影响 ^ 和 $
|
||||
|
||||
re.S(re.DOTALL)
|
||||
使 . 匹配包括换行在内的所有字符
|
||||
|
||||
re.U(re.UNICODE)
|
||||
根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B.
|
||||
|
||||
re.X(re.VERBOSE)
|
||||
该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。
|
||||
```
|
||||
|
||||
|
||||
|
||||
```python
|
||||
In [26]: string
|
||||
Out[26]: 'isinstance yangge enumerate www.qfedu.com 1997'
|
||||
|
||||
In [27]: r = re.split("a", string, 1)
|
||||
```
|
||||
|
||||
使用多个界定符分割字符串
|
||||
|
||||
```python
|
||||
>>> line = 'asdf fjdk; afed, fjek,asdf, foo'
|
||||
>>> import re
|
||||
>>> re.split(r'[;,\s]\s*', line)
|
||||
['asdf', 'fjdk', 'afed', 'fjek', 'asdf', 'foo']
|
||||
```
|
||||
|
||||
#### 3、正则分组
|
||||
|
||||
==从已经成功匹配的内容中,再去把想要的取出来==
|
||||
|
||||
```python
|
||||
# match
|
||||
In [64]: string
|
||||
Out[64]: 'isinstance yangge enumerate www.qfedu.com 1997'
|
||||
|
||||
In [65]: r = re.match("is(\w+)", string)
|
||||
|
||||
In [66]: r.group()
|
||||
Out[66]: 'isinstance'
|
||||
|
||||
In [67]: r.groups()
|
||||
Out[67]: ('instance',)
|
||||
|
||||
In [68]: r = re.match("is(in)(\w+)", string))
|
||||
|
||||
In [69]: r.groups()
|
||||
Out[69]: ('in', 'stance')
|
||||
|
||||
# search
|
||||
# 命名分组
|
||||
In [87]: r = re.search("is\w+\s(?P<name>y\w+e)", string)
|
||||
|
||||
In [88]: r.group()
|
||||
Out[88]: 'isinstance yangge'
|
||||
|
||||
In [89]: r.groups()
|
||||
Out[89]: ('yangge',)
|
||||
6
|
||||
In [90]: r.groupdict()
|
||||
Out[90]: {'name': 'yangge'}
|
||||
8
|
||||
|
||||
# findall
|
||||
In [98]: string
|
||||
Out[98]: 'isinstance all yangge any enumerate www.qfedu.com 1997'
|
||||
|
||||
In [99]: r = re.findall("a(?P<name>\w+)", string)
|
||||
|
||||
In [100]: r
|
||||
Out[100]: ['nce', 'll', 'ngge', 'ny', 'te']
|
||||
|
||||
In [101]: r = re.findall("a(\w+)", string)
|
||||
|
||||
In [102]: r
|
||||
Out[102]: ['nce', 'll', 'ngge', 'ny', 'te']
|
||||
|
||||
|
||||
# split
|
||||
In [113]: string
|
||||
Out[113]: 'isinstance all yangge any enumerate www.qfedu.com 1997'
|
||||
|
||||
In [114]: r = re.split("(any)", string)
|
||||
|
||||
In [115]: r
|
||||
Out[115]: ['isinstance all yangge ', 'any', ' enumerate www.qfedu.com 1997']
|
||||
|
||||
In [116]: r = re.split("(a(ny))", string)
|
||||
|
||||
In [117]: r
|
||||
Out[117]:
|
||||
['isinstance all yangge ',
|
||||
'any',
|
||||
'ny',
|
||||
' enumerate www.qfedu.com 1997']
|
||||
|
||||
In [118]: tag = 'value="1997/07/01"'
|
||||
|
||||
In [119]: s = re.sub(r'(value="\d{4})/(\d{2})/(\d{2}")', r'\1-\2-\3', tag)
|
||||
|
||||
In [120]: s
|
||||
Out [120]: value="1997-07-01"
|
||||
```
|
||||
|
||||
- #### 编译正则
|
||||
|
||||
对于程序频繁使用的表达式,编译这些表达式会更有效。
|
||||
|
||||
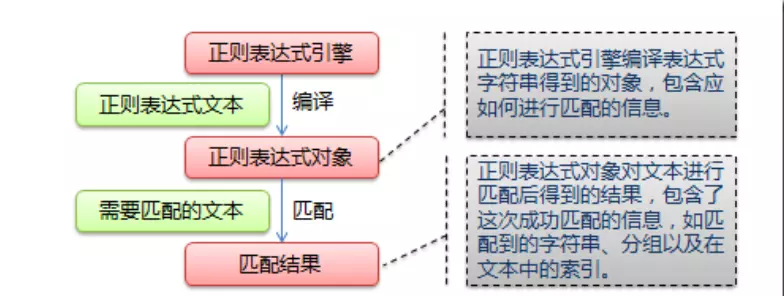
compile 函数用于编译正则表达式,返回的是一个正则表达式( Pattern )对象,利用这个对象的相关方法再去匹配字符串。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
**好处:**
|
||||
|
||||
re 模块会维护已编译表达式的一个缓存。
|
||||
|
||||
不过,这个缓存的大小是有限的,直接使用已编译的表达式可以避免缓存查找开销。
|
||||
|
||||
使用已编译表达式的另一个好处是,通过在加载模块时预编译所有表达式,可以把编译工作转到应用 一开始时,而不是当程序响应一个用户动作时才进行编译。
|
||||
|
||||
```python
|
||||
In [130]: regexes = re.compile("y\w+")
|
||||
|
||||
In [131]: r = regexes.search(string)
|
||||
|
||||
In [132]: r.group()
|
||||
Out[132]: 'yangge'
|
||||
```
|
||||
|
||||
- #### 常用正则
|
||||
|
||||
```python
|
||||
# IP:
|
||||
r"\b(?:[0-9]{1,3}\.){3}[0-9]{1,3}\b"
|
||||
# 手机号:
|
||||
r'\b1[3|4|5|6|7|8|9][0-9]\d{8}'
|
||||
# 邮箱:
|
||||
shark123@qq.com
|
||||
shark123@163.com
|
||||
r'[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(.[a-zA-Z0-9_-]+)+'
|
||||
```
|
||||
|
||||
- #### 强调知识点
|
||||
|
||||
```python
|
||||
# 匹配所有包含小数在内的数字
|
||||
print(re.findall('\d+\.?\d*',"asdfasdf123as1.13dfa12adsf1asdf3")) #['123', '1.13', '12', '1', '3']
|
||||
|
||||
#.*默认为贪婪匹配
|
||||
print(re.findall('a.*b','a1b22222222b'))
|
||||
#['a1b22222222b']
|
||||
|
||||
#.*?为非贪婪匹配:推荐使用
|
||||
print(re.findall('a.*?b','a1b22222222b'))
|
||||
#['a1b']
|
||||
```
|
||||
|
||||
- #### 元字符
|
||||
|
||||
```python
|
||||
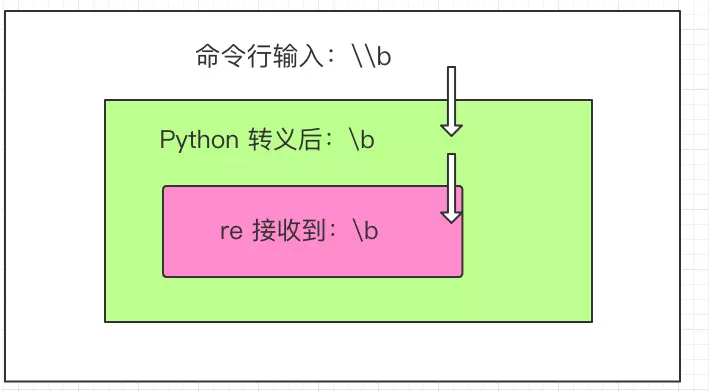
# \b 表示匹配单词边界,详见后面的速查表
|
||||
|
||||
In [17]: re.search('hello\b', 'hello world')
|
||||
|
||||
In [18]: re.search('hello\\b', 'hello world')
|
||||
Out[18]: <_sre.SRE_Match object; span=(0, 5), match='hello'>
|
||||
```
|
||||
|
||||
|
||||
|
||||
**Python 自己也有转义**
|
||||
|
||||
**使用 r 禁止 Python 转义**
|
||||
|
||||
```python
|
||||
In [19]: re.search(r'hello\b', 'hello world')
|
||||
Out[19]: <_sre.SRE_Match object; span=(0, 5), match='hello'>
|
||||
```
|
||||
|
||||
- #### 扩展知识点
|
||||
|
||||
最后一个参数 **flag**
|
||||
|
||||
可选值有:
|
||||
|
||||
```python
|
||||
re.I # 忽略大小写
|
||||
```
|
||||
|
||||
示例:
|
||||
|
||||
```python
|
||||
In [186]: s1 = string.capitalize()
|
||||
|
||||
In [187]: s1
|
||||
Out[187]: 'Isinstance all yangge any enumerate www.qfedu.com 1997'
|
||||
|
||||
In [192]: r = re.search('is',s, re.I)
|
||||
Out[192]: <_sre.SRE_Match object; span=(0, 2), match='Is'>
|
||||
```
|
||||
|
||||
#### 4、正则模式速查表
|
||||
|
||||
| 模式 | 描述 |
|
||||
| ----------- | ------------------------------------------------------------ |
|
||||
| ^ | 匹配字符串的开头 |
|
||||
| $ | 匹配字符串的末尾。 |
|
||||
| . | 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。 |
|
||||
| [...] | 用来表示一组字符,单独列出:[amk] 匹配 'a','m'或'k' |
|
||||
| [^...] | 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。 |
|
||||
| re* | 匹配0个或多个的表达式。 |
|
||||
| re+ | 匹配1个或多个的表达式。 |
|
||||
| re? | 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 |
|
||||
| re{ n} | 匹配n个前面表达式。。例如,"o{2}"不能匹配"Bob"中的"o",但是能匹配"food"中的两个o。 |
|
||||
| re{n,} | 精确匹配n个前面表达式。例如,"o{2,}"不能匹配"Bob"中的"o",但能匹配"foooood"中的所有o。"o{1,}"等价于"o+"。"o{0,}"则等价于"o*"。 |
|
||||
| re{n,m} | 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式 |
|
||||
| a\| b | 匹配a或b |
|
||||
| (re) | 匹配括号内的表达式,也表示一个组 |
|
||||
| (?imx) | 正则表达式包含三种可选标志:i, m, 或 x 。只影响括号中的区域。 |
|
||||
| (?-imx) | 正则表达式关闭 i, m, 或 x 可选标志。只影响括号中的区域。 |
|
||||
| (?: re) | 类似 (...), 但是不表示一个组 |
|
||||
| (?imx: re) | 在括号中使用i, m, 或 x 可选标志 |
|
||||
| (?-imx: re) | 在括号中不使用i, m, 或 x 可选标志 |
|
||||
| (?#...) | 注释. |
|
||||
| (?= re) | 前向肯定界定符。如果所含正则表达式,以 ... 表示,在当前位置成功匹配时成功,否则失败。但一旦所含表达式已经尝试,匹配引擎根本没有提高;模式的剩余部分还要尝试界定符的右边。 |
|
||||
| (?! re) | 前向否定界定符。与肯定界定符相反;当所含表达式不能在字符串当前位置匹配时成功 |
|
||||
| (?> re) | 匹配的独立模式,省去回溯。 |
|
||||
| \w | 匹配字母数字及下划线 |
|
||||
| \W | 匹配非字母数字及下划线 |
|
||||
| \s | 匹配任意空白字符,等价于 [\t\n\r\f]. |
|
||||
| \S | 匹配任意非空字符 |
|
||||
| \d | 匹配任意数字,等价于 [0-9]. |
|
||||
| \D | 匹配任意非数字 |
|
||||
| \A | 匹配字符串开始 |
|
||||
| \Z | 匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。 |
|
||||
| \z | 匹配字符串结束 |
|
||||
| \G | 匹配最后匹配完成的位置。 |
|
||||
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 |
|
||||
| \B | 匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 |
|
||||
| \n, \t, 等. | 匹配一个换行符。匹配一个制表符。等 |
|
||||
| \1...\9 | 匹配第n个分组的内容。 |
|
||||
| \10 | 匹配第n个分组的内容,如果它经匹配。否则指的是八进制字符码的表达式。 |
|
||||
|
||||
### 7、Python3 邮件模块
|
||||
|
||||
**使用第三方库 `yagmail`**
|
||||
|
||||
------
|
||||
|
||||
> 更新: 第三种方式的隐藏用户名和密码的方式,目前不再支持
|
||||
|
||||
------
|
||||
|
||||
#### 1、简单介绍 yagmail
|
||||
|
||||
目标是尽可能简单,无痛地发送电子邮件。
|
||||
|
||||
最终的代码如下:
|
||||
|
||||
```python
|
||||
import yagmail
|
||||
yag = yagmail.SMTP()
|
||||
contents = ['This is the body, and here is just text http://somedomain/image.png',
|
||||
'You can find an audio file attached.', '/local/path/song.mp3']
|
||||
yag.send('to@someone.com', '邮件标题', contents)
|
||||
```
|
||||
|
||||
或者在一行中实现:
|
||||
|
||||
```python
|
||||
yagmail.SMTP('mygmailusername').send('to@someone.com', 'subject', 'This is the body')
|
||||
```
|
||||
|
||||
当然, 以上操作需要从你自己系统的密钥环中读取你的邮箱账户和对应的密码。关于密钥环稍后会提到如何实现。
|
||||
|
||||
#### 2、安装模块
|
||||
|
||||
```shell
|
||||
pip3 install yagmail # linux / Mac
|
||||
pip install yagmail # windows
|
||||
```
|
||||
|
||||
这样会安装最新的版本,并且会支持所有最新功能,主要是支持从密钥环中获取到邮箱的账户和密码。
|
||||
|
||||
#### 3、关于账户和密码
|
||||
|
||||
**开通自己邮箱的 `SMTP` 功能,并获取到授权码**
|
||||
|
||||
这个账户是你要使用此邮箱发送邮件的账户,密码不是平时登录邮箱的密码,而是开通 `POP3/SMTP` 功能后设置的客户端授权密码。
|
||||
|
||||
这里以 `126` 邮箱为例:
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
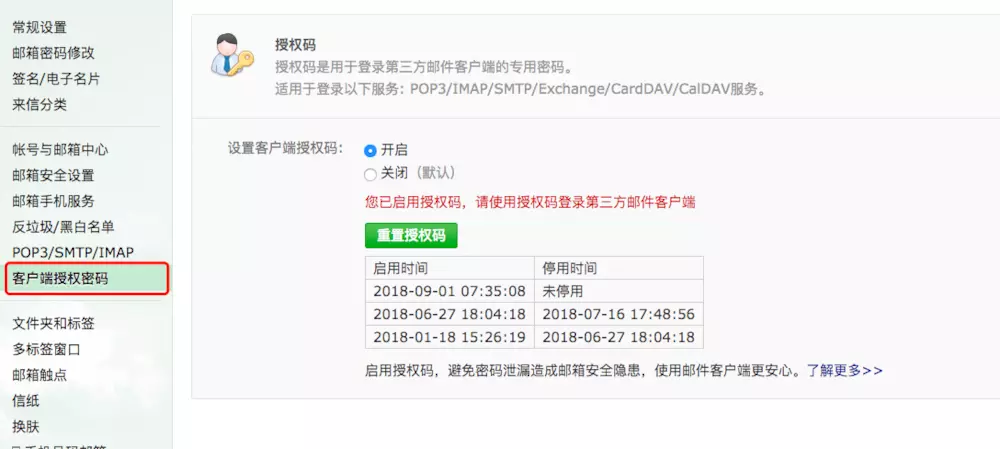
|
||||
|
||||
#### 4、方式一:不使用系统的密钥环
|
||||
|
||||
不使用系统的密钥环,可以直接暴露账户和密码在脚本里
|
||||
|
||||
```python
|
||||
import yagmail
|
||||
yag = yagmail.SMTP(
|
||||
user='自己的账号',
|
||||
password='账号的授权码',
|
||||
host='smtp.qq.com', # 邮局的 smtp 地址
|
||||
port='端口号', # 邮局的 smtp 端口
|
||||
smtp_ssl=False)
|
||||
|
||||
yag.send(to='收件箱账号',
|
||||
subject='邮件主题',
|
||||
contents='邮件内容')
|
||||
```
|
||||
|
||||
#### 5、方式二: 使用系统的密钥环管理账户和授权码
|
||||
|
||||
模块支持从当前系统环境中的密钥环中获取账户和密码,要想实现这个功能,需要依赖模块 `keyring`。之后把账户和密码注册到系统的密钥环中即可实现。
|
||||
|
||||
**1. 安装依赖模块**
|
||||
|
||||
```python
|
||||
pip3 install keyring
|
||||
|
||||
# CentOS7.3 还需要安装下面的模块
|
||||
pip3 install keyrings.alt
|
||||
```
|
||||
|
||||
**2. 开始向密钥环注册**
|
||||
|
||||
```python
|
||||
import yagmail
|
||||
yagmail.register('你的账号', '你的授权密码')
|
||||
```
|
||||
|
||||
> 注册账户和密码,只需要执行一次即可。
|
||||
|
||||
**3. 发送邮件**
|
||||
|
||||
```python
|
||||
import yagmail
|
||||
|
||||
yag = yagmail.SMTP('自己的账号',
|
||||
host='smtp.qq.com', # 邮局的 smtp 地址
|
||||
port='端口号', # 邮局的 smtp 端口
|
||||
smtp_ssl=False # 不使用加密传输
|
||||
)
|
||||
|
||||
yag.send(
|
||||
to='收件箱账号',
|
||||
subject='邮件主题',
|
||||
contents='邮件内容')
|
||||
```
|
||||
|
||||
#### 6、示例展示
|
||||
|
||||
下面是以我的 126 邮箱为例, 使用系统密钥环的方式,向我的 163邮箱发送了一封邮件。
|
||||
|
||||
```python
|
||||
import yagmail
|
||||
|
||||
yag = yagmail.SMTP(user='shark@126.com',
|
||||
host='smtp.126.com',
|
||||
port=25,
|
||||
smtp_ssl=False)
|
||||
yag.send(to='docker@163.com',
|
||||
subject='from shark',
|
||||
contents='test')
|
||||
```
|
||||
|
||||
这样就愉快的发送了一封测试邮件到 `docker@163.com` 的邮箱。
|
||||
|
||||
当然前提是:
|
||||
|
||||
1. 126 邮箱开通了 `SMTP`功能。
|
||||
2. 把 126 邮箱的账号和密码已经注册到自己系统的密钥环中。
|
||||
|
||||
#### 7、发送附件
|
||||
|
||||
**发送**
|
||||
|
||||
发送附件只需要给 `send`方法传递 `attachments` 关键字参数
|
||||
|
||||
比如我在系统的某一个目录下有一张图片,需要发送给 `docker@163.com`
|
||||
|
||||
```python
|
||||
import yagmail
|
||||
|
||||
yag = yagmail.SMTP(user='shark@126.com',
|
||||
host='smtp.126.com',
|
||||
port=25,
|
||||
smtp_ssl=False)
|
||||
yag.send(to='docker@163.com',
|
||||
subject='from shark',
|
||||
contents='test',
|
||||
attachments='./松鼠.jpeg')
|
||||
```
|
||||
|
||||
#### 8、收到的邮件和附件
|
||||
|
||||
|
||||
|
||||
image.png
|
||||
|
||||
#### 9、使用 `ssl` 发送加密邮件
|
||||
|
||||
要发送加密邮件,只需要把 `smtp_ssl` 关键字参数去掉即可,因为默认就是采用的加密方式 `smtp_ssl=True`。
|
||||
|
||||
不传递 `stmp_ssl` 关键字参数的同时,需要设置端口为邮箱服务提供商的加密端口,这里还是以 126 邮箱为例,端口是 `465`。
|
||||
|
||||
```python
|
||||
import yagmail
|
||||
|
||||
yag = yagmail.SMTP(user='shark@126.com',
|
||||
host='smtp.126.com',
|
||||
port=465)
|
||||
yag.send(to='docker@163.com',
|
||||
subject='from sharkyunops',
|
||||
contents='test',
|
||||
attachments='./松鼠.jpeg')
|
||||
```
|
||||
|
||||
#### 10、发送 带 html 标记语言的邮件内容
|
||||
|
||||
在实际的生产环境中,经常会发送邮件沟通相关事宜,往往会有表格之类的内容,但是又不想以附件的形式发送,就可以利用 html 标记语言的方式组织数据。
|
||||
|
||||
```python
|
||||
import yagmail
|
||||
|
||||
yag = yagmail.SMTP(user='shark@126.com',
|
||||
host='smtp.126.com',
|
||||
port=465)
|
||||
|
||||
html="""<table border="1">
|
||||
<thead>
|
||||
<tr>
|
||||
<th>姓名</th>
|
||||
<th>年龄</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td>shak</td>
|
||||
<td>18</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>西瓜甜</td>
|
||||
<td>28</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
"""
|
||||
|
||||
yag.send(to='docker@163.com',
|
||||
subject='from sharkyunops',
|
||||
contents=['test',html])
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### 11、更多
|
||||
|
||||
如果不指定`to`参数,则发送给自己
|
||||
|
||||
如果`to`参数是一个列表,则将该邮件发送给列表中的所有用户
|
||||
|
||||
`attachments` 参数的值可以是列表,表示发送多个附件
|
||||
|
||||
### 8、Python3 paramiko 模块
|
||||
|
||||
Paramiko 模块提供了基于ssh连接,进行远程登录服务器执行命令和上传下载文件的功能。这是一个第三方的软件包,使用之前需要安装。
|
||||
|
||||
#### 1、安装
|
||||
|
||||
```
|
||||
pip3 install paramiko
|
||||
```
|
||||
|
||||
#### 2、执行命令
|
||||
|
||||
##### 1、基于用户名和密码的连接
|
||||
|
||||
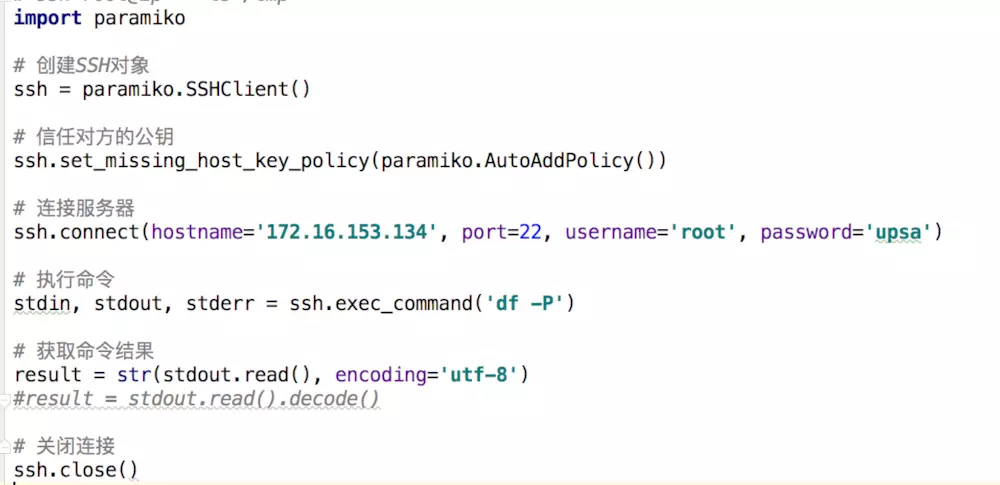
|
||||
|
||||
**封装 Transport**
|
||||
|
||||
```python
|
||||
import paramiko
|
||||
#实例化一个transport(传输)对象
|
||||
transport = paramiko.Transport(('172.16.32.129',2323))
|
||||
#建立连接
|
||||
transport.connect(username='root',password='123')
|
||||
#建立ssh对象
|
||||
ssh = paramiko.SSHClient()
|
||||
#绑定transport到ssh对象
|
||||
ssh._transport=transport
|
||||
#执行命令
|
||||
stdin,stdout,stderr=ssh.exec_command('df')
|
||||
#打印输出
|
||||
print(stdout.read().decode())
|
||||
#关闭连接
|
||||
transport.close()
|
||||
|
||||
import paramiko
|
||||
transport = paramiko.Transport(('172.16.153.134', 22))
|
||||
transport.connect(username='root', password='upsa')
|
||||
|
||||
ssh = paramiko.SSHClient()
|
||||
ssh._transport = transport
|
||||
|
||||
stdin, stdout, stderr = ssh.exec_command('df -P')
|
||||
print(stdout.read().decode())
|
||||
|
||||
transport.close()
|
||||
```
|
||||
|
||||
##### 2. 基于公钥秘钥连接
|
||||
|
||||
**一定要先建立公钥信任**
|
||||
|
||||
```python
|
||||
#创建密钥对,建立密钥信任,必须先将公钥文件传输到服务器的~/.ssh/authorized_keys中
|
||||
ssh-keygen
|
||||
ssh-copy-id 192.168.95.154
|
||||
|
||||
#!/usr/local/bin/pyton3
|
||||
#coding:utf8
|
||||
import paramiko
|
||||
# 指定本地的RSA私钥文件,如果建立密钥对时设置的有密码,password为设定的密码,如无不用指定password参数
|
||||
pkey = paramiko.RSAKey.from_private_key_file('id_rsa')
|
||||
#建立连接
|
||||
ssh = paramiko.SSHClient()
|
||||
#允许将信任的主机自动加入到known_hosts列表
|
||||
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
|
||||
ssh.connect(hostname='172.16.32.129',port=22,username='root',pkey=pkey) #指定密钥连接
|
||||
#执行命令
|
||||
stdin,stdout,stderr=ssh.exec_command('free -m')
|
||||
print(stdout.read().decode())
|
||||
ssh.close()
|
||||
|
||||
注意:
|
||||
import paramiko
|
||||
client = paramiko.SSHClient()
|
||||
client.connect(serverIp, port=serverPort, username=serverUser)
|
||||
|
||||
报警告如下:
|
||||
paramiko\ecdsakey.py:164: CryptographyDeprecationWarning: Support for unsafe construction of public numbers from encoded data will be removed in a future version. Please use EllipticCurvePublicKey.from_encoded_point
|
||||
self.ecdsa_curve.curve_class(), pointinfo
|
||||
paramiko\kex_ecdh_nist.py:39: CryptographyDeprecationWarning: encode_point has been deprecated on EllipticCurvePublicNumbers and will be removed in a future version. Please use EllipticCurvePublicKey.public_bytes to obtain both compressed and uncompressed point encoding.
|
||||
m.add_string(self.Q_C.public_numbers().encode_point())
|
||||
paramiko\kex_ecdh_nist.py:96: CryptographyDeprecationWarning: Support for unsafe construction of public numbers from encoded data will be removed in a future version. Please use EllipticCurvePublicKey.from_encoded_point
|
||||
self.curve, Q_S_bytes
|
||||
paramiko\kex_ecdh_nist.py:111: CryptographyDeprecationWarning: encode_point has been deprecated on EllipticCurvePublicNumbers and will be removed in a future version. Please use EllipticCurvePublicKey.public_bytes to obtain both compressed and uncompressed point encoding.
|
||||
hm.add_string(self.Q_C.public_numbers().encode_point())
|
||||
原因
|
||||
paramiko 2.4.2 依赖 cryptography,而最新的cryptography==2.5里有一些弃用的API。
|
||||
|
||||
解决
|
||||
删掉cryptography 2.5,安装2.4.2,就不会报错了。
|
||||
|
||||
pip uninstall cryptography==2.5
|
||||
pip install cryptography==2.4.2
|
||||
|
||||
```
|
||||
|
||||
#### 2、文件上传下载
|
||||
|
||||
**SFTPClient:**
|
||||
|
||||
用于连接远程服务器并进行上传下载功能。
|
||||
|
||||
下面的命令可以快速创建密钥对,并用 -t 指定了算法类型为 ecdsa
|
||||
|
||||
ssh-keygen -t ecdsa -N ""
|
||||
ssh-keygen
|
||||
ssh-copy-id 192.168.95.154
|
||||
|
||||
##### 1、基于用户名密码上传下载
|
||||
|
||||
```python
|
||||
import paramiko
|
||||
transport = paramiko.Transport(('10.18.46.104',22))
|
||||
transport.connect(username='root',password='123.com')
|
||||
#paramiko.SSHClient()
|
||||
sftp = paramiko.SFTPClient.from_transport(transport)
|
||||
|
||||
# 将ssh-key.py 上传至服务器 /tmp/ssh-key.py
|
||||
sftp.put('ssh-key.py', '/tmp/ssh-key.txt') # 后面指定文件名称
|
||||
|
||||
# 将远程主机的文件 /tmp/ssh-key.py 下载到本地并命名为 ssh-key.txt
|
||||
sftp.get('/tmp/ssh-key.py', 'ssh-key.txt')
|
||||
|
||||
transport.close()
|
||||
```
|
||||
|
||||
##### 2、基于公钥秘钥上传下载
|
||||
|
||||
```python
|
||||
import paramiko
|
||||
|
||||
# 创建一个本地当前用户的私钥对象
|
||||
#private_key = paramiko.ECDSAKey.from_private_key_file('/root/.ssh/id_ecdsa')
|
||||
private_key = paramiko.RSAKey.from_private_key_file('/root/.ssh/id_rsa')
|
||||
# 创建一个传输对象
|
||||
transport = paramiko.Transport(('10.18.46.104',22))
|
||||
|
||||
# 使用刚才的传输对象创建一个传输文件的的连接对象
|
||||
transport.connect(username='root', pkey=private_key)
|
||||
|
||||
sftp = paramiko.SFTPClient.from_transport(transport)
|
||||
|
||||
# 将ssh-key.py 上传至服务器 /tmp/ssh-key.py
|
||||
sftp.put('ssh-key.py', '/tmp/ssh-key.txt')
|
||||
|
||||
# 将远程主机的文件 /tmp/test.py 下载到本地并命名为 some.py
|
||||
sftp.get('/tmp/ssh-key.py', 'ssh-key.txt')
|
||||
transport.close()
|
||||
```
|
||||
546
MD/7、Python 7.md
Normal file
546
MD/7、Python 7.md
Normal file
@ -0,0 +1,546 @@
|
||||
## 十九、Python3 操作数据库
|
||||
|
||||
### 1、Python3 操作 MySQL
|
||||
|
||||
#### 1、基本介绍
|
||||
|
||||
- Python3 操作 MySQL 数据库 可以使用的模块是 `pymysql` 和 `MySQLdb`。
|
||||
|
||||
- 这个两个模块都是通过自己的 API 执行原生的 SQL 语句实现的。
|
||||
|
||||
- MySQLdb 是最早出现的一个操作 MySQL 数据库的模块,核心由C语言编写,接口精炼,性能最棒,缺点是环境依赖较多,安装稍复杂,近两年已停止更新,且只支持Python2.x,不支持Python3.x。
|
||||
|
||||
- `pymysql` 为替代 `MySQLdb` 而生,纯 `Python` 实现,API 的接口与 `MySQLdb` 完全兼容,安装方便,支持Python3。
|
||||
|
||||
- 2020 已经离我们很近了,所以,我们这里只聊 `pymysql`
|
||||
|
||||
#### 2、 安装包 `pymysql`
|
||||
|
||||
pymysql是Python中操作MySQL的模块(Linux 机器)
|
||||
|
||||
```shell
|
||||
pip3 install pymysql
|
||||
```
|
||||
|
||||
#### 3、 基本操作
|
||||
|
||||
##### 1、创建表
|
||||
|
||||
```python
|
||||
import pymysql
|
||||
创建连接
|
||||
conn = pymysql.connect(host='172.16.153.10',
|
||||
port=3306,
|
||||
user='root',
|
||||
passwd='123',
|
||||
db='shark_db',
|
||||
charset='utf8mb4')
|
||||
mysql -uroot -p'password' -h host_ip databasename
|
||||
|
||||
获取游标对象
|
||||
cursor = conn.cursor()
|
||||
mysql>
|
||||
定义 sql 语句
|
||||
create_table_sql = """create table test1
|
||||
(id int auto_increment primary key,
|
||||
name varchar(10) not null,
|
||||
age int not null)"""
|
||||
|
||||
执行 sql 语句
|
||||
cursor.execute(create_table_sql)
|
||||
mysql>select * from mysql.user
|
||||
提交
|
||||
conn.commit()
|
||||
commit;
|
||||
关闭游标对象
|
||||
cursor.close()
|
||||
exit()
|
||||
关闭连接对象
|
||||
conn.close()
|
||||
exit()
|
||||
```
|
||||
|
||||
##### 2、插入数据
|
||||
|
||||
**一次插入一条数据**
|
||||
|
||||
```python
|
||||
一次插入一条数据, 并且使用变量占位符
|
||||
insert_data_sql = "insert into t1(name, age) values(%s, %s);"
|
||||
row = cursor.execute(insert_data_sql, ('shark', 18))
|
||||
conn.commit()
|
||||
cursor.close()
|
||||
conn.close()
|
||||
|
||||
```
|
||||
|
||||
**一次插入多条数据**
|
||||
|
||||
```python
|
||||
定义插入数据的语句
|
||||
many_sql = "insert into t1 (name, age) values(%s, %s)"
|
||||
|
||||
一次插入多条数据
|
||||
row = cursor.executemany(many_sql, [('shark1', 18),('xiguatian', 20),('qf', 8)])
|
||||
|
||||
conn.commit()
|
||||
cursor.close()
|
||||
conn.close()
|
||||
```
|
||||
|
||||
##### 3、查询数据
|
||||
|
||||
###### 1、**获取到的数据是元组类型**
|
||||
|
||||
```python
|
||||
定义一个查询语句
|
||||
query_sql = "select id,name,age from t1 where name=%s;"
|
||||
|
||||
执行查询语句,并且返回得到结果的行数
|
||||
row_nums = cursor.execute(query_sql, ('shark2'))
|
||||
|
||||
"""
|
||||
获取到数据结果集具有迭代器的特性:
|
||||
1. 可以通过索引取值,可以切片
|
||||
2. 结果集中的数据每次取出一条就少一条
|
||||
"""
|
||||
|
||||
获取数据中的第一条
|
||||
one_data = cursor.fetchone()
|
||||
|
||||
获取数据中的指定数量的条目
|
||||
many_data = cursor.fetchmany(2)
|
||||
|
||||
获取数据中剩余的全部数据
|
||||
all_data = cursor.fetchall()
|
||||
|
||||
cursor.close()
|
||||
conn.close()
|
||||
print(row_nums)
|
||||
print(one_data)
|
||||
print(many_data)
|
||||
print(all_data)
|
||||
```
|
||||
|
||||
###### 2、**获取到的数据是字典类型的**
|
||||
|
||||
```python
|
||||
游标设置为字典类型
|
||||
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
|
||||
|
||||
query_sql = "select id,name,age from t1 where name=%s;"
|
||||
|
||||
row_nums = cursor.execute(query_sql, ('shark2'))
|
||||
|
||||
获取结果的操作和之前的一样
|
||||
result = cursor.fetchone()
|
||||
conn.commit()
|
||||
cursor.close()
|
||||
conn.close()
|
||||
|
||||
print(result)
|
||||
```
|
||||
|
||||
#### 4、应该加入异常处理
|
||||
|
||||
```python
|
||||
import pymysql
|
||||
|
||||
# 创建连接
|
||||
conn = pymysql.connect(host='172.16.153.10',
|
||||
port=3306,
|
||||
user='root',
|
||||
passwd='123',
|
||||
db='shark_db')
|
||||
|
||||
# 创建游标
|
||||
cursor = conn.cursor()
|
||||
|
||||
try:
|
||||
cursor.executemany("INSERT INTO para5(name,age) VALUES(%s,%s);", [('次牛444', '12'), ("次牛2", '11'), ('次牛3', '10')])
|
||||
conn.commit()
|
||||
except Exception as e:
|
||||
# 如果执行sql语句出现问题,则执行回滚操作
|
||||
conn.rollback()
|
||||
print(e)
|
||||
finally:
|
||||
# 不论try中的代码是否抛出异常,
|
||||
# 这里都会执行关闭游标和数据库连接
|
||||
cursor.close()
|
||||
conn.close()
|
||||
```
|
||||
|
||||
#### 5、 获取新增数据的自增 ID
|
||||
|
||||
```python
|
||||
# 先连接
|
||||
cursor = conn.cursor()
|
||||
cursor.executemany("insert into student(name,age, phone)values(%s,%s, %s)",
|
||||
[ ("superman5110",18, '13295686769')] )
|
||||
conn.commit()
|
||||
cursor.close()
|
||||
conn.close()
|
||||
|
||||
# 获取最新自增ID
|
||||
new_id = cursor.lastrowid
|
||||
```
|
||||
|
||||
#### 6、操作存储过程(扩展)
|
||||
|
||||
**无参数存储过程**
|
||||
|
||||
```
|
||||
cursor.callproc('p1') #等价于cursor.execute("call p1()")
|
||||
```
|
||||
|
||||
**有参存储过程**
|
||||
|
||||
```python
|
||||
cursor.callproc('p2', args=(1, 22, 3, 4))
|
||||
|
||||
#获取执行完存储的参数,参数@开头
|
||||
cursor.execute("select @p2,@_p2_1,@_p2_2,@_p2_3") #{'@_p2_1': 22, '@p2': None, '@_p2_2': 103, '@_p2_3': 24}
|
||||
|
||||
|
||||
row_1 = cursor.fetchone()
|
||||
```
|
||||
|
||||
## 二十、异常处理
|
||||
|
||||
### 1、什么是异常
|
||||
|
||||
异常就是程序运行时发生错误的信号(在程序出现错误时,则会产生一个异常,若程序没有处理它,则会抛出该异常,程序的运行也随之终止),所以,在编程过程中为了增加友好性,在程序出现bug时一般不会将错误信息显示给用户,而是现实一个提示的页面或者信息,在python中,错误触发的异常如下:
|
||||
|
||||
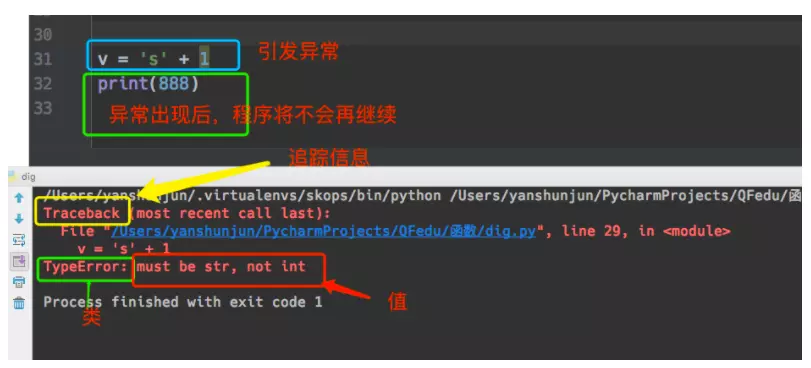
|
||||
|
||||
### 2、而错误分成以下两种情况
|
||||
|
||||
#### 1、语法错误
|
||||
|
||||
```python
|
||||
#语法错误一
|
||||
if
|
||||
#语法错误二
|
||||
def test:
|
||||
pass
|
||||
#语法错误三
|
||||
class Foo
|
||||
pass
|
||||
#语法错误四
|
||||
print(haha
|
||||
```
|
||||
|
||||
#### 2、非语法错误
|
||||
|
||||
```python
|
||||
# TypeError:int类型不可迭代
|
||||
for i in 3:
|
||||
pass
|
||||
|
||||
# ValueError
|
||||
inp=input(">>: ") # 输入 qf
|
||||
int(inp)
|
||||
|
||||
# NameError
|
||||
aaa
|
||||
|
||||
# IndexError
|
||||
l=['yangge','aa']
|
||||
l[3]
|
||||
|
||||
# KeyError
|
||||
dic={'name':'yangge'}
|
||||
dic['age']
|
||||
|
||||
# AttributeError
|
||||
class Foo:
|
||||
pass
|
||||
Foo.x
|
||||
|
||||
# ZeroDivisionError:无法完成计算
|
||||
res1=1/0
|
||||
```
|
||||
|
||||
### 3、异常的种类
|
||||
|
||||
在python中不同的异常可以用不同的类型(python3中统一了类与类型,类型即类)去标识,一个异常标识一种错误,python中的异常种类非常多,每个异常专门用于处理某一项异常
|
||||
|
||||
```python
|
||||
# 试图访问一个对象没有的属性,比如foo.x,但是foo没有属性x
|
||||
AttributeError
|
||||
|
||||
# 输入/输出异常;基本上是无法打开文件
|
||||
IOError
|
||||
|
||||
# 无法导入模块或包;基本上是路径问题或名称错误
|
||||
ImportError
|
||||
|
||||
# 语法错误(的子类) ;代码没有正确对齐
|
||||
IndentationError
|
||||
|
||||
# 下标索引超出序列边界,比如当 li 只有三个元素,却试图访问 li[5]
|
||||
IndexError
|
||||
|
||||
# 试图访问字典里不存在的键
|
||||
KeyError
|
||||
|
||||
# 按了一下 Ctrl+C
|
||||
KeyboardInterrupt
|
||||
|
||||
# 使用一个还未被赋予对象的变量
|
||||
NameError
|
||||
|
||||
# 无效语法,语法错误
|
||||
SyntaxError
|
||||
|
||||
# 传入对象类型不符合要求,如sum 函数需要的是 int,但你传入了 str
|
||||
TypeError
|
||||
|
||||
# 试图访问一个还未被设置的局部变量,基本上是由于另有一个同名的全局变量,导致你以为正在访问它
|
||||
UnboundLocalError
|
||||
# 例如:
|
||||
"""
|
||||
x = 1
|
||||
def func():
|
||||
x += 1
|
||||
return x
|
||||
|
||||
func()
|
||||
|
||||
UnboundLocalError: local variable 'x' referenced before assignment
|
||||
# 局部变量 x 在赋值之前被引用
|
||||
"""
|
||||
|
||||
# 传入一个调用者不期望的值,即使值的类型是正确的,比如 int('a')
|
||||
ValueError
|
||||
|
||||
#python中全部的异常类型
|
||||
ArithmeticError
|
||||
AssertionError
|
||||
AttributeError
|
||||
BaseException
|
||||
BufferError
|
||||
BytesWarning
|
||||
DeprecationWarning
|
||||
EnvironmentError
|
||||
EOFError
|
||||
Exception
|
||||
FloatingPointError
|
||||
FutureWarning
|
||||
GeneratorExit
|
||||
ImportError
|
||||
ImportWarning
|
||||
IndentationError
|
||||
IndexError
|
||||
IOError
|
||||
KeyboardInterrupt
|
||||
KeyError
|
||||
LookupError
|
||||
MemoryError
|
||||
NameError
|
||||
NotImplementedError
|
||||
OSError
|
||||
OverflowError
|
||||
PendingDeprecationWarning
|
||||
ReferenceError
|
||||
RuntimeError
|
||||
RuntimeWarning
|
||||
StandardError
|
||||
StopIteration
|
||||
SyntaxError
|
||||
SyntaxWarning
|
||||
SystemError
|
||||
SystemExit
|
||||
TabError
|
||||
TypeError
|
||||
UnboundLocalError
|
||||
UnicodeDecodeError
|
||||
UnicodeEncodeError
|
||||
UnicodeError
|
||||
UnicodeTranslateError
|
||||
UnicodeWarning
|
||||
UserWarning
|
||||
ValueError
|
||||
Warning
|
||||
ZeroDivisionError
|
||||
```
|
||||
|
||||
### 4、异常处理
|
||||
|
||||
为了保证程序的健壮性与容错性,即在遇到错误时程序不会崩溃,我们需要对异常进行处理,
|
||||
|
||||
如果错误发生的条件是可预知的,我们需要用if进行处理:在错误发生之前进行预防
|
||||
|
||||
```python
|
||||
def func(arg):
|
||||
if arg is int:
|
||||
arg += 1
|
||||
else:
|
||||
arg = int(arg)
|
||||
arg += 1
|
||||
return arg
|
||||
```
|
||||
|
||||
**如果错误发生的条件是不可预知的,则需要用到try...except:在错误发生之后进行处理**
|
||||
|
||||
#### 1、基本语法为
|
||||
|
||||
```python
|
||||
try:
|
||||
被检测的代码块
|
||||
except 异常类型 as 异常信息变量名:
|
||||
try中一旦检测到异常,就执行这个位置的逻辑
|
||||
```
|
||||
|
||||
**例子**
|
||||
|
||||
```python
|
||||
def func(arg):
|
||||
try:
|
||||
arg +=1
|
||||
except TypeError as e:
|
||||
print(e)
|
||||
|
||||
func('杨哥')
|
||||
```
|
||||
|
||||
#### 2、使用正确的异常类型
|
||||
|
||||
异常处理,只可以捕获到声明的异常种类和发生异常的种类相匹配的情况。
|
||||
假如发生的异常类型和你指定捕获到异常不能匹配,就无法处理。
|
||||
|
||||
```python
|
||||
x = '杨哥'
|
||||
try:
|
||||
int(x)
|
||||
except IndexError as e: # 未捕获到异常,程序直接报错
|
||||
print(e)
|
||||
```
|
||||
|
||||
#### 3、处理异常的多分支操作
|
||||
|
||||
```python
|
||||
x = '杨哥'
|
||||
try:
|
||||
int(x)
|
||||
except IndexError as e:
|
||||
print(e)
|
||||
except KeyError as e:
|
||||
print(e)
|
||||
except ValueError as e:
|
||||
print(e)
|
||||
```
|
||||
|
||||
#### 4、万能异常 Exception
|
||||
|
||||
```python
|
||||
x = '杨哥'
|
||||
try:
|
||||
int(x)
|
||||
except Exception as e:
|
||||
print(e)
|
||||
```
|
||||
|
||||
#### 5、多分支异常与万能异常结合使用
|
||||
|
||||
假如对于不同种类的异常我们需要定制不同的处理逻辑,那就需要用到多分支了。 也可以在多分支的最后写一个Exception
|
||||
|
||||
```python
|
||||
x = '杨哥'
|
||||
try:
|
||||
x[3]
|
||||
except IndexError as e:
|
||||
print(e)
|
||||
except KeyError as e:
|
||||
print(e)
|
||||
except ValueError as e:
|
||||
print(e)
|
||||
except Exception as e:
|
||||
print(e)
|
||||
```
|
||||
|
||||
#### 6、或者无论出现什么异常,都统一丢弃,或者使用同一段代码逻辑去处理
|
||||
|
||||
所有的异常! 只有一个Exception就足够了,这是不好的做法。
|
||||
|
||||
```python
|
||||
try:
|
||||
print('a'[3])
|
||||
except Exception as e:
|
||||
print(e)
|
||||
```
|
||||
|
||||
#### 7、异常的其他结构
|
||||
|
||||
```python
|
||||
x = '杨哥'
|
||||
try:
|
||||
int(x)
|
||||
except IndexError as e:
|
||||
print(e)
|
||||
except KeyError as e:
|
||||
print(e)
|
||||
except ValueError as e:
|
||||
print(e)
|
||||
else:
|
||||
print('try内代码块没有异常则执行我')
|
||||
finally:
|
||||
print('无论异常与否,都会执行该模块,通常是进行清理工作')
|
||||
|
||||
#如果try中没有异常,那么except部分将跳过,执行else中的语句。(前提是try里没有返回值)
|
||||
#finally是无论是否有异常,最后都要做的一些事情。”(无论try里是否有返回值)
|
||||
```
|
||||
|
||||
#### 8、主动触发异常
|
||||
|
||||
```python
|
||||
try:
|
||||
raise TypeError('类型错误')
|
||||
except Exception as e:
|
||||
print(e)
|
||||
|
||||
helper.py
|
||||
def f1():
|
||||
print('f1')
|
||||
|
||||
index.py
|
||||
import helper
|
||||
if __name__ == '__main__'
|
||||
try:
|
||||
n = '1'
|
||||
n = int(n)
|
||||
ret = helper.f1()
|
||||
if ret:
|
||||
print('成功')
|
||||
else:
|
||||
raise Exception('调用失败')
|
||||
except Exception,e:
|
||||
print('出现错误')
|
||||
print(e)
|
||||
|
||||
```
|
||||
|
||||
### 5、更详细的异常信息输出(生产环境必备)
|
||||
|
||||
python中用于处理异常栈的模块是traceback模块,它提供了print_exception、format_exception等输出异常栈等常用的工具函数
|
||||
|
||||
```python
|
||||
import traceback
|
||||
print('start-->')
|
||||
try:
|
||||
1 + 'a'
|
||||
except TypeError as e:
|
||||
print(e)
|
||||
print('*' * 30)
|
||||
#traceback.print_exc()
|
||||
print(traceback.format_exc())
|
||||
print('*' * 20)
|
||||
print('end')
|
||||
|
||||
# traceback.print_exc()跟traceback.format_exc()有什么区别呢?
|
||||
# format_exc()返回字符串,print_exc()则直接给打印出来。
|
||||
# 即traceback.print_exc()与print traceback.format_exc()效果是一样的。
|
||||
# print_exc()还可以接受file参数直接写入到一个文件。比如
|
||||
# traceback.print_exc(file=open('tb.txt','w+'))
|
||||
# 写入到tb.txt文件去。(实现错误输出到日志的功能)
|
||||
```
|
||||
Loading…
Reference in New Issue
Block a user